利用 Pandas 进行数据处理
一、认识数据处理
为什么要预处理数据?
1、现实世界的数据是“肮脏的”——数据多了,什么问题都会出现
- 不完整的:缺少属性值,缺少感兴趣的属性,或仅包含聚集数据, 如:e.g., Occupation=“”
- 含噪声的:包含错误或者“孤立点”, e.g., Salary=“-10”
- 不一致的:在编码或者命名上存在差异,E.g. Age=“42” Birthday=“03/07/1997” 如:等级代码 前面“1,2,3”, 后面“A, B, C”
2、没有高质量的数据,就没有高质量的挖掘结果
- 高质量的决策必须依赖高质量的数据
为什么数据是肮脏?
1、不完整数据来自:
- 感兴趣的数据难以获得
- 数据收集时与做数据分析时侧重的问题不一致
- 人/硬件/软件问题
2、噪音数据来自数据处理过程:
- 收集–>录入–>传输
3、不一致数据来自:
- 不同数据源
- 数据违背了依赖关系
数据处理的主要任务
1、数据集成
集成多个数据库、数据立方体或文件
2、数据清理
- 填充缺失值
- 识别孤立点,去除噪音
- 修正不一致数据
- 解决由于数据集成造成的数据冗余问题
3、数据规约
得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果,包括维规约和数值规约
4、数据变换
规范化:将数据按比例缩放,使之落入一个小的特定区间
5、数据离散化
离散化:数值属性的原始值用区间标签或概念标签替换,或者标称属性转化为数值属性
二、数据集成
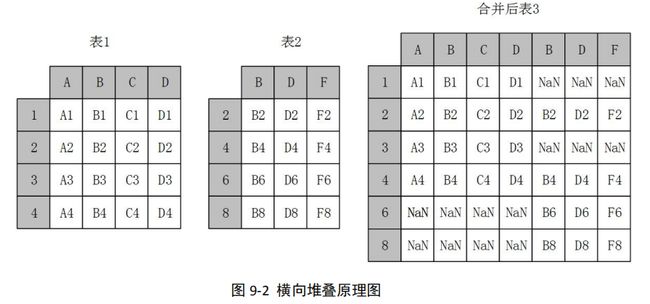
1、横向堆叠-concat
横向堆叠,即将两个表在 X 轴向拼接在一起,可以使用 concat 函数完成,concat 函数 的基本语法如下:
pandas.concat(objs,axis=0,join=‘outer’,join_axes=None,ignore_index=False,keys=None,levels=None, names=None, verify_integrity=False, copy=True)
concat 参数说明表
| 参数名称 | 说明 |
|---|---|
| objs | 接收多个 Series,DataFrame,Panel 的组合,表示参与链接的 pandas 对象的列表 的组合,无默认, axis |
| join | 接收 inner 或 outer。表示其他轴向上的索引是按交集(inner)还是并集(outer) 进行合并,默认为 outer |
| join_axes | 接收 Index 对象,表示用于其他 n-1 条轴的索引,不执行并集/交集运算 |
| ignore_index | 接收 boolean,表示是否不保留连接轴上的索引,产生一组新索引 ignore_index range(total_length),默认为 False |
| keys | 接收 sequence,表示与连接对象有关的值,用于形成连接轴向上的层次化索引,默 keys 认为 None |
| levels | 接收包含多个sequence 的list,表示在指定 keys 参数后,指定用作层次化索引各级别上的索引,默认为 None |
| names | 接收 list,表示在设置了 keys 和 levels 参数后,用于创建分层级别的名称,默认为None |
| verify_integrity | 接收 boolearn,表示是否检查结果对象新轴上的重复情况,如果发现则引发异常,默认为 False |
当 axis=1 的时候,concat 做行对齐,然后将不同列名称的两张或多张表合并,当两个 表索引不完全一样时,可以使用 join 参数选择是内连接还是外连接,在内连接的情况下, 仅仅返回索引重叠部分,在外连接的情况下,则显示索引的并集部分数据,不足的地方则使用空值填补
当两张表完全一样时,不论 join 参数取值是 inner 或者 outer,结果都是将两个表完 全按照 X 轴拼接起来
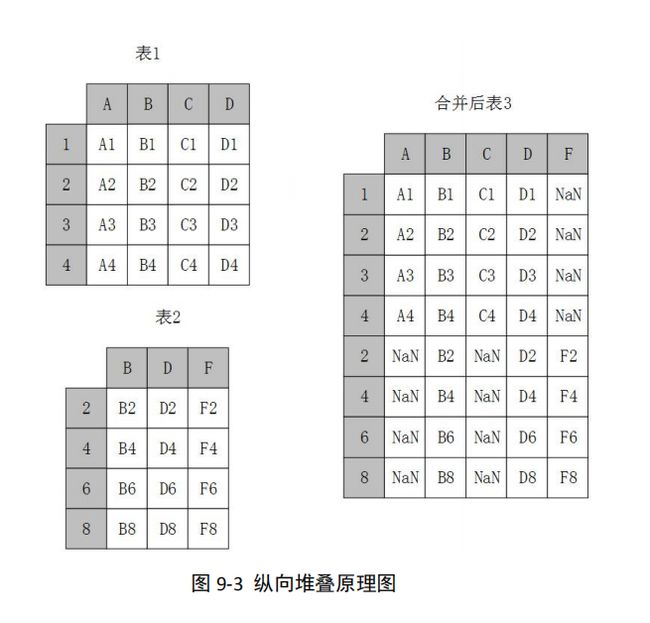
2、纵向堆叠-concat
使用 concat 函数时,在默认情况下,即 axis=0 时,concat 做列对齐,将不同行索引 的两张或多张表纵向合并,在两张表的列名并不完全相同的情况下,可 join 参数取值为 inner 时,返回的仅仅是列名交集所代表的列,取值为 outer 时,返回的是两者列名的并集 所代表的列,其原理示意如图
不论 join 参数取值是 inner 或者 outer,结果都是将两个表完全按照 Y 轴拼接起来
代码实现:
import pandas as pd
# 加载数据
df1 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=0, index_col=0)
print('df1:\n', df1)
df2 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=1, index_col=0)
print('df2:\n', df2)
# 可以是pd.concat来进行横向堆叠
# 当axis=1,join= 'outer'
# 在列的方向直接拼接,在行的方向,拿取所有的行,在没有数据的行的位置用NaN来补齐
res = pd.concat((df1, df2), axis=1, join='outer')
print('res:\n',res)
# 当axis =1 ,join = 'inner'
# 在列的方向上直接拼接,在行的方向,取共同拥有的行
res = pd.concat((df1, df2), axis=1, join='inner')
print('res:\n', res)
# pd.concat来进行纵向堆叠
# 当axis=0, join = 'outer'
# 在行的方向,直接拼接,在列的方向,拿取所有的列,在没有值的列的位置用NaN来补齐
res = pd.concat((df1, df2), axis=0, join='outer', sort=False)
print('res:\n', res)
# 当axis=0,join='inner'
# 在行的方向,直接拼接,在列的方向,拿取共同拥有的列
res = pd.concat((df1, df2), axis=0, join='inner', sort=False)
