大数据常见面试题之HBase
文章目录
- 一.为什么使用HBase存储
- 二.Rowkey设计原则
-
- 1.长度原则
- 2.唯一原则
- 3.排序原则
- 4.散列原则
- 三.Hbase的优化
- 四.HBase读写流程
-
- 1.元数据存储
- 2.读流程
- 3.写流程
- 4.数据Flush过程
- 五.Rowkey如何设计避免热点问题
-
- 1.reverse反转
- 2.salt加盐
- 3.Hash散列或者Mod
- 六.HBase的最小存储单位
- 七.Hbase如何进行预分区以及作用
- 八.HBase中的HFile什么时候需要合并成大文件,什么时候拆分成小文件
-
- 1.合并
- 2.拆分
- 九.为什么HBase查询比较快
一.为什么使用HBase存储
- HBase(Hadoop Database) 是一个靠可靠性,高性能,可伸缩,面向列的分布式数据库
- HBase与Hadoop的关系非常紧密,Hadoop的hdfs提供了高可靠性的底层存储支持,Hadoop MapReduce 为 HBase提供了高性能的计算能力,zookeeper为Hbase提供了稳定性及failover机制的保障. 同时其他周边产品诸如Hive可以与HBase相结合使在HBase进行数据统计处理变得简单,Sqoop为HBase提供了方便的RDBMS数据导入功能,使传统数据库的数据向HBase中迁移变得容易,spark等高性能的内存分布式计算引擎也可能帮助我们更加快速的对HBase中的数据进行处理分析
二.Rowkey设计原则
1.长度原则
- Rowkey是一个二进制码流,可以是任意字符串,最大长度为64kb,实际应用中一般为10-100byte,以byte[]形式保存,一般设计成定长.建议越短越好,不要超过16个字节,原因如下:
- 数据的持久化文件HFile中时按照key-value存储的,如果Rowkey过长,例如超过100byte,那么1000w行的记录,仅Rowkey就需占用近1G空间.这样会极大影响HFile的存储效率
- MemStore会缓存部分数据到内存中,若Rowkey字段过长,内存的有效利用率就会降低,就不能缓存更多的数据,从而降低检索效率
- 目前操作系统都是64位系统,内存8字节对齐,控制在16字节,8字节的整数倍利用了操作系统的最佳特性
2.唯一原则
- 必须在设计上保证Rowkey的唯一性.由于在HBase中数据存储是key-value形式,若向HBase中同一张表插入相同Rowkey的数据,则原先存在的数据会被新的数据覆盖
3.排序原则
- HBase的Rowkey是按照ASCII有序排序的,因此我们在设计Rowkey的时候要充分利用这点
4.散列原则
- 设计的Rowkey应均匀的分布在各个HBase节点上
三.Hbase的优化
1.表设计
- 1)建表时就分区(预分区),rowkey设置定长(64字节),CF2到3个
- 2)Max Versio, Time to live, Compact&split
2.写表
- 1)多Htable并发写,提高吞吐量
- 2)Htable参数设置,手动flush,降低IO
- 3)WriteBuffer
- 4)批量写,减少网络I/O开销
- 5)多线程并发写,结合定时flush和写buffer(writeBufferSize),可以既保证在数据量小的时候,数据可以在较短时间内被flush(如1秒内),同时有保证在数据量大的时候,写buffer一满就及时进行flush
3.读表
- 1)多Htable并发读,提高吞吐量
