变量分箱:有监督分箱法和无监督分箱法
评分卡建模在金融行业应用得比较广泛,比如对客户的信贷诚信度进行评分。在建模过程中,对连续变量的分箱是一个必不可少的过程。
1. 分箱的用处
- 离散特征的增加和减少都很容易,易于模型的快速迭代;
- 稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
- 离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰;
- 逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
- 离散化后可进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
- 特征离散化后模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问;
- 特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。 可以将缺失作为独立的一类带入模型。
- 将所有变量变换到相似的尺度上
2. 分箱主要方法
分箱方法分为无监督分箱和有监督分箱。常用的无监督分箱方法有等频分箱,等距分箱和聚类分箱。有监督分箱主要有best-ks分箱和卡方分箱。
2.1 监督分箱方法:卡方分箱的原理
卡方分箱是自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
(1)基本思想:精确的离散化,类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
(2)分箱步骤:
① 预先设定一个卡方的阈值
② 初始化:根据要离散的属性对实例进行排序,每一个实例属于一个区间
③ 合并区间:计算每一对相邻区间的卡方值;将卡方值最小的一堆区间合并。

 :第
:第  区间第
区间第 ![]() 类的实例的数量
类的实例的数量
 : 的期望频率,
: 的期望频率, ![]() , N是总样本数,
, N是总样本数, 是第 组的样本数,
是第 组的样本数,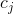 是第
是第 ![]() 类样本在全体中的比例。
类样本在全体中的比例。
(3)注意:这里需要注意初始化时需要对实例进行排序,在排序的基础上进行合并。
① 卡方阈值的确定:根据显著性水平和自由度得到卡方值自由度比类别数量小1。例如:有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
② 阈值的意义:类别和属性独立时,有90%的可能性计算得到的卡方值会小于4.6。大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
③ 分箱之后,需要评估。在评分卡模型中,最常用的评估手段是计算WOE和IV值。
2.2 监督分箱方法:best-ks分箱的原理
(1)变量的KS值
KS(Kolmogorov-Smirnov)用于模型风险区分能力进行评估,指标衡量的是好坏样本累计部分之间的差距 。KS值越大,表示该变量越能将正,负客户的区分程度越大。通常来说,KS>0.2即表示特征有较好的准确率。强调一下,这里的KS值是变量的KS值,而不是模型的KS值。
(2)KS的计算方式:
① 计算每个评分区间的好坏账户数。
② 计算各每个评分区间的累计好账户数占总好账户数比率(good%) 和累计坏账户数占总坏账户数比率(bad%)。
③ 计算每个评分区间累计坏账户比与累计好账户占比差的绝对值(累计good% - 累计bad%),然后对这些绝对值取最大值记得到KS值。
(3)Best-KS分箱:让分箱后的组别的分布差异最大化
Best-KS分箱的算法执行过程是一个逐步拆分的过程:
① 将特征值进行从小到大的排序。
② 计算出KS最大的那个值,即为切点,记为D。然后把数据切分成两部分。
③ 重复步骤2,进行递归,D左右的数据进一步切割。直到KS的箱体数达到我们的预设阈值即可。
(4)Best-KS分箱的特点:
① 连续型变量:分箱后的KS值 <= 分箱前的KS值
② 分箱过程中,决定分箱后的KS值是某一个切点,而不是多个切点的共同作用。这个切点的位置是原始KS值最大的位置。
2.3 无监督分箱方法:等频分箱法和等距分箱法
(1)等频分箱
区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。比如说 N=10 ,每个区间应该包含大约10%的实例。
(2)等距分箱
从最小值到最大值之间,均分为 N 等份。 如果 A,B 为最小最大值,则每个区间的长度为 W=(B−A)/N ,则区间边界值为A+W,A+2W,…. A+(N−1)W 。这里只考虑边界,每个等份的实例数量可能不等。
3. WOE转换
WOE的全称是“Weight of Evidence”,即证据权重,WOE是对原始自变量的一种编码形式。要对一个变量进行WOE编码,需要首先把这个变量进行分箱。分箱后,对于第i组,WOE的计算公式如下:

其中,  是该分组中违约客户的数量,
是该分组中违约客户的数量,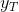 是全部样本中所有违约客户的数量
是全部样本中所有违约客户的数量
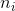 是该分组中未违约客户的数量,
是该分组中未违约客户的数量,![]() 是全部样本中所有未违约客户的数量
是全部样本中所有未违约客户的数量
WOE表示的实际上是”当前分组中违约客户占全部样本中所有违约客户的比例“和“当前分组中没有违约的客户占全部样本中所有没有违约的客户的比例”的差异。
对公式做一个简单变换,可以得到:

变换以后可以看出,WOE也可以理解为:当前该组中违约的客户和未违约客户的比值和所有样本中违约的客户和未违约客户的比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。WOE越大,这种差异越大,该分组里的样本违约的可能性就越大,WOE越小,差异越小,这个分组里的样本违约的可能性就越小。