print('res:\n', res)
3、纵向堆叠-append
append 方法也可以用于纵向合并两张表。但是 append 方法实现纵向表堆叠有一个前提 条件,那就是两张表的列名需要完全一致。append 方法的基本语法如下
pandas.DataFrame.append(self, other, ignore_index=False, verify_integrity=False)
append 参数说明表
| 参数名称 | 说明 |
|---|---|
| other | 接收 DataFrame 或 Series。表示要添加的新数据,无默认 |
| ignore_index | 接收 boolean,如果输入 True,会对新生成的 DataFrame 使用新的索引(自动产 生)而忽略原来数据的索引,默认为 False |
| verify_integrity | 接收 boolean,如果输入 True,那么当 ignore_index 为 False 时,会检查添加的 数据索引是否冲突,如果冲突,则会添加失败,默认为 False |
代码实现:
# 也可以使用append来进行纵向堆叠
df1 = pd.read_excel('./append直接拼接数据.xlsx', sheet_name=0, index_col=0)
print('df1:\n', df1)
df2 = pd.read_excel('./append直接拼接数据.xlsx', sheet_name=1, index_col=0)
print('df2:\n', df2)
# 和 pd.concat 的axis=0,join='outer' 相同,一般情况下,要求在列名相同时使用
res = df1.append(df2, sort=False)
print('res:\n', res)
三、案例:垂钓装备合并案例
近年来,随着人们的生活水平的提高,人们对于精神生活品质的要求越来越高,于是, 各种娱乐活动出现,其中,钓鱼属于一种户外运动,目标是用渔具把鱼从水里钓上来,而且 钓鱼不限制性别与年龄,大人小孩子都喜欢,钓鱼亲近大自然,陶冶情操,然而在钓鱼的时 候,钓鱼装备又影响着钓鱼的成果,所以,越来越多的钓友对于钓鱼装备的要求越来越高, 对于钓鱼装备的需求也越来越多,那么对于钓鱼装备的销售公司来说,了解客户对于不同品牌的钓鱼装备的喜爱程度,对于销售公司来说至关重要
以下为某钓鱼装备公司的销售记录,针对于销售记录,来确定客户最喜爱的品牌或者最火品牌
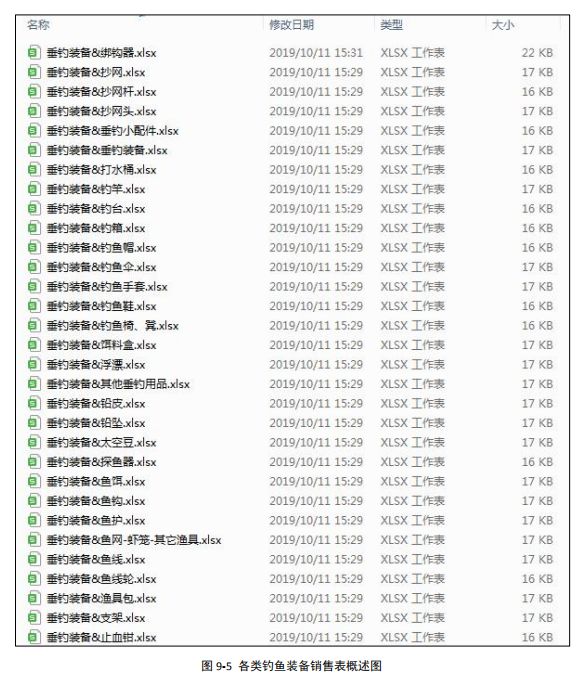
以下为每类钓鱼装备销售记录细表(表结构类似):
钓鱼装备&抄网销售记录细表(部分)
| 日期 | 转化率 | 访客数 | 三级类目 | 客单价 | 品牌 |
|---|---|---|---|---|---|
| 2019-08 | 0.075437 | 448725 | 抄网 | 28.347 | 品牌-7 |
| 2019-08 | 0.066758 | 303676 | 抄网 | 35.92695 | 品牌-1 |
| 2019-08 | 0.029469 | 253084 | 抄网 | 65.60413 | 品牌-5 |
| 2019-08 | 0.032616 | 166098 | 抄网 | 82.162 | 品牌-10 |
| 2019-08 | 0.080396 | 173662 | 抄网 | 31.35206 | 品牌-13 |
钓鱼装备&钓竿销售记录细表(部分)
| 日期 | 转化率 | 访客数 | 三级类目 | 客单价 | 品牌 |
|---|---|---|---|---|---|
| 2019-08 | 0.029797 | 3939046 | 钓竿 | 135.6066 | 品牌-3 |
| 2019-08 | 0.027249 | 1948598 | 钓竿 | 254.9653 | 品牌-19 |
| 2019-08 | 0.031458 | 829839 | 钓竿 | 478.2628 | 品牌-16 |
| 2019-08 | 0.017834 | 938215 | 钓竿 | 670.2237 | 品牌-2 |
| 2019-08 | 0.00864 | 522226 | 钓竿 | 1729.252 | 品牌-18 |
到底如何理解最火品牌?其实可以转化为确定哪个品牌的销售额最高,那么该品牌就是最火的品牌,会发现在各个类别的销售记录细表中,并不存在着销售额特征字段,但是可以通过“销售额=访问数 * 转化率乘于 客单价”来确定销售额
代码实现:
import pandas as pd
import os
import time
# 开始
start = time.time()
# # 以绑钩器 为例,来先研究 不同的品牌 跟销售额之间的关系
#
excel_name = '垂钓装备&绑钩器.xlsx'
# # 加载数据
data = pd.read_excel('./data/' + excel_name)
# print('data:\n', data)
# print('data:\n', data.columns)
# 计算销售额
# 销售额 = 访客数 * 转化率 * 客单价
data.loc[:, '销售额'] = data.loc[:, '访客数'] * data.loc[:, '转化率'] * data.loc[:, '客单价']
print('data:\n', data)
print('data:\n', data.columns)
# 按照品牌进行分组,统计 销售额的 sum
res = pd.pivot_table(data=data,
index='品牌',
values='销售额',
aggfunc='sum').reset_index().sort_values(by='销售额', ascending=False)
# 可以添加行业
res['行业'] = excel_name.split('.')[0]
print('res:\n', res)
# 以整个 垂钓装备 为例
# 获取所有文件名称
file_list = os.listdir('./data/')
print('file_list:\n', file_list)
# 创建一个空的df
res = pd.DataFrame()
# 遍历
for excel_name in file_list:
# print('excel_name:\n', excel_name) # 代表是不同的装备excel
# 对 每一个excel 进行操作
data = pd.read_excel('./data/' + excel_name, sheet_name=0)
# print('data:\n', data)
# print('data:\n', data.columns)
# 计算其 营业额
data.loc[:, '营业额'] = data.loc[:, '访客数'] * data.loc[:, '转化率'] * data.loc[:, '客单价']
# 按照品牌进行分组,统计 营业额的 sum
df = pd.pivot_table(data=data,
index='品牌',
values='营业额',
aggfunc='sum').reset_index()
# 增加行业
df.loc[:, '行业'] = excel_name.split('.')[0]
# print('df:\n', df)
# 合并 --纵向堆叠
# ignore_index=True --->无视原来的行索引,重新生成新的行索引
res = pd.concat((res, df), axis=0, join='outer', ignore_index=True)
# print('res:\n',res)
print('res:\n', res)
# 按照 品牌进行分组, 统计营业额的 sum
res_data = pd.pivot_table(data=res,
index='品牌',
values='营业额',
aggfunc='sum').reset_index().sort_values(by='营业额', ascending=False).head(5)
# 设置pandas的显示
pd.set_option('display.float_format', lambda x: '%.2f' % x)
print('res_data:\n', res_data)
print('总共花费的时间为:\n', time.time() - start)
四、主键合并-megre
主键合并,即通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。,针对同一个主键存在两张包含不同字段的表,将其根据某几个字段一一对应拼接起来,结果 集列数为两个元数据的列数和减去连接键的数量
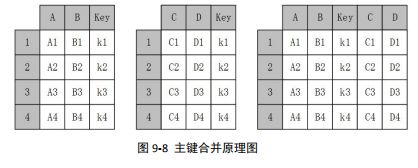
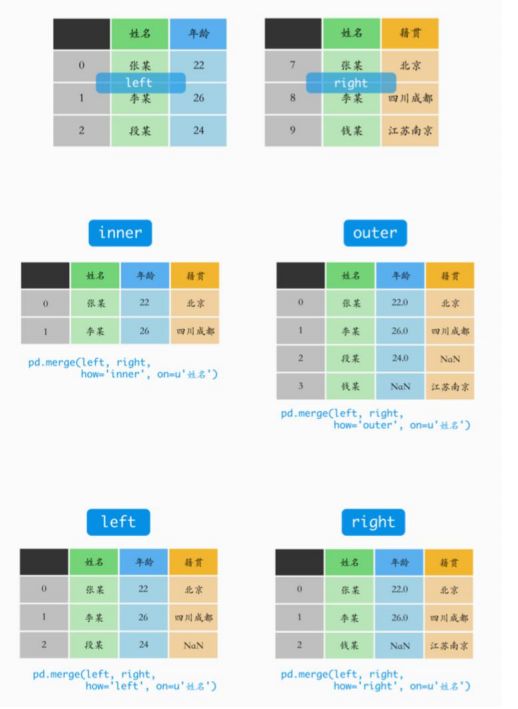
想要进行左右两表的主键合并,可以使用 megre 函数,和数据库的 join 一样,merge 函数也有左连接(left)、右连接(right)、内连接(inner)和外连接(outer),但比起数 据库 SQL 语言中的 join 和 merge 函数还有其自身独到之处,例如可以在合并过程中对数据集中的数据进行排序等
pandas.merge(left,right,how=‘inner’,on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False, suffixes=(’_x’, ‘_y’), copy=True, indicator=False)
可根据 merge 函数中的参数说明,并按照需求修改相关参数,就可以多种方法实现主键合并
merge 参数说明表
| 参数名称 | 说明 |
|---|---|
| left | 接收 DataFrame 或 Series。表示要添加的新数据,无默认 right |
| on | 接收 string 或 sequence,表示两个数据合并的主键(必须一致),默认为 None |
| left_on | 接收 string 或 sequence,表示 left 参数接收数据用于合并的主键,默认为 None |
| right_on | 接收 string 或 sequence。表示 right 参数接收数据用于合并的主键,默认为 None |
| left_index | 接收 boolean,表示是否将 left 参数接收数据的 index 作为连接主键,默认为 False |
| right_index | 接收 boolean,表示是否将 right 参数接收数据的 index 作为连接主键,默认为 False |
| sort | 接收 boolean,表示是否根据连接键对合并后的数据进行排序,默认为 False |
| suffixes | 接收 tuple 表示用于追加到 left 和 right 参数接收数据重叠列名的尾缀默认为 (’_x’, ‘_y’) |
代码实现:
import pandas as pd
# 可以使用 pd.merge 来实现主键连接,类似mysql数据库中的主键连接
# 加载数据
df1 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=0, index_col=0)
print('df1:\n', df1)
df2 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=1, index_col=0)
print('df2:\n', df2)
# 主键合并
# how= inner, 获取 key 列 共同拥有的值进行左右连接
res = pd.merge(left=df1, right=df2, how='inner', on='key')
print('res:\n', res)
# how= outer ,获取key列所有的值进行左右连接,如果没有对应的行,用NaN来补齐
res = pd.merge(left=df1, right=df2, how='outer', on='key')
print('res:\n', res)
# how=left 获取左表中key中的所有的值进行连接,用右表来配合左表,右表中没有的值用NaN来补齐
res = pd.merge(left=df1, right=df2, how='left', on='key')
print('res:\n', res)
# how= right 获取右表中key中所有的值进行连接,用左表来配合右表,左表中没有的值用NaN来补齐
res = pd.merge(left=df1, right=df2, how='right', on='key')
