数据仓库经典销售案例
文章目录
- 一、业务库
-
- 1.1 数据模型
- 1.2生成数据
- 二、数据仓库
-
- 2.1 模型搭建
-
- 2.1.1 选择业务流程
- 2.1.2 粒度
- 2.1.3 确认维度
- 2.1.4 确认事实
-
- 2.1.4.1 建立物理模型
- 2.1.4.2 建库、装载数据
- 三.编写脚本配合 crontab 命令实现 ETL 自动化
一、业务库
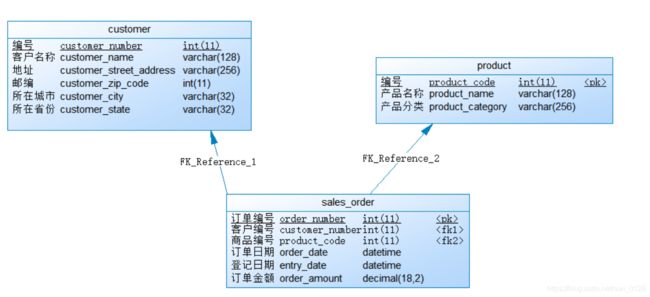
1.1 数据模型
- 源系统是 mysql 库,数据模型如下
1.2生成数据
-- 建库
CREATE DATABASE IF NOT EXISTS sales_source DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
-- 用库
USE sales_source;
-- 删表
DROP TABLE IF EXISTS customer;
DROP TABLE IF EXISTS product;
DROP TABLE IF EXISTS sales_order;
-- 建表
-- customer表
CREATE TABLE customer
(
customer_number INT(11) NOT NULL AUTO_INCREMENT,
customer_name VARCHAR(128) NOT NULL,
customer_street_address VARCHAR(256) NOT NULL,
customer_zip_code INT(11) NOT NULL,
customer_city VARCHAR(32) NOT NULL,
customer_state VARCHAR(32) NOT NULL,
PRIMARY KEY (customer_number)
);
-- product表
CREATE TABLE product
(
product_code INT(11) NOT NULL AUTO_INCREMENT,
product_name VARCHAR(128) NOT NULL,
product_category VARCHAR(256) NOT NULL,
PRIMARY KEY (product_code)
);
-- sales_order表
CREATE TABLE sales_order
(
order_number INT(11) NOT NULL AUTO_INCREMENT,
customer_number INT(11) NOT NULL,
product_code INT(11) NOT NULL,
order_date DATETIME NOT NULL,
entry_date DATETIME NOT NULL,
order_amount DECIMAL(18,2) NOT NULL,
PRIMARY KEY (order_number)
);
-- 插入数据
-- customer表插入数据
INSERT INTO customer
( customer_name
, customer_street_address
, customer_zip_code
, customer_city
, customer_state
)
VALUES
('Big Customers', '7500 Louise Dr.', '17050',
'Mechanicsburg', 'PA')
, ( 'Small Stores', '2500 Woodland St.', '17055',
'Pittsburgh', 'PA')
, ('Medium Retailers', '1111 Ritter Rd.', '17055',
'Pittsburgh', 'PA'
)
, ('Good Companies', '9500 Scott St.', '17050',
'Mechanicsburg', 'PA')
, ('Wonderful Shops', '3333 Rossmoyne Rd.', '17050',
'Mechanicsburg', 'PA')
, ('Loyal Clients', '7070 Ritter Rd.', '17055',
'Pittsburgh', 'PA')
;
-- product表插入数据
INSERT INTO product(product_name,product_category) VALUES
('Hard Disk','Storage'),
('Floppy Drive','Storage'),
('lcd panel','monitor')
;
-- 使用存储过程生成一个临时表,然后向sales_order表插入数据
-- 如果存在则删除存储过程
