HashTable哈希表/散列表(哈希桶)
哈希桶的结构
处理哈希冲突的开链法/拉链法 —-哈希桶
使用素数做哈希表的长度,可以降低哈希冲突
素数表
size_t GetNextPrime(size_t num)//素数表
{
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
for (size_t i = 0; i < _PrimeSize; ++i)
{
if (_PrimeList[i] > num)
{
return _PrimeList[i];
}
}
return _PrimeList[_PrimeSize - 1];
}
哈希桶的节点的定义
template <class K,class V>
struct HashNode
{
pair _kv;
HashNode* _next;
HashNode(const pair& kv)
:_kv(kv)
, _next(NULL)
{}
}; 哈希桶的插入
在插入前检查容量,以及负载因子。不够就进行增容,按素数表进行增,以减小哈希冲突。
找到位置后进行插入,每次插入都插入到表的下一个节点。如:
插入的为空时:
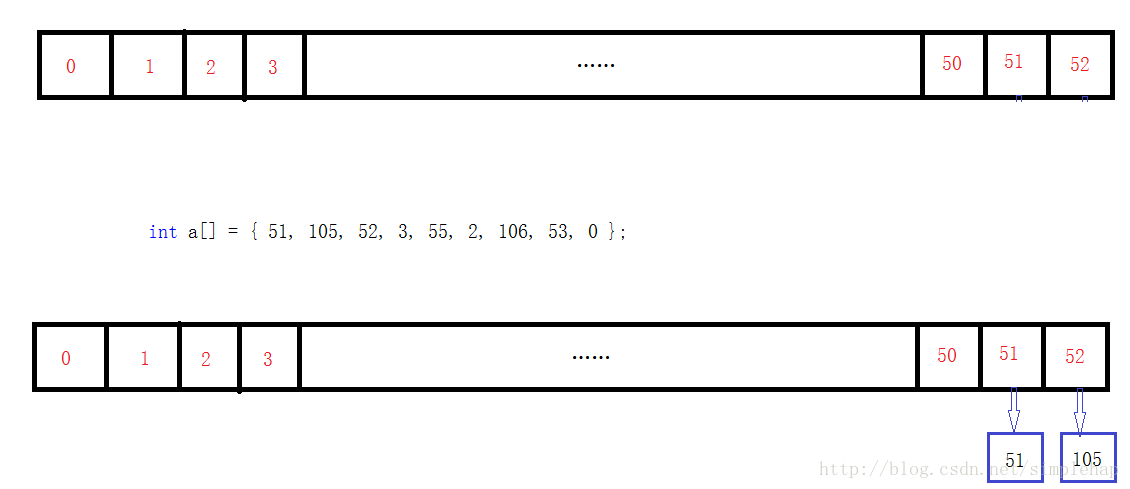
插入有节点时:

代码:
bool Insert(const pair& kv)
{
_Check();
size_t index = _HashFunc(kv.first,_tables.size());
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == kv.first)
return false;
cur = cur->_next;
}
Node* tmp = new Node(kv);
tmp->_next = _tables[index];
_tables[index] = tmp;
++_size;
return true;
} 哈希桶的查找
从表的一位置开始查找节点,存在返回节点,不存在返回空。
代码:
Node* Find(const K& key)
{
size_t index = _HashFunc(key, _tables.size());//确定表的位置
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)//存在
return cur;
cur = cur->_next;//不存在
}
return NULL;
}哈希桶的删除
先找到该节点,找到后进行删除,删除后返回true,没找到返回false。
删除分两中情况:
第一种,删除表的第一节点。(如:2、3)
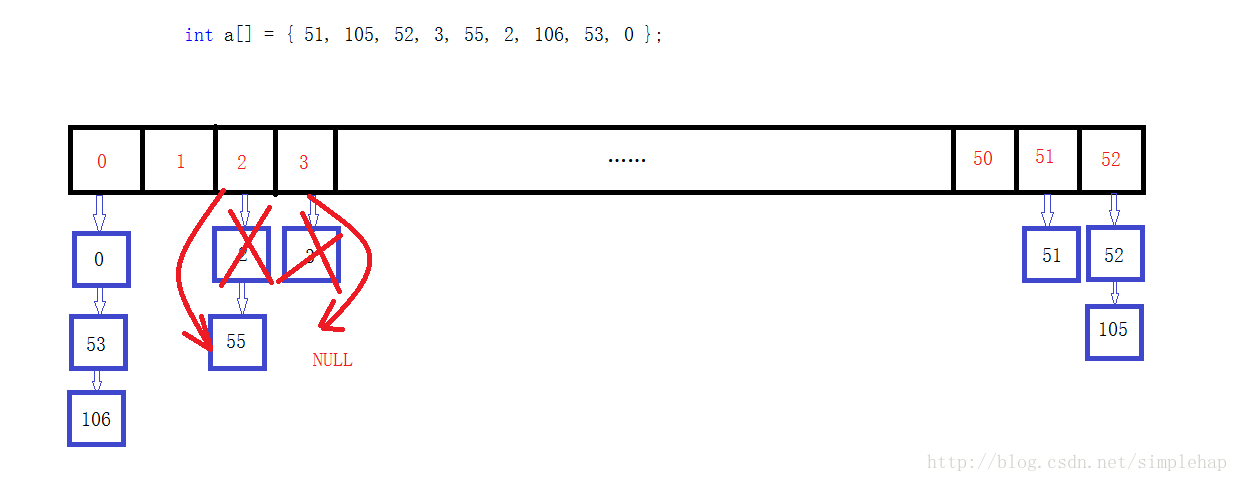
第二种,与第一种情况相反。(如:53、105)

代码:
bool Remove(const K& key)
{
size_t index = _HashFunc(key, _tables.size());//确定表的位置
Node* cur = _tables[index];
Node* prev = NULL;
while (cur)
{
if (cur->_kv.first == key)
{
if (prev == NULL)//第一种情况
_tables[index] = cur->_next;
else//prev != NULL//第二种情况
prev->_next = cur->_next;
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}代码:
"HashTablest.h"
#pragma once
#include _kv;
HashNode* _next;
HashNode(const pair& kv)
:_kv(kv)
, _next(NULL)
{}
};
template <class K>
struct __HashFunc
{
size_t operator()(const K& key)
