数据迁移工具--Sqoop数据导入
准备一些数据:
在MySQL中新建一个测试库,新建一个表,插入两行数据:
CREATE DATABASE cs;
CREATE TABLE cs.staff(id int(4) primary key not null auto_increment,
name varchar(255),
sex varchar(255)
);
INSERT INTO cs.staff VALUES (1, 'Thomas', 'Male');
INSERT INTO cs.staff VALUES (2, 'Catalina', 'Female');
全部数据导入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--table staff \
--target-dir /user/cs \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"

hdfs中也有了。
命令详解:
--connect 操作数据库用到的工具类:数据库连接
--username 数据库用户
--password 数据库密码
--table 数据库表名
--target-dir hdfs中存储的路径
--delete-target-dir 如果有这个路径,删了他
--num-mappers map任务数
--fields-terminated-by 分隔符
SQL查询导入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--target-dir /user/query \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id<=1 and $CONDITIONS;'

hdfs上的输出。
命令详解:
--query SQL语句,SQL语句中的条件必须加上 and $CONDITIONS
导入指定列
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--table staff \
--target-dir /user/columns \
--columns id,sex \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"

hdfs上的输出。
命令详解:
--columns 选择的列,多列间用 ',' 分隔
参数查询导入
导入指定列+参数查询导入=SQL查询导入
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--table staff \
--target-dir /user/columns \
--columns id,sex \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--where "id=2"

hdfs上的输出
--where 条件,写法和where后的查询条件写法一致 不能和query参数共用
导入数据到Hive
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive
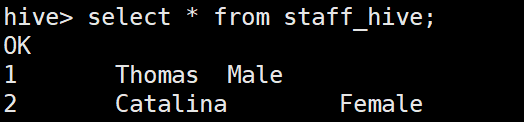
hive输出
命令详解:
整个过程会分为两部分,第一部分是从读取数据库中数据到HDFS上的/user/hdfs/staff
--hive-import 参数开始第二部分,从HDFS上读取到HIVE
--hive-overwrite 表示写入结束,第二部分结束
--hive-table staff_hive 表名叫做staff_hive
导入数据到Hbase
sqoop import \
--connect jdbc:mysql://hadoop01:3306/cs \
--username root \
--password 123456 \
--table staff \
--columns "id,name,sex" \
--column-family "info" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "hbase_company" \
--num-mappers 1 \
--split-by id

hbase上的输出
命令详解:
--column-family 列族字段名
--hbase-create-table 创建hbase表
--hbase-row-key 行键
--hbase-table 表名
--split-by 按照字段进行切分