适合小白的深度神经网络DNN思想及详细推导
导读:网上关于深度神经网络的博文和技术博客数不胜数,但是能够让初学者直接看懂的却是不多,倒不是说别人写的不好而是因为这些大佬大多是站在一定的高度来介绍的,不懂我们这些小白的痛苦啊,以下的内容是我在看了吴恩达老师的教程加以总结之后的文章,想要学习深度学习需要有一点数学功底,当然这不是最重要的,如果你在学习的过程中发现有些知识不懂可以现场查询一下,无需针对DNN特意去报班学习数学,我觉得这是没必要的,真正的学习应该是以目标为导向的扩展式学习,能够帮你快速建立必要的知识储备,我会用尽量简明的言语来介绍,希望能够帮助初学者快速理解和掌握深度神经网络。
博客内容主要参考如下,有兴趣的同学可以看一下:
1.深度神经网络BP算法
2.DNN深度神经网络入门
3.DNN反向传播过程推导
4.矩阵、向量的求导公式
一、DNN是什么?
一句话来简单介绍DNN就是:拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果的计算模型。如果你想了解更多关于DNN的信息,可以去网上查一下关于DNN的博客,这些内容可以帮你快速建立对深度神经网络的知识,而不需要花费大量时间去看论文。当然这不是我们文章的主要目的,我要介绍的主要是DNN的网络结构,前向算法和反向传播(Back Propagation 即BP)算法思想和详细的推导过程。
二、标准的DNN网络结构

这里我将以逻辑回归算法(LR)的思想为例将其用在DNN中,将上图中的某一个隐藏层的神经元放大,看看这里的一个隐层到底做了什么?
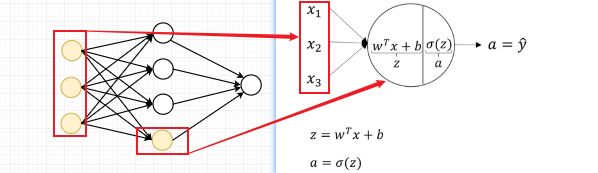
输入层的输入样本的每一个特征与隐藏层的特征方程线性拟合得到一个 值,通过一个激活函数
值,通过一个激活函数![]() 将值映射到(0,1)之间的激活值
将值映射到(0,1)之间的激活值 ,这就是逻辑回归的基本迭代公式。接下来我将用矩阵的方式推到所有公式,因为通常用矩阵来计算的话,并发性能会大大提升。
,这就是逻辑回归的基本迭代公式。接下来我将用矩阵的方式推到所有公式,因为通常用矩阵来计算的话,并发性能会大大提升。
三、DNN的前向算法思想
在此之前,我需要介绍一下接下来推到需要用到的符号,上角标  表示神经网络的层数。
表示神经网络的层数。
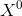 :
:![]() 一个列向量,表示每一个输入的样本特征,通常我们也用
一个列向量,表示每一个输入的样本特征,通常我们也用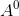 来表示,也叫初始值
来表示,也叫初始值
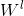 :weights是一个特征的权重矩阵,也是我们训练的模型重点
:weights是一个特征的权重矩阵,也是我们训练的模型重点
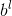 :bias是每个样本训练得到的偏差,在此不再介绍偏差和权重的知识
:bias是每个样本训练得到的偏差,在此不再介绍偏差和权重的知识
![]() :这里的
:这里的![]() 表示一个回归方程得到的回归值
表示一个回归方程得到的回归值
![]() :这里的
:这里的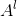 表示激活值,通过一个Sigmoid激活函数映射得到的值,其中也是最终的预测结果
表示激活值,通过一个Sigmoid激活函数映射得到的值,其中也是最终的预测结果
前向迭代的算法思想是,通过前面一层得到的激活值,来计算下一层的Z值,再通过Z值来计算激活值A。在这里可能有人会想计算这些值的作用是什么,如果有同学不明白的可以不用着急,我们先暂且搁置,稍后我会在推到的过程中解释。
正式推导过程:
将样本集  =
= 中样本的每一个特征权重和特征值按列堆叠可以得到
,这样是不是就很熟悉了,慢慢看到样本与权重拟合的雏形了,现在需要做一些转换,对线性代数熟悉的同学应该知道矩阵乘法的计算方式AB矩阵相乘需要满足A矩阵的列数要等与B矩阵的行数。
所以有,![]() ,用的转置矩阵
,用的转置矩阵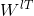 来计算。
来计算。
至此,我们还需要通过给
![]() 套上一个
套上一个 函数,来计算最终的激活值。
函数,来计算最终的激活值。
(1)、初始化
=  ,随机初始化一个服从正太分布