{
return key;
}
};
template<>
struct __HashFunc<string>
{
static size_t BKDRHash(const char* str)
{
unsigned int seed = 131;// 31 131 1313 13131 131313
unsigned int hash = 0;
while (*str)
{
hash = hash*seed + (*str++);
}
return(hash & 0x7FFFFFFF);
}
size_t operator()(const string& key)
{
return BKDRHash(key.c_str());
}
};
template <class K,class V,class HashFunc = __HashFunc>
class HashTable
{
typedef HashNode Node;
public:
HashTable()
:_size(0)
{}
HashTable(const HashTable& ht)
:_size(0)
{
_tables.resize(ht._tables.size());
for (size_t i = 0; i < ht._tables.size(); ++i)
{
Node* cur = ht._tables[i];
while (cur)
{
Insert(cur->_kv);
cur = cur->_next;
}
}
}
~HashTable()
{
_Clear();
}
void Resize(size_t n)
{
_Check(n);
}
bool Insert(const pair& kv)
{
_Check();
size_t index = _HashFunc(kv.first,_tables.size());
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == kv.first)
return false;
cur = cur->_next;
}
Node* tmp = new Node(kv);
tmp->_next = _tables[index];
_tables[index] = tmp;
++_size;
return true;
}
Node* Find(const K& key)
{
size_t index = _HashFunc(key, _tables.size());
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)
return cur;
cur = cur->_next;
}
return NULL;
}
bool Remove(const K& key)
{
size_t index = _HashFunc(key, _tables.size());
Node* cur = _tables[index];
Node* prev = NULL;
while (cur)
{
if (cur->_kv.first == key)
{
if (prev == NULL)
_tables[index] = cur->_next;
else//prev != NULL
prev->_next = cur->_next;
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
protected:
void _Clear()
{
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = NULL;
}
_size = 0;
}
void _Check(size_t n = 0)
{
if (_tables.size() < n || _tables.size() == _size)
{
if (_tables.size() > n)
n = _tables.size();
vector