- 2)Htable参数设置
- 3)批量读
- 4)释放资源
- 5)缓存查询结果
四.HBase读写流程
1.元数据存储
-
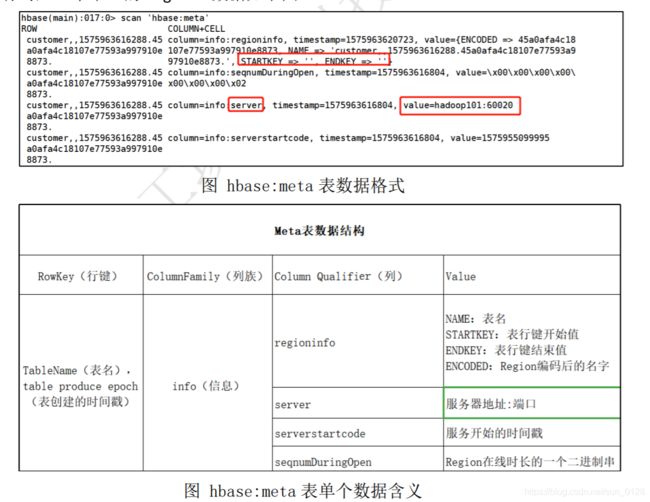
HBase中有一个系统表hbase:meta存储HBase元数据信息,可以在HBase Web UI查看到相关信息。如下图。

-
该表记录保存了每个表的Region地址,还有一些其他信息。例如Region的名字,对应表的名字,开始行键,结束行键,服务器的信息。hbase:meta 表中每一行对应一个单一的Region。数据如下图。
-
ZooKeeper中存储了hbase:meta表的位置,客户端可以通过Zookeeper查找到hbase:meta表的位置,hbase:meta是HBase当中一张表,肯定由一个HRegionServer来管理,其实主要就是要通过Zookeeper的 “/hbase/meta-region-server” 获取存储 “hbase:meta” 表的HRegionServer的地址。

-
图中可用看出,hbase:meta表的位置是hadoop103。
2.读流程
-
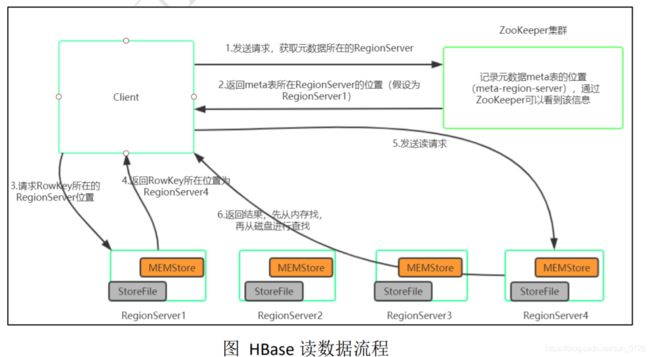
HBase读数据流程如图所示:
-
1)Client先访问Zookeeper,从meta表读取Region的位置,然后读取meta表中的数据。meta中又存储了用户表的Region信息;
-
2)根据RowKey在meta表中找到对应的Region信息;
-
3)找到这个Region对应的RegionServer;
-
4)查找对应的Region;
-
5)先从MemStore找数据,如果没有,再到BlockCache里面读;
-
6)BlockCache还没有,再到StoreFile上读(为了读取的效率);
-
7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
从整体的方面看,如下图所示:

3.写流程
Hbase 写流程如图所示:
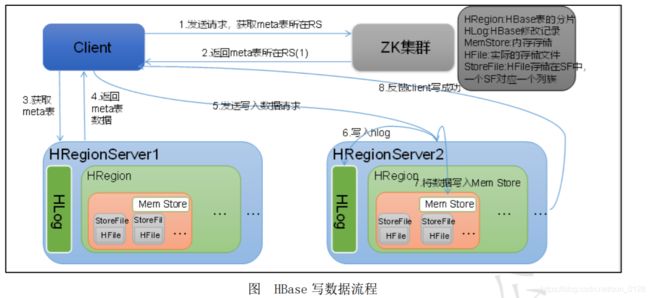
- 1)Client访问Zookeeper,获取meta表所处位置(ip)。
- 2)访问meta表,然后读取meta表中的数据。
- 3)根据namespace(类似与关系型数据库中的数据库,下一课会介绍),表名和RowKey在meta表中找到该RowKey应该写入到哪个Region。
- 4)找到这个Region对应的RegionServer,并发送写数据请求。
- 5)HRegionServer将数据先写到HLog(Write Ahead Log)。为了数据的持久化和恢复。
- 6)HRegionServer 将数据写到内存(MemStore)。
- 7)反馈Client写成功。
写数据这一块也可以看出,HBase将数据写入到内存中后,就返回给客户端写入成功,响应非常快。这也是为什么HBase写数据速度快的原因。
4.数据Flush过程
- 从上面写入数据的流程中可以看出,HBase写数据是写入到MemStore内存就会返回客户端了,并没有直接落磁盘。这也是为什么HBase插入数据会比较快的原因,磁盘IO非常小。那么什么时候数据会落磁盘呢?其实MemStore空间是有限的,当MemStore数据达到阀值(默认是128M,老版本是64M),RegionServer将数据刷到HDFS上,生成HFile,然后将内存中的数据删除,同时删除HLog中的历史数据,该操作是由RegionServer自己完成的。
