朴素贝叶斯算法
文章目录
-
-
-
- 一、贝叶斯认识
- 二、概率
- 三、朴素贝叶斯算法 API
- 四、案例:书籍订单评价信息分类
- 五、朴素贝叶斯算法特点
- 六、文本特征提取
-
-
一、贝叶斯认识
如果你对贝叶斯很陌生,但是你一定会每天都接触输入法快速匹配这样的功能或软件, 比如你输入几个中文字符机器就会识别出你还没输入但是最可能输入的其他字符,能够快速 帮你输入你想输入的东西,表现出的状态就是机器很懂你。搜索引擎中模糊查询的关键词的 快速识别,可以在下拉栏中预测出你想输入的完整答案甚至比你还懂你自己的答案都是贝叶斯算法的功劳。其他类型的还包括大部分跟简单模式识别相关的应用都是跟贝叶斯算法有关的
贝叶斯定理用 Thomas Bayes 的名字命名。Thomas Bayes 是一位不墨守成规的英国牧师, 是 18 世纪概率论和决策论的早期研究者。贝叶斯学派很古老,但是从诞生到一百年前一直 不是主流。主流是频率学派。频率学派的权威皮尔逊和费歇尔都对贝叶斯学派不屑一顾,但 是贝叶斯学派硬是凭借在现代特定领域的出色应用表现为自己赢得了半壁江山
朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独立假设的分类方法,它 通过特征计算分类的概率,选取概率大的情况,是基于概率论的一种机器学习分类(监督学 习)方法,被广泛应用于情感分类领域的分类器
二、概率
1、基于概率论的方法
通过概率来衡量事件发生的可能性。概率论和统计学是两个相反的概念,统计学是抽取 部分样本统计来估算总体情况,而概率论是通过总体情况来估计单个事件或部分事情的发生 情况。概率论需要已知数据去预测未知的事件
例如,我们看到天气乌云密布,电闪雷鸣并阵阵狂风,在这样的天气特征( F )下,我 们推断下雨的概率比不下雨的概率大,也就是 P (下雨)> P (不下雨),所以认为待会儿会下 雨,这个从经验上看对概率进行判断。而气象局通过多年长期积累的数据,经过计算,今天 下雨的概率 P (下雨)=85%、 P (不下雨)=15%,同样的 P (下雨)> P (不下雨),因此今天的 天气预报肯定预报下雨。这是通过一定的方法计算概率从而对下雨事件进行判断
2、条件概率
若Ω是全集, A 、B 是其中的事件(子集),P 表示事件发生的概率,则条件概率表示 某个事件发生时另一个事件发生的概率。假设事件 B 发生后事件 A 发生的概率为:

3、全概率

全概率公式主要用途在于它可以将一个复杂的概率计算问题,分解为若干个简单事件的 概率计算问题,最后应用概率的可加性求出最终结果
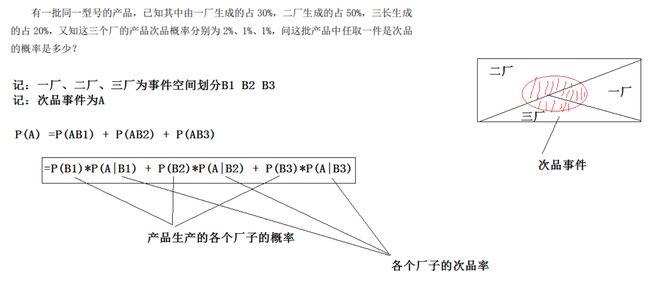
4、贝叶斯公式

意义:现在已知时间 A 确实已经发生,若要估计它是由原因 Bi 所导致的概率,则可用 Bayes 公式求出
三、朴素贝叶斯算法 API
scikit-learn 机器学习包提供了 3 个朴素贝叶斯分类算法
1、高斯朴素贝叶斯
调用方法为:sklearn.naive_bayes.GaussianNB(priors=None)
下面随机生成六个坐标点,其中 x 坐标和 y 坐标同为正数时对应类标为 2,x 坐标和 y 坐标同为负数时对应类标为 1
2、多项式朴素贝叶斯
调用方法为:sklearn.naive_bayes.MultinomialNB(alpha=1.0,fit_prior=True, class_prior=None)
主要用于离散特征分类,例如文本分类单词统计,以出现的次数作为特征值
表 xx MultinomialNB 参数说明
| 参数名称 | 说明 |
|---|---|
| alpha | 可选,默认为 1.0,添加拉普拉修/Lidstone 平滑参数 |
| fit_prior | 默认为 True,表示是否学习先验概率,参数为 False 表示所有类标记具有相同的先验概率; |
| class_prior | 接收数组,数组大小为(n_classes,),默认 None, 类先验概率 |
3、伯努利朴素贝叶斯
调用方法为:sklearn.naive_bayes.BernoulliNB(alpha=1.0,binarize=0.0,fit_prior=True,class _prior=None)
类似于多项式朴素贝叶斯,也主要用于离散特征分类
和 MultinomialNB 的区别是:
MultinomialNB 以出现的次数为特征值,BernoulliNB 为二进制或布尔型特性。
下面是朴素贝叶斯算法常见的属性和方法
| 参数名称 | 说明 |
|---|---|
| class_prior | 观察各类标记对应的先验概率,主要是 class_prior_属性,返回数组 |
| class_count | 获取各类标记对应的训练样本数 |
| theta | 获取各个类标记在各个特征上的均值 |
| sigma | 获取各个类标记在各个特征上的方差 |
| fit(X, y, sample_weight=None) | 训练样本,X 表示特征向量,y 类标记,sample_weight 表各样本权重数组 |
| partial_fit(X, y, classes=None, sample_weight=None) | 增量式训练,当训练数据集数据量非常大,不能一次性全部载入内存时,可以将数据集 划分若干份,重复调用 partial_fit 在线学习模型参数,在第一次调用 partial_fit 函数时, 必须制定 classes 参数,在随后的调用可以忽略 |
四、案例:书籍订单评价信息分类
1、中文文本数据集预处理
假设现在需要判断一封邮件是不是垃圾邮件,其步骤如下:
数据集拆分成单词,中文分词技术;
计算句子中总共多少单词,确定词向量大小;
