自动驾驶平台Apollo 3.5阅读手记:Cyber RT中的协程(Coroutine)
背景
2019 CES上百度发布了Apollo 3.5,其中的亮点之一就是其高性能计算框架Cyber RT。我们知道,Apollo在3.0及之前是基于ROS并作了一些改进。经过十多年的发展,ROS已建立起强大生态,在机器人社区广受欢迎,但其多用于学术界实验室验证机器人算法,并不是为了高可靠工业界产品设计的。虽然社区已经看到这一矛盾,并已开整ROS 2.0,但现在还处于开发阶段。自动驾驶相较于其它高性能系统而言,最重要的需求之一就是实时性。因为对于自动驾驶车来说,一旦车辆无法在指定时间内作出反应,可能车里的人就凉了。众所周知,实时性并不是追求绝对的高性能,而是关注任务执行时间的确定性(有时甚至是以吞吐率为代价的)。相信这也是Apollo将基础框架切为自研Cyber RT的重要原因之一。自动驾驶系统是由很多模块组成的复杂系统,模块之间又有着复杂的依赖关系。常见方法一般会将各模块放在线程或进程中,然后交由OS来调度。这样的方式可能会有几个潜在问题:1) 在Linux中线程/进程调度会有user space到kernel space的切换开销;2) 如果没有设置affinity的话可能会被调度到其它CPU上,导致cache使用效率低; 3) Kernel中的scheduler是通用目的的,虽然可以通过priority加以一定的控制,但如果要结合业务逻辑进行更复杂的调度就没办法。为了进一步减少调度开销,以及提高系统确定性,Cyber RT中引入了自己的user space的scheduler,这也是其一大特点。关于这个scheduler网上已经有比较具体的分析,这里就不重复了。本文来聊一聊scheduler的调度单元-协程(coroutine)。
协程是一个非常古老的概念了。作为一种高并发编程方法,业界已经有很多优秀的实现的应用,比如boost库中的Coroutine,微信中的libco,Go语言中的goroutine等等。如果对这些实现在特点上进行分类的话可以有几个维度:
- 共享栈(stackless) vs. 非共享栈(stackfull):共享栈方式中每个协程有自己的栈,因此它可以在深层调用中被挂起。但当协程数很大时栈可能会占用比较多内存;而stackless方式中所有协程都是共享一个栈,因此只能在顶层函数中被挂起。
- 对称(symmetric) vs. 非对称(asymmetric):对称方式中协程之间地位是对等的,协程之间可以相互移交控制;而非对称方式中,如果协程A将控制移交给协程B,它们二者间不是对等的。B交出控制权时只能交还给A。二者相当于函数调用者和被调用者的关系。
- 基于ucontext vs. 写汇编 vs. 其它:上下文切换有多种方式,比较主流的有基于ucontext实现和自己写汇编两种方式,其它的还有比如用setjmp/longjmp的实现。ucontext是libc提供的一族函数。通过它们,可以很方便地实现协程。而且不用写汇编,这意味着良好的可移植性。但看其
swapcontext()函数源码可以发现,它会有系统调用。本来协程的优点之一是调试不需要切到kernel space,结果这里还是要切,性能就会打些折扣。因此可以看到不少库会选择自己写汇编实现上下文切换,尽管这样基本需要为每一个平台都写一份。
总得来说,Cyber RT中的协程是一种非共享栈、非对称,写汇编进行上下文切换的方式。下面我们来简单看下它的实现:
代码走读
协程实现位于apollo/cyber/croutine/目录。主要实现类为CRoutine。先画个简单的示意图:
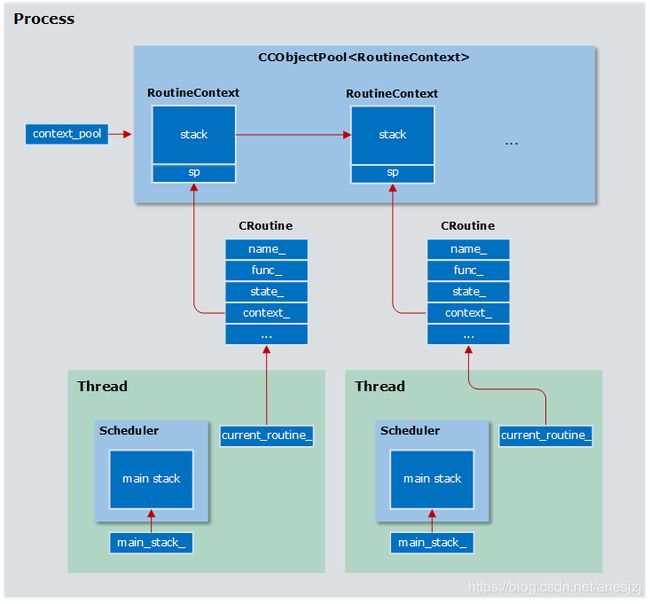
CRoutine中几个关键成员变量如:
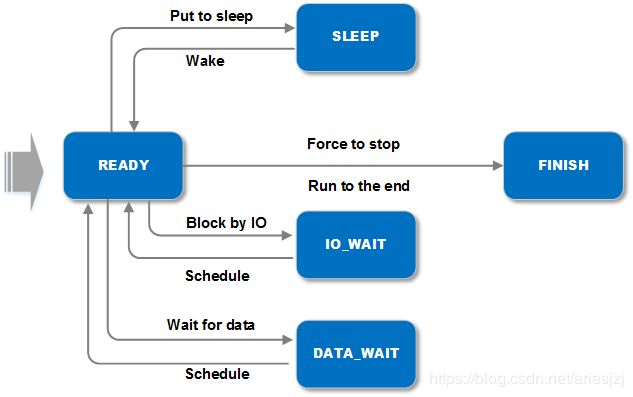
func_就是该协程要执行的函数体。context_指向相应的RoutineContext对象。该对象存放的就是对应协程的上下文。对于一个执行体来说,最主要的上下文就是栈和寄存器了,因此RoutineContext中也非常简单,就是一块空间作为栈(大小为8M),加一个栈指针。进程中所有的RoutineContext对象会有一个全局的对象池来管理,其指针保存在context_pool变量中。这个对象池CCObjectPool的实现位于concurrent_object_pool.h。它会在初始化时将指定个数的对象全分配好。前面提到过对于自动驾驶系统实时性很重要,内存动态分配也是实时性一大杀手。另外,为了高效它使用的是lock-free的实现。证明lock-free算法的正确性太烧脑不细究了。有兴趣的可以翻阅《C++ Concurrency in Action Practical Multithreading》,更学究的可以看下《The Art of Multiprocessor Programming》。state_为协程的状态。状态间切换图大致如下:
对于每个线程来说,CRoutine中有两个thread local的变量:
current_routine_指向当前线程正在执行的协程对应的CRoutine对象。main_stack_保存主执行体的栈,也就是系统栈。
CRoutine的构造函数会通过MakeContext()函数和生成该协程的上下文:
void MakeContext(const func &f1, const void *arg, RoutineContext *ctx) {
ctx->sp = ctx->stack + STACK_SIZE - 2 * sizeof(void *) - REGISTERS_SIZE;
std::memset(ctx->sp, 0, REGISTERS_SIZE);
char *sp = ctx->stack + STACK_SIZE - 2 * sizeof(void *);
*reinterpret_cast<void **>(sp) = reinterpret_cast<void *>(f1);
sp -= sizeof(void *);
*reinterpret_cast<void **>(sp) = const_cast<void *>(arg);
}
代码就几行,画个图就比较清晰了。执行完MakeContext()函数后RoutineContext中的结构如下:
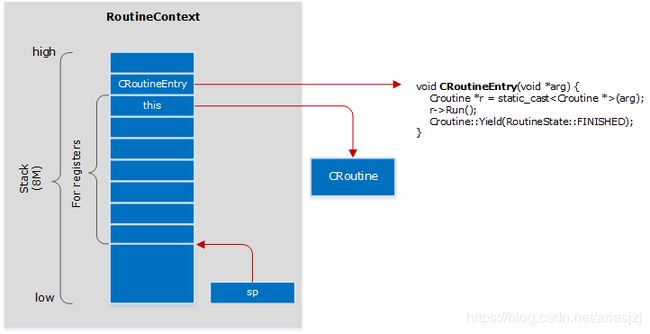
为啥要整成这副样子,这要结合下面的上下文切换来讲。
协程(非对称)中最核心需要实现resume和yield两个操作。前者让该协程继续执行,后者让协程交出控制权。这里分别是Resume()和Yield()函数。前者最核心做的事就是将上下文从当前切换到目标协程;后者反之。它们都是通过SwapContext()函数实现的上下文切换。我们来细看一这个函数:
inline void SwapContext(char** src_sp, char** dest_sp) {
ctx_swap(reinterpret_cast<void**>(src_sp), reinterpret_cast<void**>(dest_sp));
}
其中的ctx_swap()函数是用汇编实现的,在swap.S:
.globl ctx_swap
.type ctx_swap, @function
ctx_swap:
pushq %rdi
pushq %r12
pushq %r13
pushq %r14