五.Rowkey如何设计避免热点问题
1.reverse反转
- 针对固定的长度Rowkey反转后存储,这样可使Rowkey中经常改变的部分放在最前面,可以有效的随机Rowkey
- 反转Rowkey的例子通常以手机举例,可以将手机号反转后的字符串作为Rowkey,这样的就避免了以手机号那样比较固定开头(137x,15x等)导致热点问题,这样做的缺点是牺牲了Rowkey的有序性
2.salt加盐
- salt是将每一个Rowkey加一个前缀,前缀使用一些随机字符,使得数据分散在多个不同的Region,达到Region负载均衡的目标
- 比如在一个有4个Region(注:以[,a) [a,b) [b,c),[c ) 为Region起至)的HBase表中,加salt前的Rowkey:abc001, abc002, abc003
- 我们分别加上a b c前缀,加salt后Rowkey为:a-abc001, b-abc002, c-abc003
- 可以看到,加盐前的Rowkey默认会在第二个region中,加盐后的Rowkey数据会分布在3个region中,理论上处理后的吞吐量应该是之前的3倍.由于前缀是随机的,读这些数据时需要耗费更多的时间,所以salt增加了写操作的吞吐量,不过缺点是同时增加了读操作的开销
3.Hash散列或者Mod
- 用Hash散列来替代随机salt前缀的好处是能让一个给定的行有相同的前缀,这在分散了Region负载的同时,使读操作也能够推断.确定性Hash(比如mod5 后取前4位做前缀)能让客户端重建完整的Rowkey,可以使用get操作直接get想要的行
- 例如将上述的原始Rowkey经过hash处理,此处我们采用md5 散列算法取前4位做前缀结果如下:
- 9bf0-abc001 (abc001 在 md5 后是 9bf049097142c168c38a94c626eddf3d,取前4位是9bf0)
- 7006-abc002
- 95e6-abc003
- 若以前4个字符作为不同分区的起止,上面几个Rowkey数据会分布在3个region中.实际应用场景是当数据量越来越大的时候,这种设计会使得分区之间更加均衡
- 如果Rowkey是数字类型的,也可以考虑Mod方法
六.HBase的最小存储单位
- HRegion是HBase中分布式存储和负载均衡的最小单元,最小单元就表示不同的HRegion可以分布在不同的HRegion server上
- HRegion由一个或者多个Store组成,每个store保存一个columns family. 每个Store又由一个memStore和0至多个StoreFile组成,每个storefile以HFile格式保存在hdfs上,HFile格式保存在hdfs上,HFile是hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile的底层就是HFile
七.Hbase如何进行预分区以及作用
- HBase默认建表时有一个region.这个region的rowkey是没有边界的,即没有startkey和endkey,在数据写入时,所有数据都会写入这个默认的region,随着数据的不断增加,此region已经不能承受不断增长的数据量,会进行split,分成2个region. 在此过程中,会产生两个问题:
- 1.数据往一个region上写,会有写热点问题.
- 2.region split会消耗宝贵的集群I/O资源.