DROP PROCEDURE IF EXISTS usp_generate_order_data;
-- 创建存储过程
DELIMITER //
CREATE PROCEDURE usp_generate_order_data()
BEGIN
DROP TABLE IF EXISTS tmp_sales_order;
CREATE TABLE tmp_sales_order AS SELECT * FROM sales_order WHERE 1=0;
SET @start_date := UNIX_TIMESTAMP('2018-1-1');
SET @end_date := UNIX_TIMESTAMP('2018-11-23');
SET @i := 1;
WHILE @i<=100000 DO
SET @customer_number := FLOOR(1+RAND()*6);
SET @product_code := FLOOR(1+RAND()* 3);
SET @order_date := FROM_UNIXTIME(@start_date+RAND()*(@end_date-@start_date));
SET @amount := FLOOR(1000+RAND()*9000);
INSERT INTO tmp_sales_order VALUES (@i,@customer_number,@product_code,@order_date,@order_date,@amount);
SET @i := @i +1;
END WHILE;
TRUNCATE TABLE sales_order;
INSERT INTO sales_order
SELECT NULL,customer_number,product_code,order_date,entry_date,order_amount
FROM tmp_sales_order;
COMMIT;
DROP TABLE tmp_sales_order;
END //
-- 调用存储过程插入数据
CALL usp_generate_order_data();
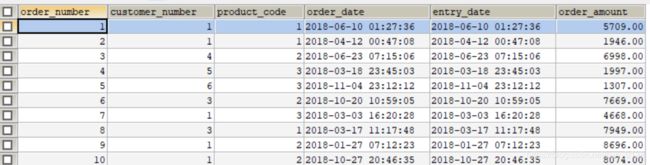
- 建完库后的表和数据如下:


二、数据仓库
- 数仓是建立在 hive 上,有两层(ODS 层 rds 库)和 DW 层(tds 库),存储格式日期维度 textfile,其他 orc。
2.1 模型搭建
- 星型模式是维度模型最简单的形式,也是比较常用的模型,我们的案例采用星型模型。所谓星型模型就是以一个事实表为中心,周围围绕多个维度表。
- 对维度表做进一步规范化后形成的模型叫雪花模型,含有很多维度表的星型模型有时被称为蜈蚣模型,蜈蚣模型的维表往往只有很少的几个属性,这样可以简化维度表的维护,但同时查询数据的时候会有很多的表连接,严重时会使模型难以使用,因此要尽量避免这种模型。
- 星型模型将业务分为事实和维度。
- 事实是业务数据的度量值,比如销售额、销售数量等,它记录了特定事件的量化指标,一般是度量值和指向维表的外键组成。
- 事实表的粒度级别通常会设计的比较低,事实表有三种类型:
- 事务事实表:最低粒度级别的事实表,记录原始的操作型事件.
- 快照事实表:记录给定时间点的事实,如月底账户余额
- 累积事实表:记录给定事件点的聚合事实,如当月的销售金额.
- 维度是对事实数据属性的描述,如日期,省份,地区等,维度表的数据量通常不大,常用的维度表有:
- 时间维度表,每个数据仓库都需要一个时间维度表。
- 地理维度表:描述位置信息的数据,如国家,省份,城市,区县,邮编等
- 产品维度表:描述产品及其属性
- 人员维度表:描述人员相关信息,部门员工表等
- 范围维度表:描述分段数据的信息等,比如信用等级
- 代理键:一般事实表和维表都有主键,仍会设置一个代理键,所谓代理键说白了即是业务无关的自增主键,因为维表的主键有可能会产生变化,即变化维.
- 星型模型是非规范化的,不受关系数据库的范式规则的约束,当所有的维度进行规范化后也叫做”雪花化”,就是雪花模型了,具体的做法是将低基数(维表中的行数少,比如性别)的属性从维度表中移除并形成单独的维表,维表就具有了层次关系(父子),减少了维表数据的冗余,因此大数据量下雪花比星型节省空间,但是相对的查询要关联的表多,因此也就变的复杂.有些设计底层使用雪花模型,上层用表连接简历视图模拟星型模型,这种方式通过对维度的规范化节省了空间,同时又对用户屏蔽了查询的复杂性,但是视图对于查询效率的提升相对于联合查询来说并没有得到提升,对开发效率有提升,性能有损失
2.1.1 选择业务流程
- 维度方法的基础是首先确认哪些业务处理流程是数据库需要覆盖的,因此建模的第一个步骤是描述需要建模的业务流程,描述业务流程,可以简单的使用文本记录下或者使用 MPMN(业务流程建模标注)的方法,也可以使用 UML 等.