print('res:\n', res)
# 当左表两表中的键名称不相同,但是里面的值大部分相同时的连接
df1 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=2, insheet_namedex_col=0)
print('df1:\n', df1)
#
df2 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=3, index_col=0)
print('df2:\n', df2)
df3 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=4, index_col=0)
print('df3:\n', df3)
# 当how = inner, 使用kx 与ky中共同拥有的值进行连接
res = pd.merge(left=df1, right=df2, how='inner', left_on='Kx', right_on='Ky')
print('res:\n', res)
# 当how = outer 使用kx 与ky中所有的值来进行连接,没有值的位置用NaN来补齐
res = pd.merge(left=df1, right=df2, how='outer', left_on='Kx', right_on='Ky')
print('res:\n', res)
# 当how = left, 使用kx中所有的值来进行连接,右表配合左表,右表中没有值的位置用NaN来补齐
res = pd.merge(left=df1, right=df2, how='left', left_on='Kx', right_on='Ky')
print('res:\n', res)
# # how=right 使用ky中所有的值来进行连接,左表配合右表,左表中没有值的位置用NaN来补齐
res = pd.merge(left=df1, right=df2, how='right', left_on='Kx', right_on='Ky')
print('res:\n', res)
# 当左右两表存在相同名称列,且为非键列,合并之后为了区分,会加上_x,_y来进行区分左右两表的相同名称列
res = pd.merge(left=df1, right=df3, how='right', left_on='Kx', right_on='Ky')
print('res:\n', res)
# 多个主键连接
# 当这多个主键 都相同时,才进行连接
df1 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=5, index_col=0)
print('df1:\n', df1)
df2 = pd.read_excel('./merge主键拼接数据.xlsx', sheet_name=6, index_col=0)
print('df2:\n', df2)
#
res = pd.merge(left=df1, right=df2, on=['kk', 'kg'], how='outer')
print('res:\n', res)
# 还有jion
# df1.join(df2) # --->主键拼接
六、重叠合并
数据分析和处理过程中若出现两份数据的内容几乎一致的情况,但是某些特征在其中一 张表上是完整的,而在另外一张表上的数据则是缺失的时候,可以用 combine_first 方法进行 重叠数据合并,其原理如下
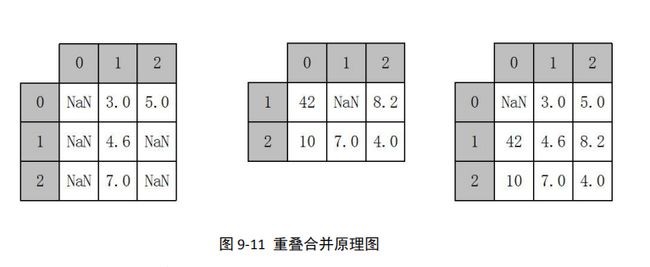
combine_first 的具体用法如下:
pandas.DataFrame.combine_first(other)
combine_first 参数说明表
| 参数名称 | 说明 |
|---|---|
| other | 接收 DataFrame,表示参与重叠合并的另一个 DataFrame,无默认 |
代码实现:
import pandas as pd
# 使用数据表格来填充另外一个数据
# 加载数据
df1 = pd.read_excel('./重叠合并数据.xlsx', sheet_name=0, index_col=0)
print('df1:\n', df1)
df2 = pd.read_excel('./重叠合并数据.xlsx', sheet_name=1, index_col=0)
print('df2:\n', df2)
# 对应位置进行填充,如有存在,并不会覆盖
res = df1.combine_first(df2)
print('填充之后的结果为:\n', res)
七、案例:合并订单、用户数据
将订单详情表、订单信息表、用户信息表进行合并,组成一个完整的数据集,
代码实现:
import pandas as pd
# 加载detail
detail_1 = pd.read_excel('./meal_order_detail.xlsx', sheet_name=0)
detail_2 = pd.read_excel('./meal_order_detail.xlsx', sheet_name=1)
detail_3 = pd.read_excel('./meal_order_detail.xlsx', sheet_name=2)
# 合并detail
detail = pd.concat((detail_1, detail_2, detail_3), axis=0, join='inner')
print('detail:\n', detail)
print('detail:\n', detail.columns)
# 加载info
info = pd.read_csv('./meal_order_info.csv', encoding='ansi')
print('info:\n', info)
print('info:\n', info.columns)
# 加载users
users = pd.read_excel('./users.xlsx', sheet_name=0)
print('users:\n', users)
print('users:\n', users.columns)