- 基于此我们可以控制在建表的时候,创建多个空region,并确定每个region的起始和终止rowkey,这样只要我们的rowkey设计能均匀的命中各个region,就不会存在写热点问题.自然split的几率也会大大降低. 当然随着数量的不断增长,该split的还是要进行split. 像这样预先创建HBase表分区的方式,称之为预分区
- 创建预分区可以通过shell或者java代码实现
#以下是shell方式
#指明分割点
create 't1','f1',SPLITS=>['10','20','30','40']
#HexStringSplit指明分割策略,-c 10 指明要分割的区域数量,-f指明表中的列族,用":"分割
hbase org.apache.hadoop.hbase.util.RegionSpliter test_table HexStringSplit -c 10 -f f1
#根据文件创建分区并压缩
create 'split_table_test',{
NAME => 'cf',COMPRESSION => 'SNAPPY'},{
SPLITS_FILE => 'region_split_info.txt'}
八.HBase中的HFile什么时候需要合并成大文件,什么时候拆分成小文件
1.合并
1.HFile合并
- 1)为什么需要HFile合并
- 我们都知道HBase是一个可以随机读写的数据库,而他所基于的持久化层hdfs却是要么新增,要么整个删除,不能修改的系统.那么HBase怎么实现我们的增删改查的?真实的情况是这样的:HBase是一种Log-Structured Merge Tree架构模式,HBase几乎总是在做新增操作.当你新增一个单元格的时候,HBase在hdfs上新增一条数据.当你修改一个单元格的时候,HBase又在hdfs新增一条数据,只是版本号比之前那个大(或者自己定义). 当你删除一个单元格的时候,HBase还是新增一条数据!只是这条数据没有value,类型为DELETE,这条数据叫墓碑标记(Tombstone). 真正的删除发生在什么时候,由于数据库在使用过程中积累了很多增删改查操作,数据的连续性和顺序性必然会被破坏.为了提升性能,HBase每间隔一段时间都会进行一次合并(Compaction),合并的对象为HFile文件.另外随着数据写入不断增多,Flush次数也会不断增多,进而HFile数据文件就会越来越多.然而,太多数文件会受导致数据查询IO次数增多,因此HBase尝试着不断对这些文件进行合并
- 合并分为两种
minor compaction 和 major compaction - Minor Compaction:将Store中多个HFile合并为一个HFile.在这个过程中达到TTL的数据会被移除,但是被手动删除的数据不会被移除.这种合并触发频率较高
- Major Compaction: 合并Store中所有的HFile为一个HFile.在这个过程中被手动删除的数据会被真正的删除.同时被删除的还有单元格内超过MaxVersions的版本数据.这种合并触发频率较低,默认为七天一次.不过由于Major Compaction消耗的性能较大,你不会想让它发生在业务高峰期,建议手动控制Major Compaction的时机
- 注意:Major Compaction 是把一个store中的HFile合并为一个HFile文件,并不是把一个Region中的所有HFile合并成一个文件
2.Compaction执行时间
- 触发Compaction的时机有以下几种:
- 通过CompactionChecker线程来定时检查是否需要执行compaction(RegionServer启动时在initializeThreads() 中初始化),每隔10000秒(可配置)检查一次
- 每当RegionServer发生一次Memstore flush操作之后也会进行检查是否需要进行Compaction操作
- 手动触发,执行命令: major_compact ,compact
3.Compaction相关控制参数
- 以下的配置是2.0版本以上的
- 1)Minor Compaction
| 属性值 | 默认值 | 含义 |
|---|---|---|
| hbase.hstore.compaction.max | 10 | 表示一次minor compaction中最多选取10个store file |
| hbase.hstore.compaction.min | 3 | 表示至少需要三个满足条件的store file时,minor compaction才会启动 |
| hbase.hstore.compaction.min.size | 表示文件大小小于该值的store file 一定会加入到minor compaction的store file中 | |
| hbase.hstore.compaction.max.size | 表示文件大于该值的store file一定会被排除 | |
| hbase.hstore.compaction.ratio | 1.2 | 将store file 按照文件年龄排序(order to younger) ,minor compaction总是从old store 开始选择 |
- 将StoreFile按照文件年龄排序,minor comcpation总是从older store file开始选择,计算公式:该文件<(所有文件大小总和-该文件大小)*比例因子.也就是说如果该文件的size小于后面hbase.hstore.compaction.max 个store file fize 之和乘以ratio的值,那么该store file 将加入到minor compaction中. 如果满足minor compaction条件的文件数量大于hbas.hstore.compaction.min才会启动.