pushq %r15
pushq %rbx
pushq %rbp
movq %rsp, (%rdi)
movq (%rsi), %rsp
popq %rbp
popq %rbx
popq %r15
popq %r14
popq %r13
popq %r12
popq %rdi
ret
代码很简单,我们以scheduler中的调度循环Processor::Run()函数通过CRoutine::Resume()函数切到目标协程为例理解一下。其中最核心的上下文切换是这条语句:
SwapContext(GetMainStack(), GetStack());
下图为调用SwapContext()函数前后上下文(栈以及寄存器)的变化。
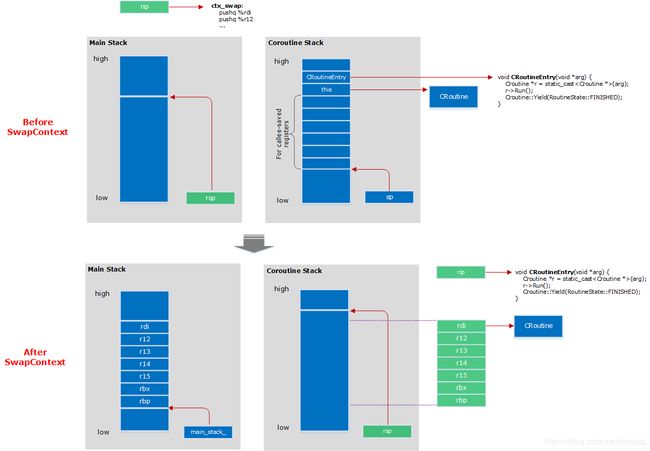
调用前目标协程的栈信息就如前面MakeContext()函数中设置好的。RoutineContext中的成员stack就是协程的栈,成员sp对应寄存器rsp。成员sp指向的成员stack中的位置从低往高依次为7个寄存器大小的空间及CRoutineEntry函数指针。7个寄存器分别对应rdi, rbx, rbp, r12-r15。根据x86_64平台的ABI calling convention,rbx, rbp, r12-r15是callee-saved registers。也就是说被调用者有责任保存它们,以保证它们在函数过程(对调用者来说,SwapContext()的过程就像一个普通函数调用)中值不变。为什么对应rdi位置放的是CRoutine的指针,因为calling convention中规定rdi放被调用函数的第一个参数。而CRoutineEntry()第一个参数正是CRoutine指针。
调用SwapContext()函数前物理的rsp寄存器指向的是系统栈,然后经过上面汇编ctx_swap函数一进来一顿pushq,会将当前的这些callee-saved registers全都压到栈中保存起来,然后movq %rsp, (%rdi)语句将rsp存到main_stack_变量中。这样后面切回来时才能把这些上下文恢复回来。就像前面说的,calling convention规定,寄存器rdi放的第一个参数。对于Resume()函数中调用的ctx_swap函数来说,第一个参数实际为main_stack_。同理,由于寄存器rsi放的是第二个参数,这里为&(context_->sp)。因此,下一条语句movq (%rsi), %rsp是将之前设好的RoutineContext中的sp设到寄存器rsp上,这样栈就已经切过来了。然后是一坨popq,将协程栈上对应寄存器的内容搬到物理寄存器上。最后一条ret语句,就是把CRoutineEntry()函数的地址弹出来,然后跳过去执行。看CRoutineEntry()的实现知道它会调用当时构建CRoutine时用户传入的函数。这样就开始执行用户逻辑了。
结语
与另一种常见并发编程手段-线程不同,协程是由用户自己来做任务的切换(故又称“用户级线程”)。因此可以在单线程下实现高并发,是一种更细粒度的并发。它有自己的优缺点:
- 优点:一是上下文切换效率很高,因为切换对于kernel来说是无感知的,不需陷入kernel space,其切换开销基本和函数调用差不多;二是协程间共享数据不用加锁,因为它们还是在一个线程上跑,并不会真正并行执行;三是能用同步的风格写异步的逻辑,不会callback满天飞。
- 缺点:一是本质上任务还是在一个线程上执行,无法利用多CPU的并行能力,因此实际当中多还是和线程结合使用。二是一旦一个协程开跑,除非它自己交出控制权,否则没法被其它协程抢占。如果这个协程还block了,那就很不幸了。。。