我们的案例业务很明确就是:销售订单
2.1.2 粒度
- 粒度用于确定事实表中表示的是什么,在选择事实表存储最细粒度的事务记录,每小时更新增量,凌晨 2 两点更新昨天全量
2.1.3 确认维度
- 产品、客户以及日期,日期维度用于业务集成,每个数据仓库都应该有一个日期维度,日期维度数据一旦生成就不会改变,因此不需要版本号、生效日期和过期日期,一般情况下直接生成 10 年或者 20 年的数据,初始化的数据远高于数据仓库的有效时长即可。
- 在有变化的维度表上增加版本号、生效日期、过期日期,能看到维度的历史变化,当维度属性发生变化的时候,根据不同的策略,生成一条新的维度记录或者更改原记录。渐变维 slow changing dimensions SCD代理键是维度表的主键,一般加 sk 表示即 surrogate key,是每行记录的唯一标识,由系统生成的主键,不是应用数据,没有业务含义.
2.1.4 确认事实
- 订单是唯一事实,订单金额是唯一度量,按天分区。
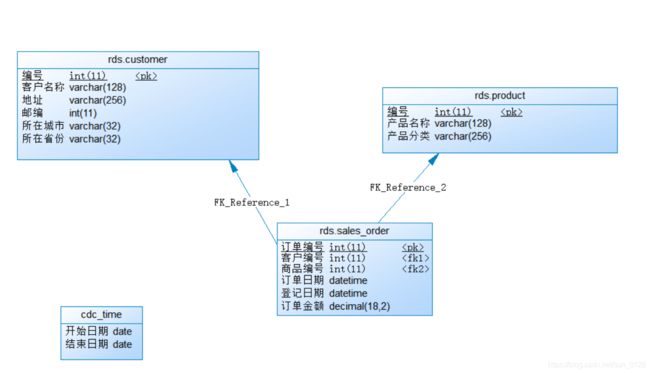
2.1.4.1 建立物理模型
- rds层
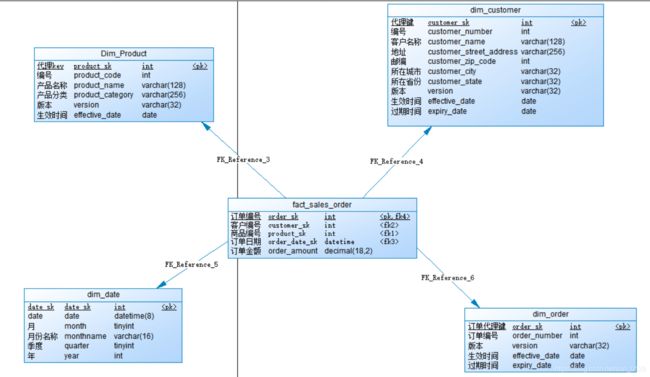
- dw层
2.1.4.2 建库、装载数据
- rds层建库建表
-- 创建rds层数据库
create database sales_rds;
-- 使用库
USE sales_rds;
-- 删除表
DROP TABLE IF EXISTS rds.customer;
DROP TABLE IF EXISTS rds.product;
DROP TABLE IF EXISTS rds.sales_order;
drop table if exists cdc_time;
-- 创建sales_rds.customer表
CREATE TABLE sales_rds.customer
(
customer_number INT ,
customer_name VARCHAR(128) ,
customer_street_address VARCHAR(256) ,
customer_zip_code INT ,
customer_city VARCHAR(32) ,
customer_state VARCHAR(32)
);
-- 创建sales_rds.product表
CREATE TABLE sales_rds.product
(
product_code INT,
product_name VARCHAR(128) ,
product_category VARCHAR(256)
);
-- 创建sales_rds.sales_order表
CREATE TABLE sales_rds.sales_order
(
order_number INT ,
customer_number INT,
product_code INT ,
order_date timestamp ,
entry_date timestamp ,
order_amount DECIMAL(18,2)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
;
-- cdc表
create table cdc_time
(
start_time date,
end_time date
);
- 从mysql中向hive的rds层导入数据
# 加载数据导入rds层
# ETL抽取
# 全量抽取
# 全量导入product表
sqoop import \
--connect jdbc:mysql://localhost:3306/sales_source \
--username root \
--password ok \
--table product \
--hive-import \
--hive-table sales_rds.product \
--hive-overwrite \
--target-dir temp
#全量导入customer表
sqoop import \
--connect jdbc:mysql://localhost:3306/sales_source \
--username root \
--password ok \
--table customer \
--hive-import \
--hive-table sales_rds.customer \
--hive-overwrite \
--target-dir temp
#增量抽取sales_order
#检查列
#模式append/lastmodefied
#last-value
sqoop job \
--create myjob \
-- import \
--connect jdbc:mysql://localhost:3306/sales_source \
--username root \
--password ok \
--table sales_order \
--hive-import \
--hive-table sales_rds.sales_order \
--check-column entry_date \
--incremental append \
--last-value '1900-1-1'
#查看sqoop job
sqoop job --list
#执行job
sqoop job --exec myjob
- dw层建库建表
-- 创建dw层数据库
create database sales_dw;
-- 使用库
use sales_dw;
-- 创建dim_product表
create table dim_product
(
product_sk int ,
product_code int ,
product_name varchar(128),
product_category varchar(256),
version varchar(32),
effective_date date,
expiry_date date
)
clustered by (product_sk ) into 8 buckets
stored as orc tblproperties('transactional'='true');
-- dim_customer表
create table dim_customer
(
customer_sk int ,
customer_number int ,
customer_name varchar(128),
customer_street_address varchar(256),
customer_zip_code int,
customer_city varchar(32),