# 主键合并
# detail 中 order_id 与info 中 info_id
# detail 中 emp_id 与info 中 emp_id
df = pd.merge(left=detail, right=info, how='inner', left_on=['order_id', 'emp_id'], right_on=['info_id', 'emp_id'])
print('df:\n', df)
print('df:\n', df.shape)
print('df:\n', df.columns)
# 与 users再进行主键合并
# df中的 name 和 users ACCOUNT
df = pd.merge(left=df, right=users, left_on='name', right_on='ACCOUNT', how='inner')
# print('df:\n', df)
# print('df:\n', df.shape)
# print('df:\n', df.columns)
# name,ACCOUNT 相同
# order_id,info_id 相同
df.drop(labels=['ACCOUNT', 'info_id'], axis=1, inplace=True)
# print('df:\n', df)
# print('df:\n', df.shape)
# print('df:\n', df.columns)
# 删除整列为空的数据
drop_list = []
for column in df.columns:
# 判断
if df.loc[:, column].count() == 0:
# 添加
drop_list.append(column)
# 删除整列为空的数据
df.drop(labels=drop_list, axis=1, inplace=True)
# print('df:\n', df)
# print('df:\n', df.shape)
# print('df:\n', df.columns)
drop_list = []
# 删除整列都是一样数据的列
for column in df.columns:
# 去重
res = df.drop_duplicates(subset=column, inplace=False)
# 判断
if res.shape[0] == 1:
drop_list.append(column)
# 删除整列数据重复的列
df.drop(labels=drop_list, axis=1, inplace=True)
print('df:\n', df)
print('df:\n', df.shape)
print('df:\n', df.columns)
八、案例:神奇数字
在 1973 年,统计学家 F.J. Anscombe 造了四组非常神奇的数字,这四组数字具体有多 神奇呢?就是均值、方差、相关性都一样,但是分布却完全不一样
1、加载数据,格式调整
代码实现:
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据
data = pd.read_csv('./anscombe.csv')
print('data:\n', data)
# 拆分
df1 = data.loc[data.loc[:, 'dataset'] == 'I', :].reset_index().drop(labels=['index', 'dataset'], axis=1, inplace=False)
print('df1:\n', df1)
df2 = data.loc[data.loc[:, 'dataset'] == 'II', :].reset_index().drop(labels=['index', 'dataset'], axis=1, inplace=False)
print('df2:\n', df2)
df3 = data.loc[data.loc[:, 'dataset'] == 'III', :].reset_index().drop(labels=['index', 'dataset'], axis=1,
inplace=False)
print('df3:\n', df3)
df4 = data.loc[data.loc[:, 'dataset'] == 'IV', :].reset_index().drop(labels=['index', 'dataset'], axis=1, inplace=False)
print('df4:\n', df4)
print('*' * 100)
# 主键拼接
# left_index=True, right_index=True 主键拼接的时候,以左表的index为外键,以右表的index为外键
df1_2 = pd.merge(left=df1, right=df2, left_index=True, right_index=True, how='inner', suffixes=("_I", "_II"))
print('df1_2:\n', df1_2)
df3_4 = pd.merge(left=df3, right=df4, left_index=True, right_index=True, how='inner', suffixes=("_III", "_IV"))
print('df3_4:\n', df3_4)
print('*' * 100)
all_df = pd.merge(left=df1_2, right=df3_4, left_index=True, right_index=True, how='inner')
print('all_df:\n', all_df)
最后可以得到如下所示的结果数据,这就是四组神奇的数字:
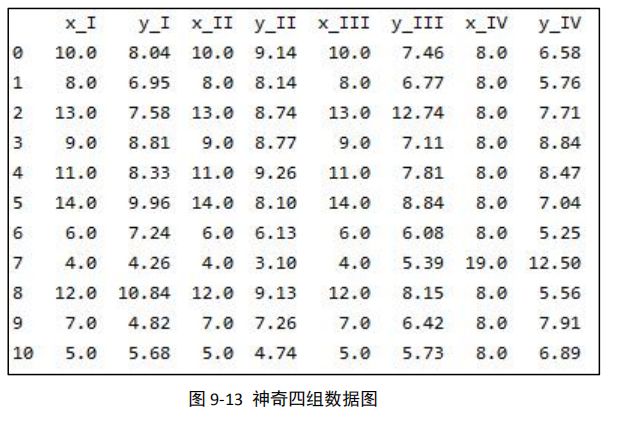
x_I 和 y_I 是一组数据、 x_II 和 y_II 是一组数据, x_III 和 y_III 是一组数据, x_IV 和 y_IV 是一组数据,我们可以看到这四组数据是完全不一样的
2、进行 describe 统计
在数据分析中,我们平常拿到一个表以后,可能会使用 describe 函数去看不同指标的 一个整体情况,那我们这里也用 describe()看一下结果:
代码实现:
# 对all_df进行统计指标
res_describe = all_df.describe()[['x_I', 'x_II', 'x_III', 'x_IV', 'y_I', 'y_II', 'y_III', 'y_IV']]