句子中的单词转换成向量,BagofWordsVec;
计算 P(Ci),P(Ci|w)=P(w|Ci)P(Ci)/P(w),表示 w 特征出现时,该样本被分为 Ci 类的 条件概率;
判断 P(w[i]C[0])和 P(w[i]C[1])概率大小,两个集合中概率高的为分类类标
2、数据集读取
假设存在如下所示 Python 书籍订单评价信息,每条评价信息对应一个结果(好评和差 评),如下表所示:
表 xx Pythn 书籍订单评价信息表
| 内容 | 评价 |
|---|---|
| 从编程小白的角度看,入门极佳。 | 好评 |
| 很好的入门书,简洁全面,适合小白。 | 好评 |
| 讲解全面,许多小细节都有顾及,三个小项目受益匪浅。 | 好评 |
| 前半部分讲概念深入浅出,要言不烦,很赞 | 好评 |
| 看了一遍还是不会写,有个概念而已 | 差评 |
| 中规中矩的教科书,零基础的看了依旧看不懂 | 差评 |
| 内容太浅显,个人认为不适合有其它语言编程基础的人 | 差评 |
| 破书一本 | 差评 |
| 适合完完全全的小白读,有其他语言经验的可以去看别的书 | 差评 |
| 基础知识写的挺好的! | 好评 |
| 太基础 | 差评 |
| 略啰嗦。。适合完全没有编程经验的小白 | 差评 |
| 真的真的不建议买 | 差评 |
代码实现:
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
import jieba
import numpy as np
from sklearn.naive_bayes import MultinomialNB
def build_data():
"""
加载数据
:return: data
"""
data = pd.read_csv('./data.csv', encoding='ansi')
return data
def deal_data(data):
"""
数据处理
:param data: 需要处理的数据
:return: train, test
"""
# 构建一个列表
seg_list = []
# 对 文本类型得 特征 进行分词 --精确模式
for tmp in data.loc[:, '内容 ']:
# print(tmp) # 每一个样本的文本特征值
seg = jieba.cut(tmp, cut_all=False)
# 拼接 合并
seg_str = ','.join(seg)
# 加入到 seg_list
seg_list.append(seg_str)
# print('seg_list:\n', seg_list)
# 加载停止词文件,并处理停止词
with open('./stopwords.txt', 'r', encoding='utf-8') as fp:
# 读取内容
st_words = fp.readlines()
# print('st_words:\n', st_words)
# 剔除 停止词两侧的 空白字符
st_words = [words.strip() for words in st_words]
# 剔除重复的 停止词
st_words = list(set(st_words))
# print('st_words:\n', st_words)
# '一本'、'一遍' '三个' 也不重要
st_words.extend(['一本', '一遍', '三个'])
# 将 非数值型的 特征、目标 转化为 数值型的 特征、目标
# 统计词数 --将文本特征转化为 数值特征
# 实例化对象
conv = CountVectorizer(stop_words=st_words)
# 统计词数
x = conv.fit_transform(seg_list)
# 获取统计词语
feature_name = conv.get_feature_names()
print('feature_name:\n', feature_name)
# 转化为 ndarray
x = x.toarray()
# print('x:\n', x)
# print('x:\n', x.dtype)
# 将目标值转化为 数值类型
data.loc[data.loc[:, '评价'] == '好评', '评价'] = 0
data.loc[data.loc[:, '评价'] == '差评', '评价'] = 1
# print(data.loc[:,'评价'])
# print(data.loc[:,'评价'].dtypes)
# 修改 评价 类型
y = data.loc[:, '评价'].astype(np.int64).values.reshape((-1, 1))
# print('y:\n', y)
# 合并特征 与目标值
data = np.concatenate((x, y), axis=1)
# print('data:\n', data)
# 拆分为 训练集 + 测试集
train = data[:10, :]
test = data[10:, :]
return train, test
def main():
"""
主函数
:return:
"""
# 1、加载数据
data = build_data()
print('data:\n', data)
# 2、数据处理
train, test = deal_data(data)
print('train:\n', train)
print('test:\n', test)
# 3、分类预测
# 实例化算法对象
nb = MultinomialNB()
# 训练数据并构建模型
nb.fit(train[:, :-1], train[:, -1])
# 预测
y_predict = nb.predict(test[:, :-1])