customer_state varchar(32),
version varchar(32),
effective_date date,
expiry_date date
)
clustered by (customer_sk ) into 8 buckets
stored as orc tblproperties('transactional'='true');
-- dim_date表
create table dim_date
(
date_sk int ,
date date,
month tinyint,
month_name varchar(16),
quarter tinyint,
year int
) row format delimited fields terminated by ','
stored as textfile;
-- dim_order表
create table dim_order
(
order_sk int ,
order_number int,
version varchar(32),
effective_date date,
expiry_date date
)
clustered by (order_sk ) into 8 buckets
stored as orc tblproperties('transactional'='true');
-- fact_sales_order表
create table fact_sales_order
(
order_sk int ,
customer_sk int ,
product_sk int ,
order_date_sk int ,
order_amount decimal(18,2)
)
partitioned by(order_date string)
clustered by (order_sk ) into 8 buckets
stored as orc tblproperties('transactional'='true');
- 从rds层向dw层导入数据
- 1.编写生成日期数据的脚本
vi generate_dim_date.sh
- 内容如下:
#!/bin/bash
#起始日期
date1=$1
#终止日期
date2=$2
#日期
tmpdate=`date -d "$date1" +%F`
#开始时间戳
startSec=`date -d "$date1" +%s`
#终止时间戳
endSec=`date -d "$date2" +%s`
#循环起始值
min=1
#循环终止值
max=`expr \( $endSec - $startSec \) \/ 60 \/ 60 \/ 24`
while [ $min -le $max ]
do
#计算月份
month=`date -d "$tmpdate" +%m`
#计算月英文名称
month_name=`date -d "$tmpdate" +%B`
#计算年
year=`date -d "$tmpdate" +%Y`
#计算季度
#quarter=`expr \( $month - 1 \) \/ 3 + 1`
quarter=`expr \( $month - 1 \) \/ 3 + 1`
echo "$min,$tmpdate,$month,$month_name,$quarter,$year" >> ./dim_date.csv
#计算下次日期
tmpdate=`date -d "$min day $date1" +%F`
#计算下次时间戳
startSec=`date -d "$min day $date1" +%s`
min=`expr $min + 1`
done
#赋权
chmod 777 generate_dim_date.sh
#执行脚本
./generate_dim_date.sh
#上传生成文件至hive的dim_date表目录下,即加载数据
hdfs dfs -put dim_date.csv /hive/warehouse/sales_dw.db/dim_date
-- 加载dim_product
from
(
select
row_number() over(order by sp.product_code) product_sk,
sp.product_code,
sp.product_name,
sp.product_category,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.product sp ) tmp
insert into sales_dw.dim_product select *;
-- 加载dim_customer
from
(
select
row_number() over(order by sp.customer_number) customer_sk,
sp.customer_number,
sp.customer_name,
sp.customer_street_address,
sp.customer_zip_code,
sp.customer_city,
sp.customer_state,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.customer sp ) tmp
insert into sales_dw.dim_customer select *;
-- 加载dim_order
from
(
select
row_number() over(order by sp.order_number) order_sk,
sp.order_number,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.sales_order sp ) tmp
insert into sales_dw.dim_order select *;
-- 加载fact_sales_order表
-- 设置动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
-- 加载数据
from
(
select
b.order_sk,
c.customer_sk,
d.product_sk,
e.date_sk order_date_sk,
a.order_amount,
substr(a.order_date,1,7) order_date
from sales_rds.sales_order a
join sales_dw.dim_order b on a.order_number=b.order_number