,随机初始化一个服从正太分布![]() (=np.random.randn(0,1))但是不能为0,否则计算的结果都是0没有意义,
(=np.random.randn(0,1))但是不能为0,否则计算的结果都是0没有意义, 可以是0,有了初始化的值,就可以通过下面的公式一步一步迭代得到最后一层的输出结果,也就是我们需要的预测值
可以是0,有了初始化的值,就可以通过下面的公式一步一步迭代得到最后一层的输出结果,也就是我们需要的预测值
(2)计算第一个隐层
![]() ,之后你会发现除了第一层的是,之后的每一层我都是用来代替的,这是因为前一层的就是下一层计算的,因为A的值是通过Sigmoid激活函数计算出来的,所以也叫激活值。用来激活下一层的计算的。
,之后你会发现除了第一层的是,之后的每一层我都是用来代替的,这是因为前一层的就是下一层计算的,因为A的值是通过Sigmoid激活函数计算出来的,所以也叫激活值。用来激活下一层的计算的。
(3)计算第二个隐层(输出层)
![]()
将计算推广到 层
![]() 在
在 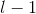 层,有:
层,有:
![]()
![]() 在 层,有:
在 层,有:
![]()
(4)、计算损失函数
通常对于二分类问题损失函数主要有交叉熵损失和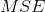 损失,为了方便计算我们在这里用交叉熵损失函数:
损失,为了方便计算我们在这里用交叉熵损失函数:
![]() ,由此我们可以得到代价函数,有如下表达:
,由此我们可以得到代价函数,有如下表达:
![]() 到此,例子中的所有单隐层的所有前向步骤全部结束了,是不是感觉很简单呢。但到这里的计算只是前向的结束,那么如何去迭代更新每一层的参数
到此,例子中的所有单隐层的所有前向步骤全部结束了,是不是感觉很简单呢。但到这里的计算只是前向的结束,那么如何去迭代更新每一层的参数![]() 呢?这里纪要再费点时间介绍一下反向传播算法的思想了。
呢?这里纪要再费点时间介绍一下反向传播算法的思想了。
(在这里额外补充一句,标准的最小二乘函数表达式是:![]() ,但有的时候你会发现深度学习中使用的最小二乘的损失函数是这样写的:
,但有的时候你会发现深度学习中使用的最小二乘的损失函数是这样写的:![]() ,他是在标准的最小二乘前面加了一个
,他是在标准的最小二乘前面加了一个 其实也没什么别的意思,就是为了求导的时候消除前面的系数 2,就这个作用,如果你看到这样的写法也不要太惊讶)
其实也没什么别的意思,就是为了求导的时候消除前面的系数 2,就这个作用,如果你看到这样的写法也不要太惊讶)
四、DNN的反向传播思想
好了,算法走到这里之后,我们需要思考一个问题,反向传播究竟是传播什么?又能得到什么?又能做什么?如果能把这几个问题想清楚,你就理解了BP得到思想精髓了也是整个DNN的思想精髓。
OK,来看一下我们计算的预测值( )与真实值(
)与真实值( )之间肯定是存在误差
)之间肯定是存在误差![]() 的,那么要消除误差需要做什么?我们发现贯穿始终的与预测值有关的就是每一层的参数
的,那么要消除误差需要做什么?我们发现贯穿始终的与预测值有关的就是每一层的参数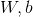 ,所以我们必须计算每一层的,通过不断调整,来减小误差,那么有了目标之后我们需要知道怎么做,也就是传播什么的问题了,传播什么回去可以调整,以达到减小误差的目的。
,所以我们必须计算每一层的,通过不断调整,来减小误差,那么有了目标之后我们需要知道怎么做,也就是传播什么的问题了,传播什么回去可以调整,以达到减小误差的目的。
现在再来思考一下,前向传播与反向传播的差别在哪儿?我们是否可以借鉴前向传播的思想,来计算反向传播的公式?
我们把反向的计算过程类比前向的思想,你会发现反向计算的时候,下面这个公式
![]() ,计算出来的结果
,计算出来的结果![]() 是不是类似前向传播中的初始值
是不是类似前向传播中的初始值![]() 初始值?当然这里的
初始值?当然这里的![]() 通常不用,因为没有意义,我们需要的是,?这些都是后话,我们来看一下反向传播的推导,看看你能否从中看出一些规律,并将其运用到日后的学习中。
通常不用,因为没有意义,我们需要的是,?这些都是后话,我们来看一下反向传播的推导,看看你能否从中看出一些规律,并将其运用到日后的学习中。
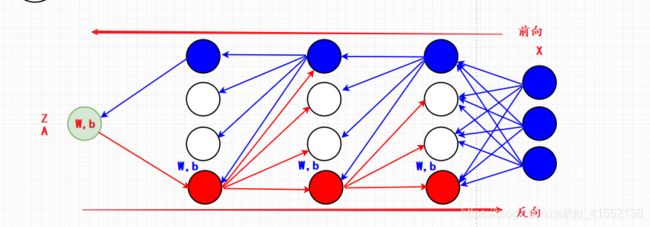
由于时间原因,上图我只画了正向和反向的部分全连接传播示意图,读者在查看的时候需要有一个基本的判断,不要被误导。