# 获取准确率
score = nb.score(test[:, :-1], test[:, -1])
print('预测值:\n', y_predict)
print('准确率:\n', score)
if __name__ == '__main__':
main()
五、朴素贝叶斯算法特点
朴素贝叶斯算法的优缺点:
(1)监督学习,需要确定分类的目标 ;
(2)对缺失数据不敏感,在数据较少的情况下依然可以使用该方法;
(3)可以处理多个类别 的分类问题;
(4)适用于标称型数据 ;
(5)对输入数据的形势比较敏感;
(6)由于用先验数据去预测分类,因此存在误差
六、文本特征提取
文本特征抽取的第一步通常是进行分词,分词后会进行向量化的操作。在介绍向量化之 前,我们先来了解下词袋模型
词袋模型(Bag of words,简称 BoW )
词袋模型假设我们不考虑文本中词与词之间的上下文关系,仅仅只考虑所有词的权重。 而权重与词在文本中出现的频率有关
词袋模型首先会进行分词,在分词之后,通过统计每个词在文本中出现的次数,我们就 可以得到该文本基于词的特征,如果将各个文本样本的这些词与对应的词频放在一起,就是 我们常说的向量化。向量化完毕后一般也会使用 TF-IDF 进行特征的权重修正,再将特征进 行标准化。再进行一些其他的特征工程后,就可以将数据带入机器学习模型中计算
词袋模型的三部曲:
(1)分词(tokenizing)
(2)统计修订词特征值(counting)
(3)标准化(normalizing)
词袋模型有很大的局限性,因为它仅仅考虑了词频,没有考虑上下文的关系,因此会丢 失一部分文本的语义
在词袋模型统计词频的时候,可以使用 sklearn 中的 CountVectorizer 来完成
a、词频向量化
CountVectorizer 类会将文本中的词语转换为词频矩阵(sparse),例如矩阵中包含一个 元素 a[i][j],它表示 j 词在 i 类文本下的词频
它通过 fit_transform 函数计算各个词语出现的次数
通过 get_feature_names()可获取词袋中所有文本的关键字
通过 toarray()可看到词频矩阵的结果
官方文件中提到其参数很多默认值就很好,无需再改动
代码实现:
from sklearn.feature_extraction.text import CountVectorizer # 统计词数模块
#
content = ['The river flows eastward, and the stars in the sky join the Big Dipper',
'i y Can you stop wandering in your eyes like this',
'The bright moon in front of the window',
'Sunset, heartbroken man in the end of the world']
# 1、实例化对象
# 注意:统计词数的时候,认为单个长度的字符串不重要的,所以不统计
# stop_words:停止词,可以人为的指定来剔除自己认为不重要的词
# min_df: 1 --->统计的词至少在1篇文章中出现,才给与统计
conv = CountVectorizer(stop_words=['river', 'flows', 'eastward'], min_df=1)
# 2、统计词频
x = conv.fit_transform(content)
# 获取统计的词语
feature_names = conv.get_feature_names()
print('feature_names:\n', feature_names)
# print('x:\n', x)
# print('x:\n', type(x)) # sparse矩阵
# 转化为数组
print(x.toarray())
b、TF-IDF 处理
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于资讯检索与文本 挖掘的常用加权技术。TF-IDF 是一种统计方法,用以评估一个字词对于一个文件集或一个 语料库中的其中一份文件的重要程度,字词的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降。TF-IDF 加权的各种形式常被搜索引擎 应用,作为文件与用户查询之间相关程度的度量或评级
TF-IDF 的主要思想是:如果某个词或短语在一篇文章中出现的频率 TF 高,并且在其他 文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF 实际上是:TF * IDF
词频(Term Frequency,TF):
指的是某一个给定的词语在该文件中出现的频率。即词 w 在文档 d 中出现的次 count(w, d)和文档 d 中总词数 size(d)的比值
tf(w,d) = count(w, d) / size(d)
这个数字是对词数 (term count) 的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否)
逆向文件频率(Inverse Document Frequency,IDF):
是一个词语普遍重要性的度量。某一特定词语的 IDF,可以由总文件数目除以包含该词 语之文件的数目,再将得到的商取对数得到。即文档总数 n 与词 w 所出现文件数 docs(w, D) 比值的对数
idf = log(n / docs(w, D))
TF-IDF根据 tf 和 idf 为每一个文档 d 和由关键词 w[1]…w[k]组成的查询串 q 计算一 个权值,用于表示查询串 q 与文档 d 的匹配度:
tf-idf(q, d) = sum { i = 1…k | tf-idf(w[i], d) } = sum { i = 1…k | tf(w[i], d) * idf(w[i]) }
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生 出高权重的 TF-IDF。因此,TF-IDF 倾向于过滤掉常见的词语,保留重要的词语。
用 sklearn 进行 TF-IDF 预处理:
第一种方法是在用 CountVectorizer 类向量化之后再调用 TfidfTransformer 类进行预处理
代码实现:
from sklearn.feature_extraction.text import TfidfVectorizer # 词的重要性程度
content = ['The river flows eastward, and the stars in the sky join the Big Dipper',
'i y Can you stop wandering in your eyes like this',
'The bright moon in front of the window',
'Sunset, heartbroken man in the end of the world']
# 1、实例化对象
# stop_words 停止词
# min_df
# 不统计单个长度的字符
tfidf = TfidfVectorizer()
# 2、统计词语的重要性程度
x = tfidf.fit_transform(content)
# 获取统计的词语
feature_names = tfidf.get_feature_names()
print('feature_names:\n', feature_names)
# print('x:\n', x) # sparse矩阵
print('x:\n', x.toarray())
# 计算词的 tfidf指标
# tdidf = tf * idf
# tf:
# 指的是某一个给定的词语在该文件中出现的频率。
# 即词 w 在文档 d 中出现的次 count(w, d)和文档 d 中总词数 size(d)的比值。
# tf(w,d) = count(w, d) / size(d)
# 这个数字是对词数 (term count) 的归一化,以防止它偏向长的文件。(同一个词语在
# 长文件里可能会比短文件有更高的词数,而不管该词语重要与否)
# 以 and 为例: tf_and = 1/14
# idf:
# 是一个词语普遍重要性的度量。
# 某一特定词语的 IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。
# 即文档总数 n 与词 w 所出现文件数 docs(w, D) 比值的对数。
# idf = log(n / docs(w, D))
# 以 and 为例 : idf_and = log(4/1)
# 计算 tfidf_and = tf_and * idf_and = 1/14 * log4 = 1/7 = 0.1429
# 真实案例中,计算,会加上权重
注意: 我们在将文本特征转化为数值型的时候,发现一个问题?如果文本为中文文本,该如何 转化呢?
其实我们对于中文,用到了一个分词工具:jieba 分词
jieba 是一个强大的分词库,完美支持中文分词,是目前最好的 Python 中文分词组件
安装:pip install jieba
特点:支持三种分词模式
精确模式,全模式,搜索引擎模式
代码实现:
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import jieba
content = ['我爱北京天安门,我爱中国共产党',
'今天的天气像女朋友的脾气说变就变',
'女朋友生病提醒她多喝烫水',
'问世间情为何物,直教人生死相许']
# 引入jieba分词库
# 安装 :pip install jieba
seg_list = []
# 使用 jieba 对 content 进行精确模式分词
for tmp in content:
# cut_all=False 精确模式
seg = jieba.cut(tmp, cut_all=False)
print('seg:\n', seg)
# 使用join 来进行拼接
seg_str = ','.join(seg)
print('seg_str:\n', seg_str)
seg_list.append(seg_str)
print('seg_list:\n', seg_list)
# 统计词数
# # 1、实例化对象
# conv = CountVectorizer()
# # 2、统计词数
# x = conv.fit_transform(seg_list)
# # 获取统计的词语
# feature_names = conv.get_feature_names()
#
# print('feature_names:\n', feature_names)
# print('x:\n', x.toarray())
# 统计词的重要性程度
# 1、实例化对象
tfidf = TfidfVectorizer()
# 2、统计词的重要性
x = tfidf.fit_transform(seg_list)
# 获取统计的词语
feature_names = tfidf.get_feature_names()
print('feature_names:\n', feature_names)
print('x:\n', x.toarray())