join sales_dw.dim_customer c on a.customer_number=c.customer_number
join sales_dw.dim_product d on a.product_code=d.product_code
join sales_dw.dim_date e on date(a.order_date)=e.date
) temp
insert into table sales_dw.fact_sales_order partition(order_date)
select order_sk,customer_sk,product_sk,order_date_sk,order_amount,order_date;
-- dm层 宽表 想求2018 10月20号这一天的指标
-- 顾客,产品,日期,当天订单个数,当天的订单金额,近两天的订单个数,近两天的订单金额
create database if not exists sales_dm;
create table if not exists sales_dm.dm_order as
select
c.customer_sk ,
c.customer_number ,
c.customer_name ,
c.customer_street_address ,
c.customer_zip_code ,
c.customer_city ,
c.customer_state ,
p.product_sk ,
p.product_code ,
p.product_name ,
p.product_category,
dd.date_sk,
dd.date ,
dd.month ,
dd.month_name ,
dd.quarter ,
dd.year ,
sum(case when datediff("2018-10-20",dd.date)=0 then 1 else 0 end) one_order_cnt,
sum(case when datediff("2018-10-20",dd.date)<=1 then 1 else 0 end) two_order_cnt,
sum(case when datediff("2018-10-20",dd.date)<=0 then fso.order_amount else 0 end) one_order_cnt_amount,
sum(case when datediff("2018-10-20",dd.date)<=1 then 1 else 0 end) two_order_cnt_amount
from sales_dw.fact_sales_order fso
join sales_dw.dim_customer c on fso.customer_sk=c.customer_sk
join sales_dw.dim_product p on fso.product_sk=p.product_sk
join sales_dw.dim_date dd on fso.order_date_sk=dd.date_sk
where dd.date>='2018-10-19' and dd.date<='2018-10-20'
group by
c.customer_sk ,
c.customer_number ,
c.customer_name ,
c.customer_street_address ,
c.customer_zip_code ,
c.customer_city ,
c.customer_state ,
p.product_sk ,
p.product_code ,
p.product_name ,
p.product_category,
dd.date_sk,
dd.date ,
dd.month ,
dd.month_name ,
dd.quarter ,
dd.year;
三.编写脚本配合 crontab 命令实现 ETL 自动化
➢ 初始化装载
USE sales_dw;
-- 清空表
TRUNCATE TABLE dim_customer;
TRUNCATE TABLE dim_product;
TRUNCATE TABLE dim_order;
TRUNCATE TABLE fact_sales_order;
-- 装载客户维度表
from
(
select
row_number() over(order by sp.customer_number) customer_sk,
sp.customer_number,
sp.customer_name,
sp.customer_street_address,
sp.customer_zip_code,
sp.customer_city,
sp.customer_state,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.customer sp ) tmp
insert into sales_dw.dim_customer select *;
-- 装载产品维度表
from
(
select
row_number() over(order by sp.product_code) product_sk,
sp.product_code,
sp.product_name,
sp.product_category,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.product sp ) tmp
insert into sales_dw.dim_product select *;
-- 装载订单维度表
from
(
select
row_number() over(order by sp.order_number) order_sk,
sp.order_number,
'1.0',
'2018-1-1',
'2050-1-1'
from sales_rds.sales_order sp ) tmp
insert into sales_dw.dim_order select *;
-- 装载销售订单事实表
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
from
(
select
b.order_sk,
c.customer_sk,
d.product_sk,
e.date_sk order_date_sk,
a.order_amount,
substr(a.order_date,1,7) order_date
from sales_rds.sales_order a
join sales_dw.dim_order b on a.order_number=b.order_number