- 如果该文件大小小于最小合并大小(minCompactSize),则连上面公式都不需要套用,直接进入带合并列表. 最小合并大小的配置项:hbase.hstore.compaction.min.size. 如果没设定该配置项,则使用hbase.hregion.memstore.flush.size 被挑选的文件必须能通过以上提到的筛选条件,并且组合内含有的文件数必须要大于hbase.hstore.compcation.min ,小于hbase.hstore.compcation.max. 文件太少了没必要合并,浪费资源;文件太多了太消耗资源,怕机器受不了
- 上面的选择方式,会形成多个满足条件的store file组合,然后再比较哪个文件组合包含的文件更多,就合并哪个组合.如果出现平局,就挑哪个文件尺寸综合更小的组合
- 2)Major Compaction
- hbase.hregion.majorcompaction : majorcompaction发生的周期,单位是毫秒,默认值为七天
- 注意:虽然有以上机制控制Major Compaction的发生时机,但是由于Major Compaction时对系统的压力是非常大的,所以建议关闭自动Major Compaction(hbase.hregion.majorcompaction=0),采用手动触发的方式,定期进行Major Compaction.
- 手动Major Compaction 命令为: major_compact,如下:
#Compact all region in a table:
hbase> major_compact't1'
hbase> major_compact'ns1:t1'
#Compact an entire region:
hbase> major_compcat'r1'
#Compact a single column family within a region:
hbase> major_compact'r1','c1'
#Compact a single column family within a table:
hbase> major_compact't1','c1'
2.拆分
1)ConstantSizeRegionSplitPolicy(了解内容)
- 在0.94版本的时候HBase只有一种拆分策略。这个策略非常简单,从名字上就可以看出这个策略就是按照固定大小来拆分Region。控制它的参数是:
| hbase.hregion.max.filesize | Region的最大大小。默认是10GB |
- 当单个Region大小超过了10GB,就会被HBase拆分成为2个Region。采用这种策略后的集群中的Region大小很平均。由于这种策略太简单了,所以不再详细解释了。
2)IncreasingToUpperBoundRegionSplitPolicy (0.94版本后默认)
-
0.94版本之后,有了IncreasingToUpperBoundRegionSplitPolicy策略。这种策略从名字上就可以看出是限制不断增长的文件尺寸的策略。依赖以下公式来计算:
-
Math.min(tableRegionsCounts^3initialSize,defaultRegionMaxFileSize)
-
tableRegionCount: 表在所有RegionServer上所拥有的Region数量总和。initialSize:如果定义了hbase.increasion.policy.initial.size,则使用这个数值。
-
如果没有定义,就用memstore的刷写大小的2倍,hbase.hregion.memstore.flush.size*2
-
defaultRegionMaxFileSize : ConstantSizeRegionSplitPolicy所用到的hbase.hregion.max.filesize,即Region最大大小。
-
假如hbase.hregion.memstore.flush.size定义为128MB,那么文件尺寸的上限增长将是这样:
-
(1). 刚开始只有一个region的时候,上限是256MB,因为1^3*128*2=256MB。
