Kafka消费顺序保证
面试被问到如何按照Producer的顺序去消费Consumer?故在此做个记录。
首先几个概念Topic,Producer
topic
-Topic:A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
- 主题:主题是被发布记录的类别或提要名称,Topics在kafka中通常是多订阅者模式;也就是说,一个主题可以有0,1,甚至是多个消费者去订阅消费topic所写的数据;
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
- 对于每一个主题,kafka集群都维护如图所示的分区日志:(从左到右写入)
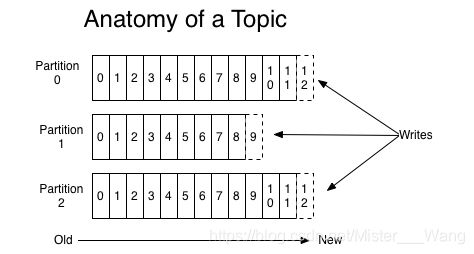
- Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log. The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
-每一个分区都按照有序的,不变的且在持续追加的日志记录 - 结构化提交日志。在分区中的每一个记录都会分配到一个有序的名为偏移量的id,并且该id能够唯一表示分区内的每一条记录;
- The Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period. For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
- kafka集群能持久的保持所有发布的记录 - 无论记录是否被消费 - 并且持久的保留期是可以配置的。举个例子,如果你设置保留期为2Days,那么记录发布两天之内是能够被消费的,两天之后该记录就会被丢弃以腾出存储空间。kafka关于数据大小的性能表现是极其稳定的所以长时间存储数据不是问题。
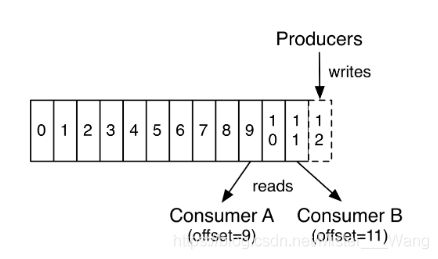
- In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes. For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
- 偏移量主要是由消费者管理,因此消费者可以自由控制消费信息的顺序,但是通常情况下都是线性推进的。
- This combination of features means that Kafka consumers are very cheap—they can come and go without much impact on the cluster or on other consumers. For example, you can use our command line tools to "tail" the contents of any topic without changing what is consumed by any existing consumers.
- 这个特性意味着kafka消费者是cheap的-因为他们在集群中的加入以及离开操作对集群其他消费者几乎没啥影响。
- The partitions in the log serve several purposes. First, they allow the log to scale beyond a size that will fit on a single server. Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. Second they act as the unit of parallelism—more on that in a bit.
- 日志分区有几个目的:首先,分区允许日志大小超过所在单服务器的容量大小。每一个分区必须适应所在服务器,但是一个topic可分成多个分区,所以一个topic就可以处理任意数量的数据。其次,分区还可以作为平行度的单位(类似于横向扩展?)
producer
- Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic. This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record).
- 生产者发布数据到主题。生产者决定哪条记录发布到topic中的那个分区 - 采用循环的方式(平衡负载),也会根据语义分配函数(比如基于记录中的key)
-- Translation未完待续。。。
综上所述,可以推出每一个topic中的每一partition中都是有序队列,但是partition之间就不一定,顺序是随机的;
- solutions:
1.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION
| NAME | DESCRIPTION | TYPE | DEFAULT | VALID VALUES | IMPORTANCE |
|---|
| max.in .flight .requests .per.connection |
The maximum number of unacknowledged requests the client will send on a single connection before blocking. Note that if this setting is set to be greater than 1 and there are failed sends, there is a risk of message re-ordering due to retries (i.e., if retries are enabled). | int | 5 | [1,...] | low |
- 设置客户端在阻塞之前发送给单一连接点最大未确认请求的次数;缺省值为5,如果设置大于1且出现失败发送,就会有重复发送的操作,导致消息重复排序。
- 设置为1,顺序正常;
- 但是设置为1也会造成发送到同一个分区的消息重新排序;
| retries | Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. Note that this retry is no different than if the client resent the record upon receiving the error. Allowing retries without setting max.in.flight.requests.per.connection to 1 will potentially change the ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second succeeds, then the records in the second batch may appear first. Note additionally that produce requests will be failed before the number of retries has been exhausted if the timeout configured by delivery.timeout.ms expires first before successful acknowledgement. Users should generally prefer to leave this config unset and instead use delivery.timeout.ms to control retry behavior. |
int | 2147483647 | [0,...,2147483647] | high |
2.enable.idempotence = true
- 需要保证消息是有序且唯一的,可以将参数enable.idmpotence = true;
| enable.idempotence | When set to 'true', the producer will ensure that exactly one copy of each message is written in the stream. If 'false', producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. Note that enabling idempotence requires max.in.flight.requests.per.connection to be less than or equal to 5, retriesto be greater than 0 and acks must be 'all'. If these values are not explicitly set by the user, suitable values will be chosen. If incompatible values are set, a ConfigExceptionwill be thrown. |
boolean | false | low |
- 幂等性:在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
- 设置为true时,生产者保证每一次消息的copy都是唯一的,也就是说底层在出现retry的时候也会通过增加一个用户不可见的pid值,而broker只会接受同一个pid值且sequence值+1的消息,这样就算是失败了重试也能保证数据不重复。
- 参数前提:保证max.in.flight.requests.per.conection 小于等于5大于0且acks必须是all;
如有错误,欢迎指正~
REF:http://kafka.apache.org/documentation/