join sales_dw.dim_customer c on a.customer_number=c.customer_number
join sales_dw.dim_product d on a.product_code=d.product_code
join sales_dw.dim_date e on date(a.order_date)=e.date
) temp
insert into table sales_dw.fact_sales_order partition(order_date)
select order_sk,customer_sk,product_sk,order_date_sk,order_amount,order_date;
#!/bin/bash
# 建立Sqoop增量导入作业,以order_number作为检查列,初始的last-value是0
sqoop job --delete rds_incremental_import_job
sqoop job --create rds_incremental_import_job \
-- \
import \
--connect jdbc:mysql://localhost:3306/sales_source \
--username root \
--password ok \
--table sales_order \
--hive-import \
--hive-table sales_rds.sales_order \
--fields-terminated-by '\t' \
--lines-terminated-by '\n' \
--incremental append \
--check-column order_number \
--last-value 0
# 首次抽取,将全部数据导入RDS库
sqoop import --connect jdbc:mysql://localhost:3306/sales_source \
--username root --password ok --table customer --hive-import --hive-table sales_rds.customer --hive-overwrite --target-dir temp
sleep 2
sqoop import --connect jdbc:mysql://localhost:3306/sales_source --username root --password ok --table product --hive-import --hive-table sales_rds.product --hive-overwrite --target-dir temp
beeline -u jdbc:hive2://hadoop01:10000/sales_dw -e "TRUNCATE TABLE sales_rds.sales_order"
# 执行增量导入,因为last-value初始值为0,所以此次会导入全部数据
sqoop job --exec rds_incremental_import_job
# 调用init_etl.sql文件执行初始装载
spark-sql --master yarn-client -f init_dw_etl.sql
➢ 定期装载
- 涉及到update操纵需要更改hive-site.xml文件,添加支持事务操作,添加如下属性
<property>
<name>hive.optimize.sort.dynamic.partitionname>
<value>falsevalue>
property>
<property>
<name>hive.support.concurrencyname>
<value>truevalue>
property>
<property>
<name>hive.enforce.bucketingname>
<value>truevalue>
property>
<property>
<name>hive.exec.dynamic.partition.modename>
<value>nonstrictvalue>
property>
<property>
<name>hive.txn.managername>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManagervalue>
property>
<property>
<name>hive.compactor.initiator.onname>
<value>truevalue>
property>
<property>
<name>hive.compactor.worker.threadsname>
<value>1value>
property>
-- 设置scd的生效时间和过期时间
use sales_dw;
SET hivevar:cur_date = CURRENT_DATE();
SET hivevar:pre_date = DATE_ADD(${hivevar:cur_date},-1);
SET hivevar:max_date = CAST('2050-01-01' AS DATE);
-- 设置cdc的开始结束日期
INSERT overwrite TABLE sales_rds.cdc_time
SELECT end_time, ${hivevar:cur_date} FROM sales_rds.cdc_time;
-- 装载customer维度
-- 获取源数据中被删除的客户和地址发生改变的客户,将这些数据设置为过期时间,即当前时间的前一天
UPDATE dim_customer SET expiry_date = ${hivevar:pre_date}
WHERE dim_customer.customer_sk IN(SELECT
a.customer_sk
FROM (SELECT
customer_sk,
customer_number,
customer_street_address
FROM dim_customer
WHERE expiry_date = ${hivevar:max_date}) a
LEFT JOIN sales_rds.customer b ON a.customer_number = b.customer_number
WHERE b.customer_number IS NULL
OR a.customer_street_address <> b.customer_street_address);
-- 装载product维度