print('res_describe:\n', res_describe)
可以得到结果:
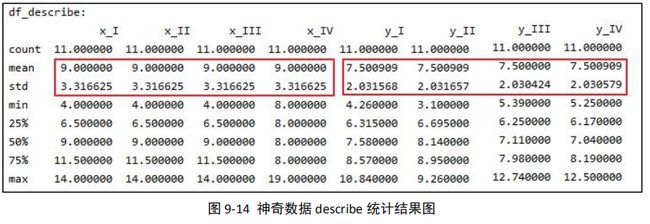
我们可以看到 x_I、x_II、x_III、x_IV 这四个指标的均值和标准差是完全一样的,y_I、 y_II、y_III、y_IV 这四个指标的均值和标准差也是完全一样的(忽略小数点差异),几列完 全不同的值,均值和标准差竟然会完全一样
3、计算两两之间的相关系数
代码实现:
# 两两之间的相关系数
# x 和 y 的相关系数
res_corr = all_df.corr()
print('res_corr:\n', res_corr)
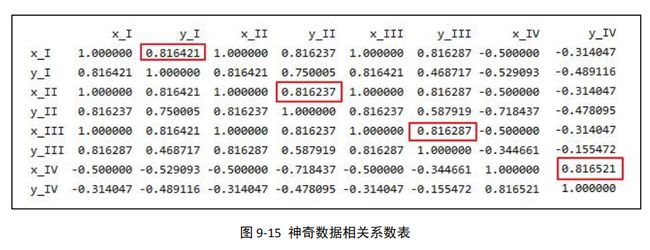
可以得到指标两两之间相关性情况,我们可以看到四组的相关性系数也基本相同(忽略 小数点差异)
4、散点图可视化
代码实现:
# 查看数据分布状态
# 创建画布
fig = plt.figure()
# 默认不支持中文 ---修改RC参数
plt.rcParams['font.sans-serif'] = 'SimHei'
# 增加字体之后变得不支持负号,需要修改RC参数让其继续支持负号
plt.rcParams['axes.unicode_minus'] = False
# 调整间距
plt.subplots_adjust(hspace=0.3)
# 绘图及修饰
fig.add_subplot(2, 2, 1)
# 绘图
plt.scatter(all_df['x_I'], all_df['y_I'])
# 增加标题
plt.title('I型数据')
fig.add_subplot(2, 2, 2)
# 绘图
plt.scatter(all_df['x_II'], all_df['y_II'])
# 增加标题
plt.title('II型数据')
fig.add_subplot(2, 2, 3)
# 绘图
plt.scatter(all_df['x_III'], all_df['y_III'])
# 增加标题
plt.title('III型数据')
fig.add_subplot(2, 2, 4)
# 绘图
plt.scatter(all_df['x_IV'], all_df['y_IV'])
# 增加标题
plt.title('IV型数据')
# 保存图片
plt.savefig('神奇数字.png')
# 展示
plt.show()
可视化结果如下:

看这四组的散点图,是不是完全不一样,这就是最神奇之处
九、数据清洗
1、检测与处理重复值
(1)、记录重复
记录重复,即一个或者多个特征某几个记录的值完全相同
方法一:是利用列表(list)去重,自定义去重函数
代码实现:
def delRep(list1):
list2 = []
for i in list1:
if i not in list2:
list1.append(i)
return list2
方法二:是利用集合(set)的元素是唯一的特性去重,如 dish_set = set(dishes), 比较上述两种方法可以发现,方法一代码冗长,方法二代码简单了许多,但会导致数据的排列发生改变
方法三:pandas提供了一个名为drop_duplicates的去重方法,该方法只对 DataFrame或者 Series 类型有效,这种方法不会改变数据原始排列,并且兼具代码简洁和运行稳定的特点,该方法不仅支持单一特征的数据去重,还能够依据 DataFrame 的其中一个或者几个特征 进行去重操作
pandas.DataFrame(Series).drop_duplicates(self,subset=None, keep=‘first’, inplace=False)
drop_duplicates 参数说明表
| 参数名称 | 说明 |
|---|---|
| subset | 接收 string 或 sequence,表示进行去重的列,默认为 None,表示全部列 |
| keep | 接收特定 string,表示重复时保留第几个数据,First:保留第一个,Last:保留最后 一个,alse:只要有重复都不保留,默认为 first |
| inplace | 接收 boolean。表示是否在原表上进行操作。默认为 False |
代码实现:
# drop_duplicates
# subset : 指的是df所按照指定列来进行去重
# keep="first":默认保留第一次出现的
# inplace : 如果为True,直接修改原df,如果为False,对原df无影响,会返回一个新的修改的df
data.drop_duplicates(subset='订单ID', inplace=True)
print('去重之后的结果为:\n', data.shape)
(2)、特征重复
结合相关的数学和统计学知识,去除连续型特征重复可以利用特征间的相似度将两个相 似度为 1 的特征去除一个。在 pandas 中相似度的计算方法为 corr,使用该方法计算相似度 时,默认为“pearson”法 ,可以通过“method”参数调节,目前还支持“spearman”法 和“kendall”法
但是通过相似度矩阵去重存在一个弊端,该方法只能对数值型重复特征去重,类别型特 征之间无法通过计算相似系数来衡量相似度
相关性理解

代码实现:
import pandas as pd
# 去重 ---记录,单列的值全部一样、大部分一样
# 1、自定义函数
# 2、set --->无序的
# 3、drop_duplicates ---去重
# ndaarry --np.unique
# 属性重复
# 判定两列是否重复
# bool数组判断 ---如果两列完全一样
# 如果量列数据大部分一样、大部分关系特别近 --->这两列数据基本一样
# 如何判断两两列之间的关系?---相关度(相关性系数) ---corr()
# 加载数据
detail = pd.read_excel('./meal_order_detail.xlsx', sheet_name=0)
print('detail:\n',detail)
print('detail:\n',detail.columns)
# 计算amounts 与 counts的 相关性系数
# 默认 为 pearson相关系数
# method 默认为 pearson相关系数,还是 “spearman”法 和“kendall”法。
res = detail.loc[:,['amounts','counts']].corr()