BP的正式推导过程:
(1)、伪初始化计算第 层
伪初始化可能你在其他文章中看不到这个词,这是我随便写的一个词,主要是对比前向的思想来帮助你了解反向传播,我们通过正向得到的最后一组数据是![]() ,以该数据为初始数据来反推前层所需要的数据。
,以该数据为初始数据来反推前层所需要的数据。
代价函数:![]()
![]() ,或写成
,或写成 ![]()
![]() ,或写成
,或写成 ![]() 为了看的更加清晰我将对上面的两个式子做仔细推导,以方便大家对比学习。
为了看的更加清晰我将对上面的两个式子做仔细推导,以方便大家对比学习。

and
求解的过程中我们发现,两个计算的式子中有一个共有的部分 ![]() 可以先将这部分计算出来cache()住,方便后面计算,加快计算速度。
可以先将这部分计算出来cache()住,方便后面计算,加快计算速度。
因此,上述的公式可以继续化简,得到:
(2)、反向求第层
根据上面 层给出的公式,,来推导 层的式子,发现有一个公共的式子可以单独求出
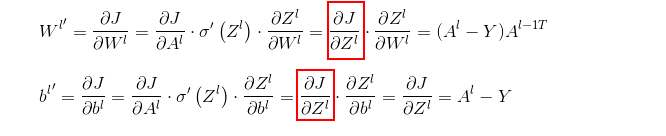
我们需要计算出![]() ,这样后面的计算就方便了,现在来看一下
,这样后面的计算就方便了,现在来看一下![]() 能否给出更加简单的推导?根据 层的公式,你会发现 层有如下规律:
能否给出更加简单的推导?根据 层的公式,你会发现 层有如下规律:
因为在 层我们已经计算出了![]() ,所以后面的式子我们只需要关注
,所以后面的式子我们只需要关注![]() 就行,继续推导
就行,继续推导![]() 的公式:
的公式:
![]()
![]()
综合两式得:![]()
故而,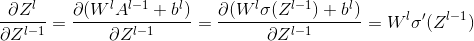
所以,![]()
由此,我们可以将层的![]() 公式进行化简,得到:
公式进行化简,得到:
![]()
![]()
然后再去更新即可
![]()
![]() ,因为前面已经计算过第 层的
,因为前面已经计算过第 层的![]() 所以,之后不再计算这层的权重和偏差,只需要根据第 层的
所以,之后不再计算这层的权重和偏差,只需要根据第 层的![]() 来不断递推后面的数据即可。
来不断递推后面的数据即可。
至此,所有的计算就全部结束了,我们可以通过将上下层的关系联系起来去迭代![]() 的数据,现在我们回过头来想一下反向传播的思想与前向传播的思想有什么不同,细心的朋友们可能已经发现,二者在计算思路上基本一致,都是通过上层的计算结果来计算下一层的结果,唯一需要注意的是思路的转变。
的数据,现在我们回过头来想一下反向传播的思想与前向传播的思想有什么不同,细心的朋友们可能已经发现,二者在计算思路上基本一致,都是通过上层的计算结果来计算下一层的结果,唯一需要注意的是思路的转变。
五、DNN能做什么?(选)
DNN的标准网络可以说是标准的神经网络计算方式,它的出现被认为是里程碑的式的发展,此后的CNN、RNN都是在DNN的基础上演变而来的,DNN能做的事情很多,往往经典学习领域的问题都能通过DNN集成学习实现,比如分类问题,语音识别,计算机视觉等,但是后两者有了更好的计算方式那就是RNN和CNN,他们在不同的领域发挥着不同的功能,CNN更适合图像识别领域,而RNN则更适合处理时间序列问题,这让处理一个问题的选择变得更加广泛和灵活,能够帮助开发者节约大量时间,从而将精力更多的放在研究精确和准确度上。
前面我用了大量的篇幅介绍二分类问题,相信你已经能够充分的理解DNN的算法思想了,下面介绍一个DNN图像识别的例子,我们需要知道DNN为什么能够识别图像?
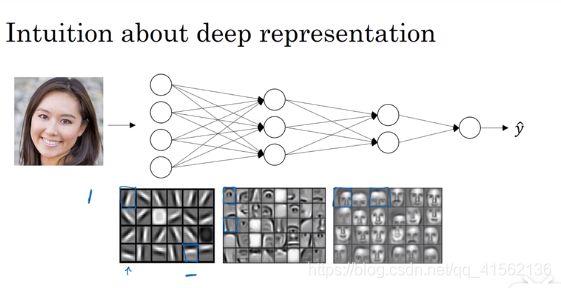
你应该知道图像其实就是一个三维的矩阵(1000,1000,3),表示红黄蓝三色的图形数据长宽比分别是1000*1000的图片,也就是1000维数*1000维数的三色图,以灰度图(只有一种颜色1000*1000*1)为例,灰度图识别通常不看第三维,所以当成二维数据来看待,我们以64*64的图片来看,将每一行的色度特征竖向排列成一个列向量,这个列向量就是一张图片的灰度图样本 ![]() ,样本维度为64*64=4096
,样本维度为64*64=4096
机器通过学习样本图的边缘信息(比如横竖排列的小方块),再通过不同的隐层来学习局部信息(比如眼睛,鼻子,嘴巴等),直到学习到全图信息为止(整个脸部特征),最后输出我们想要的结果,这就是隐层的作用。
以上就是我对DNN的理解和总结,希望能够帮助到你,如果文章中有什么不对的地方,请在评论中指出,我会及时修改。