-- 取源数据中删除或者属性发生变化的产品
UPDATE dim_product
SET expiry_date = ${hivevar:pre_date}
WHERE dim_product.product_sk IN(SELECT a.product_sk
FROM(SELECT product_sk,
product_code,
product_name,
product_category
FROM dim_product
WHERE expiry_date = ${hivevar:max_date}) a
LEFT JOIN sales_rds.product b ON a.product_code = b.product_code
WHERE b.product_code IS NULL
OR (a.product_name <> b.product_name OR a.product_category <> b.product_category));
-- 将有地址变化的插入到dim_customer表,如果有相同数据存在有不过期的数据则不插入
INSERT INTO dim_customer
SELECT row_number() over (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
t1.version,
t1.effective_date,
t1.expiry_date
FROM(SELECT
t2.customer_number customer_number,
t2.customer_name customer_name,
t2.customer_street_address customer_street_address,
t2.customer_zip_code,
t2.customer_city,
t2.customer_state,
t1.version + 1 `version`,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM dim_customer t1
INNER JOIN sales_rds.customer t2 ON t1.customer_number = t2.customer_number
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN dim_customer t3 ON t1.customer_number = t3.customer_number
AND t3.expiry_date = ${hivevar:max_date}
WHERE t1.customer_street_address <> t2.customer_street_address
AND t3.customer_sk IS NULL
) t1
CROSS JOIN(SELECT COALESCE(MAX(customer_sk),0) sk_max FROM dim_customer) t2;
-- 处理customer_name列上的scd1,覆盖
-- 不进行更新,将源数据中的name列有变化的数据提取出来,放入临时表
-- 将 dim_couster中这些数据删除、
-- 将临时表中的数据插入
DROP TABLE IF EXISTS tmp;
CREATE TABLE tmp AS
SELECT a.customer_sk,
a.customer_number,
b.customer_name,
a.customer_street_address,
a.customer_zip_code,
a.customer_city,
a.customer_state,
a.version,
a.effective_date,
a.expiry_date
FROM dim_customer a
JOIN sales_rds.customer b ON a.customer_number = b.customer_number
where a.customer_name != b.customer_name;
-- 删除数据
DELETE FROM
dim_customer WHERE
dim_customer.customer_sk IN (SELECT customer_sk FROM tmp);
-- 插入数据
INSERT INTO dim_customer
SELECT * FROM tmp;
-- 处理新增的customer记录
INSERT INTO dim_customer
SELECT row_number() over (ORDER BY t1.customer_number) + t2.sk_max,
t1.customer_number,
t1.customer_name,
t1.customer_street_address,
t1.customer_zip_code,
t1.customer_city,
t1.customer_state,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM( SELECT t1.*
FROM sales_rds.customer t1
LEFT JOIN dim_customer t2 ON t1.customer_number = t2.customer_number
WHERE t2.customer_sk IS NULL) t1
CROSS JOIN(SELECT
COALESCE(MAX(customer_sk),0) sk_max
FROM dim_customer) t2;
-- 处理product_name、product_category列上scd2的新增行
INSERT INTO dim_product
SELECT row_number() over (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
t1.version,
t1.effective_date,
t1.expiry_date
FROM( SELECT t2.product_code product_code,
t2.product_name product_name,
t2.product_category product_category,
t1.version + 1 `version`,
${hivevar:pre_date} effective_date,
${hivevar:max_date} expiry_date
FROM dim_product t1
INNER JOIN sales_rds.product t2 ON t1.product_code = t2.product_code