-
(2).当有2个region的时候,上限是2GB,因为2^3*128*2=2048MB。
-
(3).当有3个文件的时候,上限是6.75GB,因为3^3*128*2=6912MB。
-
(4).以此类推,直到计算出来的上限达到hbase.hregion.max.filesize region所定义的10GB。
走趋势如下图:

-
当Region个数达到4个的时候由于计算出来的上限已经达到了16GB,已经大于10GB了,所以后面当Region数量再增加的时候文件大小上限已经不会增加了。在最新的版本里IncreasingToUpperBoundRegionSplitPolicy是默认的配置。
3)KeyPrefixRegionSplitPolicy(扩展内容)
- 除了简单粗暴地根据大小来拆分,我们还可以自己定义拆分点。KeyPrefixRegionSplitPolicy是 IncreasingToUpperBoundRegionSplitPolicy的子类,在前者的基础上,增加了对拆分点(splitPoint,拆分点就是Region被拆分处的rowkey)的定义。它保证了有相同前缀的rowkey不会被拆分到两个不同的Region里面。这个策略用到的参数如下:
| KeyPrefixRegionSplitPolicy.prefix_length | rowkey的前缀长度 |
-
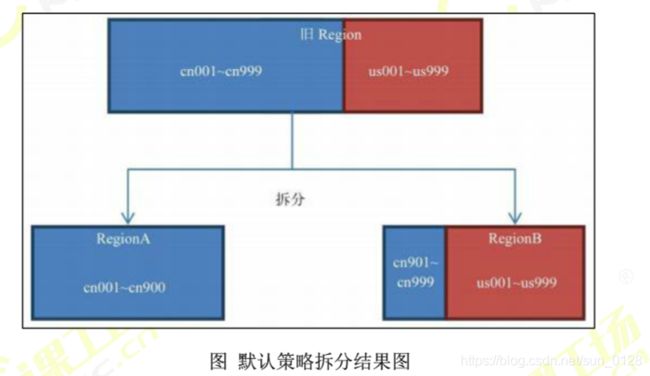
该策略会跟据KeyPrefixRegionSplitPolicy.prefix_length所定义的长度来截取rowkey作为分组的依据,同一个组的数据不会被划分到不同的Region上。比如rowkey都是16位的,指定前5位是前缀,那么前5位相同的rowkey在进行region split的时候会分到相同的region中。用默认策略拆分跟用KeyPrefixRegionSplitPolicy拆分的区别如下。
-
使用默认策略拆分的结果如图。
-
用KeyPrefixRegionSplitPolicy(前2位)拆分的结果如图。
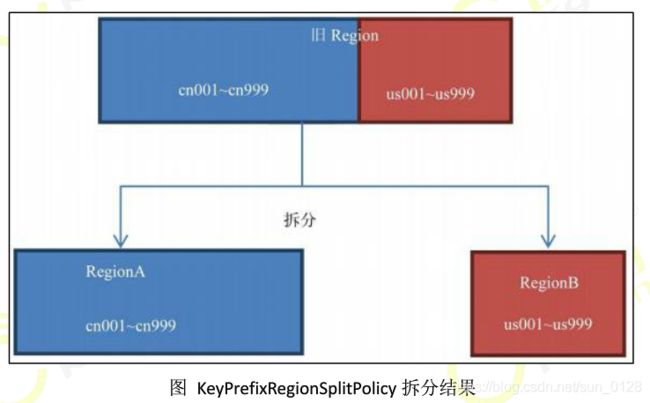
-
如果你的所有数据都只有一两个前缀,那么KeyPrefixRegionSplitPolicy就无效了,此时采用默认的策略较好。如果你的前缀划分的比较细,你的查询就比较容易发生跨Region查询的情况,此时采用KeyPrefixRegionSplitPolicy较好。
-
所以这个策略适用的场景是:数据有多种前缀。查询多是针对前缀,比较少跨略多个前缀来查询数据。
4)DelimitedKeyPrefixRegionSplitPolicy(扩展内容)
- 该策略也是继承自IncreasingToUpperBoundRegionSplitPolicy,它也是根据你的Rowkey前缀来进行切分的。唯一的不同就是:KeyPrefixRegionSplitPolicy是根据rowkey的固定前几位字符来进行判断,而DelimitedKeyPrefixRegionSplitPolicy是根据分隔符来判断的。有时候rowkey的前缀可能不一定都是定长的,比如你拿服务器的名字来当前缀,有的服务器叫host12有的叫host1。这些场景下严格地要求所有前缀都定长可能比较难,而且这个定长如果未来想改也不容易。DelimitedKeyPrefixRegionSplitPolicy就给了你一个定义长度字符前缀的自由。使用这个策略需要在表定义中加入以下属性:
DelimitedKeyPrefixRegionSplitPolicy.delimiter:前缀分隔符。比如你定义了前缀分隔符为_,那么host1_001和host12_999的前缀就分别是host1和host12。
5)BusyRegionSplitPolicy(扩展内容)
- 此前的拆分策略都没有考虑热点问题。所谓热点问题就是数据库中的Region被访问的频率并不一样,某些Region在短时间内被访问的很频繁,承载了很大的压力,这些Region就是热点Region。BusyRegionSplitPolicy就是为了解决这种场景而产生的。它是如何判断哪个Region是热点的呢。先要介绍它用到的参数:
- hbase.busy.policy.blockedRequests:请求阻塞率,即请求被阻带的严重程度。取值范围是0.0~1.0,默认是0.2,即20%的请求被阻塞的意思。
- hbase.busy.policy.minAge:拆分最小年龄,当Region的年龄比这个小的时候不拆分,这是为了防止在判断是否要拆分的时候出现了短时间的访问频率波峰,结果没必要拆分的Region被拆分了,因为短时间的波峰会很快地降回到正常水平。单位毫秒,默认值是600000,即10分钟。
- hbase.busy.policy.aggWindow:计算是否繁忙的时间窗口,单位毫秒,默认值是300000,即5分钟。用以控制计算的频率。计算该Region是否繁忙的计算方法如下:
- 如果“当前时间 - 上次检测时间 >=hbase.busy.policy.aggWindow”,则进行如下计算:这段时间被阻塞的请求/这段时间的总请求=请求的被阻塞率(aggBlockedRate)
- 如果“aggBlockedRate > hbase.busy.policy.blockedRequests”,则判断该Region为繁忙。
- 如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个。
6)DisableRegionSplitPolicy
- 这种策略其实不是一种策略。如果你看这个策略的源码会发现就一个方法shouldSplit,并且永远返回false。设置成这种策略就是Region永不自动拆分。如果使用DisableRegionSplitPolicy让Region永不自动拆分之后,你依然可以通过手动拆分来拆分Region。这个策略有什么用,无论你设置了哪种拆分策略,一开始数据进入Hbase的时候都只会往一个Region塞数据。必须要等到一个Region的大小膨胀到某个阀值的时候才会根据拆分策略来进行拆分。但是当大量的数据涌入的时候,可能会出现一边拆分一边写入大量数据的情况,由于拆分要占用大量IO,有可能对数据库造成一定的压力。如果你事先就知道这个Table应该按怎样的策略来拆分Region的话,你也可以事先定义拆分点(SplitPoint)。所谓拆分点就是拆分处的rowkey,比如你可以按26字母来定义25个拆分点,这样数据一到HBase就会被分配到各自所属的Region里面。这时候我们可以把自动拆分关掉,只用手动拆分。手动拆分有两种情况:预拆分(pre-splitting)和强制拆分(forced splits)。
九.为什么HBase查询比较快
- 主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree)+HTable(region分区)+Cache决定
- 客户端可以直接定位到要查数据所在的Hregion-server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的
- Hbase会将数据保存到内存中,在内存中的数据是有序的,如果内存空间满了,会刷写到HFile中,而在HFile中保存的内容也是有序的.当数据写入HFile后,内存中的数据会被丢弃.HFile文件为磁盘顺序读取做了优化
- Hbase的写入速度快是因为他其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile.所以在客户端看来,写入数据速度很快.另外,写入时候随机写入转换成顺序写,数据写入速度也很稳定.读取速度很快是因为他使用了LSM树形结构,而不是B或B+树. 磁盘顺序读取速度很快,但是相比而言,寻找磁道的速度就要慢很多.Hbase的存储结构导致他需要磁盘寻道时间在可预测范围内,并且读取与所要查询的rowkey连续的任意数量的记录都不会引发额外的寻道开销.比如有五个存储文件,那么最多需要5次磁盘寻道就可以.而关系型数据库,即使有索引,也无法确定磁盘寻道次数. 而且.HBase读取首先会在缓存(BlockCache)中查找,它采用了LRU(最近最少使用算法),如果缓存中没找到,会从内存中的MemStore中查找,只有这两个地方都找不到时,才会加载HFile中的内容