print('res:\n',res)
# 要求:数据为数值型才可以计算
res = detail.loc[:,['amounts','counts','detail_id','order_id']].corr()
print('res:\n',res)
# 如果两两列之间的相关性系数 > 0.95 可以认为这两列基本相同,可以删除其中一列
2、检测与处理缺失值
(1)、检测缺失值
利用 isnull 或 notnull 找到缺失值 数据中的某个或某些特征的值是不完整的,这些值称为缺失值
pandas 提供了识别缺失值的方法 isnull 以及识别非缺失值的方法 notnull,这两种方 法在使用时返回的都是布尔值 True 和 False
结合 sum 函数和 isnull、notnull 函数,可以检测数据中缺失值的分布以及数据中一共 含有多少缺失值
isnull 和 notnull 之间结果正好相反,因此使用其中任意一个都可以判断出数据中缺 失值的位置
代码实现:
import pandas as pd
# 加载数据
data = pd.read_excel('./qs.xlsx')
print('data:\n', data)
# 缺失值检测
# pd.isnull ,如果为缺失,则为True,如果有值,则为False,一般和sum连用 ---推荐
# pd.notnull ,如果为缺失,则为False,如果有值,则为True,
print('缺失值检测:\n', pd.isnull(data).sum())
print('缺失值检测:\n', pd.notnull(data).sum()) # 和 count 的结果一致,非空数据的数量
# 对于 * : ' ' ! ? 等特殊字符的缺失值无法检测,但是如果后续会进行计算,直接报错
(2)、处理缺失值
删除法:
删除法分为删除观测记录和删除特征两种,它属于利用减少样本量来换取信息完整度的 一种方法,是一种最简单的缺失值处理方法
Pandas 中提供了简便的删除缺失值的方法 dropna,该方法既可以删除观测记录,亦可 以删除特征
pandas.DataFrame.dropna(self, axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
dropna 参数说明表
| 参数名称 | 说明 |
|---|---|
| axis | 接收 0 或 1表示轴向,0 为删除观测记录(行),1 为删除特征(列),默认为 0 |
| how | 接收特定 string,表示删除的形式,any 表示只要有缺失值存在就执行删除操作,all 表示当且仅当全部为缺失值时执行删除操作,默认为 any |
| subset | 接收类 array 数据,表示进行去重的列∕行,默认为 None,表示所有列/行 |
| inplace | 接收 boolean,表示是否在原表上进行操作,默认为 False |
代码实现:
import pandas as pd
# 加载数据
data = pd.read_excel('./qs.xlsx')
print('data:\n', data)
print('*' * 100)
# 1、删除法
# 删除缺失值 ---dropna
# axis: 指定删除的方向,当axis=0时,删除含有缺失值的行,当axis=1时,删除含有缺失值的列
# how ='all', 整行、整列全部为缺失值时,才进行删除
data.dropna(axis=0, how='all', inplace=True)
# how='any' 只要有缺失值就进行删除
data.dropna(axis=0, how='any', inplace=True)
data.dropna(axis=1, how='any', inplace=True)
print('删除缺失值的结果:\n', data)
# 使用删除法可能会造成数据的大量丢失,在整行、整列全部为缺失或者整行、整列大部分为缺失的情况下使用
替换法:
替换法是指用一个特定的值替换缺失值,特征可分为数值型和类别型,两者出现缺失值时的处理方法也是不同的
缺失值所在特征为数值型时,通常利用其均值、中位数和众数等描述其集中趋势的统计量来代替缺失值
缺失值所在特征为类别型时,则选择使用众数来替换缺失值
Pandas 库中提供了缺失值替换的方法名为 fillna,其基本语法如下: pandas.DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
fillna 参数说明表
| 参数名称 | 说明 |
|---|---|
| value | 接收 scalar,dict,Series 或者 DataFrame,表示用来替换缺失值的值,无默认 |
| method | 接收特定 string,backfill 或 bfill 表示使用下一个非缺失值填补缺失值,pad 或 ffill 表 示使用上一个非缺失值填补缺失值,默认为 None |
| axis | 接收 0 或 1。表示轴向,默认为 1 |
| inplace | 接收 boolean,表示是否在原表上进行操作,默认为 False |
| limit | 接收 int,表示填补缺失值个数上限,超过则不进行填补,默认为 None |
代码实现:
# 2、填充法
# 替换法 ---使用特定的指标来替换缺失值
# fillna --->可以均值、中位数、众数、上邻居(缺失值位置上一个非空元素)、下邻居(缺失值位置上下一个非空元素)来进行填充
# 使用填充法来填充 商品ID ---mode
# 计算众数
mode = data.loc[:, '商品ID'].mode()[0]
# 填充
# value --->替换缺失值的指标
# inplace ---是否对原df产生影响
# limit ---->指定替换的次数,如果不填写,那么表示替换整列的缺失值
data.loc[:, '商品ID'].fillna(value=mode, inplace=True)
# 使用上下邻居来填充 门店编号
# method --表示使用的上邻居还是下邻居,如果为backfill,bfill则为下一个非空邻居,pad,ffill表示上一个非空邻居
data.loc[:, '门店编号'].fillna(method='pad', inplace=True)