AND t1.expiry_date = ${hivevar:pre_date}
LEFT JOIN dim_product t3 ON t1.product_code = t3.product_code
AND t3.expiry_date = ${hivevar:max_date}
WHERE(t1.product_name <> t2.product_name
OR t1.product_category <> t2.product_category)
AND t3.product_sk IS NULL
) t1
CROSS JOIN (SELECT COALESCE(MAX(product_sk),0) sk_max
FROM dim_product) t2;
-- 处理新增的 product 记录
INSERT INTO dim_product
SELECT row_number() over (ORDER BY t1.product_code) + t2.sk_max,
t1.product_code,
t1.product_name,
t1.product_category,
1,
${hivevar:pre_date},
${hivevar:max_date}
FROM( SELECT t1.*
FROM sales_rds.product t1
LEFT JOIN dim_product t2 ON t1.product_code = t2.product_code
WHERE t2.product_sk IS NULL
) t1
CROSS JOIN (SELECT COALESCE(MAX(product_sk),0) sk_max
FROM dim_product) t2;
-- 装载order维度
INSERT INTO dim_order
SELECT row_number() over (ORDER BY t1.order_number) + t2.sk_max,
t1.order_number,
t1.version,
t1.effective_date,
t1.expiry_date
FROM( SELECT order_number order_number,
1 `version`,
order_date effective_date,
'2050-01-01' expiry_date
FROM sales_rds.sales_order, sales_rds.cdc_time
WHERE entry_date >= end_time AND entry_date < start_time ) t1
CROSS JOIN( SELECT COALESCE(MAX(order_sk),0) sk_max
FROM dim_order) t2;
-- 装载销售订单事实表
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions=10000;
set hive.exec.max.dynamic.partitions.pernode=10000;
from
(
select
b.order_sk,
c.customer_sk,
d.product_sk,
e.date_sk order_date_sk,
a.order_amount,
substr(a.order_date,1,7) order_date
from sales_rds.sales_order a
join sales_dw.dim_order b on a.order_number=b.order_number
join sales_dw.dim_customer c on a.customer_number=c.customer_number
join sales_dw.dim_product d on a.product_code=d.product_code
join sales_dw.dim_date e on date(a.order_date)=e.date,
sales_rds.cdc_time f
where a.order_date >= c.effective_date
AND a.order_date < c.expiry_date
AND a.order_date >= d.effective_date
AND a.order_date < d.expiry_date
AND a.entry_date >= f.end_time
AND a.entry_date < f.start_time
) temp
insert into table sales_dw.fact_sales_order partition(order_date)
select order_sk,customer_sk,product_sk,order_date_sk,order_amount,order_date;
-- 更新时间戳表的字段
INSERT overwrite TABLE sales_rds.cdc_time
SELECT start_time,start_time
FROM sales_rds.cdc_time;
#!/bin/bash
# 整体拉取customer、product表数据
sqoop import --connect jdbc:mysql://localhost:3306/sales_source --username root \
--password ok --table customer --hive-import --hive-table sales_rds.customer --hive-overwrite --target-dir temp
sleep 2
sqoop import --connect jdbc:mysql://localhost:3306/sales_source --username root --password \
ok --table product --hive-import --hive-table sales_rds.product --hive-overwrite --target-dir temp
# 执行增量导入
sqoop job --exec rds_incremental_import_job
# 调用 sql 文件执行定期装载
hive -f schedule_daily_etl.sql
# spark-sql不支持hive事务,不要用下面的语句
#spark-sql --master yarn-client -f schedule_daily_etl.sql
crontab -e 定时任务执行如下:
- crontab