print('填充之后的结果为:\n', data)
# 有可能导致数据的分布规律发生变化
# 填充的值 是假的,是自己认为最合适的值(在金融领域,一旦出现缺失值,直接删除)
插值法:
删除法简单易行,但是会引起数据结构变动,样本减少;替换法使用难度较低,但是会影响数据的标准差,导致信息量变动,在面对数据缺失问题时,除了这两种方法之外,还有 一种常用的方法—插值法
常用的插值法有线性插值、多项式插值和样条插值等:
线性插值是一种较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方 程得到缺失值
多项式插值是利用已知的值拟合一个多项式,使得现有的数据满足这个多项式,再利用 这个多项式求解缺失值,常见的多项式插值法有拉格朗日插值和牛顿插值等
样条插值是以可变样条来作出一条经过一系列点的光滑曲线的插值方法,插值样条由一 些多项式组成,每一个多项式都是由相邻两个数据点决定,这样可以保证两个相邻多项式及 其导数在连接处连续
从拟合结果可以看出多项式插值和样条插值在两种情况下拟合都非常出色,线性插值法 只在自变量和因变量为线性关系的情况下拟合才较为出色
而在实际分析过程中,自变量与因变量的关系是线性的情况非常少见,所以在大多数情况下,多项式插值和样条插值是较为合适的选择
SciPy 库中的 interpolate 模块除了提供常规的插值法外,还提供了例如在图形学领域 具有重要作用的重心坐标插值(BarycentricInterpolator)等,在实际应用中,需要根据 不同的场景,选择合适的插值方法
插值原理代码:
# 3、插值法
# # 根据数据规律来进行插值
# # 线性插值 ----拟合直线关系
# # 多项式插值 ----拟合多项式(拉格朗日多项式)
# # 样条插值 -----拟合曲线样条关系
# # 插值原理
from scipy.interpolate import interp1d # 线性插值模块,也可以作为样条插值
from scipy.interpolate import lagrange # 拉格朗日插值模块
#
# # 创建数据
x = np.array([1, 2, 3, 4, 5, 8, 9])
y = np.array([3, 5, 7, 9, 11, 17, 19]) # y = 2*x +1
z = np.array([2, 8, 18, 32, 50, 128, 162]) # z = 2*x^2
#
# # 使用插值模块 用x来拟合y 用x来拟合z
# # 线性插值
# # 参数1: 基准数组,拟合数组
# # 参数2: 被拟合数据
line1 = interp1d(x, y, kind='linear')
line2 = interp1d(x, z, kind='linear')
#
print('使用x来拟合y的结果为:', line1([6, 7])) # [13. 15.]
print('使用x来拟合z的结果为:', line2([6, 7])) # [ 76. 102.]
#
# # 拉格朗日插值
# # 拟合拉格朗日多项式
# # 参数1:基准数组,拟合数组
# # 参数2:被拟合数据
la1 = lagrange(x, y)
la2 = lagrange(x, z)
#
print('使用x来拟合y的结果为:', la1([6, 7])) # [13. 15.]
print('使用x来拟合z的结果为:', la2([6, 7])) # [72. 98.]
#
# # 样条曲线插值
sp1 = interp1d(x, y, kind='cubic')
sp2 = interp1d(x, z, kind='cubic')
#
print('使用x来拟合y的结果为:', sp1([6, 7])) # [13. 15.]
print('使用x来拟合z的结果为:', sp2([6, 7])) # [72. 98.]
拉格朗日插值代码:
# 在插值过程,如果数据为线性关系,那么线性插值、多项式插值、样条插值效果都不错
# 如果数据关系为非线性关系,那么线性插值就不太适合了,效果较差
# 多项式插值、样条插值对于非线性数据---效果依然不错
# 使用插值法来填充 类别ID
# 确定 使用缺失值位置的前5个和后5个元素来进行插值
n = 5
# 遍历要插值的数据列
for i in range(data.shape[0]):
# print(data.iloc[i, 1]) # 类别ID这一列所有的元素
# 判断 缺失值的位置
if pd.isnull(data.iloc[i, 1]):
print('i:\n', i) # 此时这个i --->缺失值的行下标
# 获取前、后n个元素
if i - n <= 0:
start = 0
else:
start = i - n
end = i + n + 1
# 获取前后n各元素
mask = data.iloc[start:end, 1]
print('mask:\n', mask)
# 构建被拟合数据
y = mask[mask.notnull()].values
# 构建基准数组、拟合数据
x = mask[mask.notnull()].index
print('x:\n', x)
print('y :\n', y)
# 构建拉格朗日多项式
la = lagrange(x, y)
# 调用
data.iloc[i, 1] = la([i])
print('查看填充之后的结果为:\n', data)
特殊字符缺失值:
在数据中有时还存在着特殊字符的缺失值,如:
" * ", " ? ", " : ", " - "等特殊字符
针对这样的缺失值,首先先要利用 replace 函数替换为能处理的缺失值,如:np.nan 类型, 再进行删除、填充、插值等处理
代码实现:
# 对于 * : ' ' ! ? 等特殊字符的缺失值无法检测,但是如果后续会进行计算,直接报错。
# # 1、替换
data.replace('*', np.nan, inplace=True)
print('data:\n', data)
# 2、处理
# 删除、填充、插值中抉择使用对应的缺失值处理方式
# 填充
mode = data.loc[:, '商品ID'].mode()[0]
data.loc[:, '商品ID'].fillna(value=mode, inplace=True)
print('最终的data:\n', data)