java集合源码解析:collection
JAVA集合的框架图:
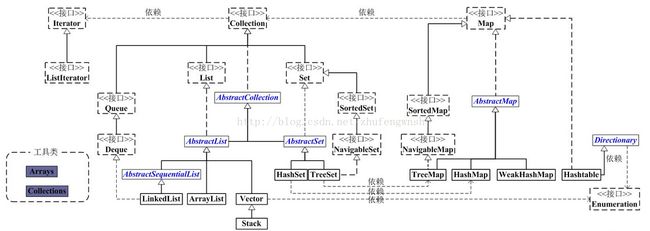
从图中可以看出集合分为collection 和 map 两大类, 其中collection内部主要以数组或者链表的形式存放一系列集合对象,map则是以系列键值对的集合
collection主要包含list 和 set 两个部分,是list和set 高度抽象出来的接口,主要包含add() remove() contains()等集合基本方法,还包含一个iterator() 方法,
依赖iterator接口,可以用来对集合进行遍历
AbstractCollection是一个抽象类, 实现了collection中的部分方法,比如:
public boolean isEmpty() {
return size() == 0;
}
public boolean contains(Object o) {
Iterator e = iterator();
if (o==null) {
while (e.hasNext())
if (e.next()==null)
return true;
} else {
while (e.hasNext())
if (o.equals(e.next()))
return true;
}
return false;
} AbstractList 和 AbstractSet 则分别实现了List 和 Set接口,并都继承自AbstractCollection
List中我们用的最多的是ArrayList和LinkedList , ArrayList内部使用数组实现,而LinkedList则使用链表的方式实现,
先看看ArrayList的部分源码:
private static final int DEFAULT_CAPACITY = 10;
transient Object[] elementData;
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}我们先看看add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}第一个是直接加在数组后面,第二个是加在指定下标的位置,arraylist可以根据下标直接定位,所以查询效率很高,但是在新增和删除的时候,效率非常低
原因是因为新增和删除的时候,如果不是从最后一个下标开始操作,那么需要将指定下标后面所有的元素都进行移动
List list = new ArrayList(100000);
//List list = new LinkedList();
long s1 = System.currentTimeMillis();
for(int i=0; i<100000; i++) {
list.add(0,i);
}
long s2 = System.currentTimeMillis();
System.out.println(s2 - s1);并且随着数组容量增加,所需数量会呈指数级增长,所以我们如果需要对list从中间进行新增,删除操作,那么尽量使用linkedlist
上面这段代码如果把new Arraylist() 直接用new LinkedList()来代替, 两种add方法需要的时间都在几毫秒左右
list每次在新增时,必须先对其容量进行计算, ensureCapacityInternal(size + 1) ,如果超出容量,则需进行扩容
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);//默认初始容量为10,取所需容量和初始容量的最大值
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 当所需容量大于数组初始的长度时,需要进行扩容操作
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 扩容一般为原来的1.5倍,如果还不够,那么直接取所需容量进行操作,进行扩容操作需要对整个数组进行移动,性能较差,所以尽可能确定初始容量
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}再看看linkedlist的源码:
//首先定义了头尾2个节点,这里源码来自jdk1.8,1.6的源码里面是直接定义了一个head节点并且 头尾都指向自己,作为一个双向链表
transient Node first;
transient Node last;
//node节点的定义,其实就是一个指定的对象,再加上前后指针
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} linkedlist由于是基于链表的,没有arraylist里面的扩容操作,新增和删除都只需要修改几个指针的指向就行,所以新增和删除效率高
但是查询的时候,由于没有下标,那么只能通过遍历来进行比较,所以效率非常低
list中的另一个实现:vector,其基本实现原理和arraylist差不多,但是他在很多方法中加入了synchronized来保证线程安全,所以效率低
而且很多情况,这个synchronized其实没法真正保证线程安全(比如size()方法和add(E e)都单独加了同步,但是我们如果需要先判断size()然后再add,那么在多线程的情况下,这2个方法执行的间隙,就有可能被其他线程修改了数据), 所以vector现在基本被弃用了, 如果需要使用线程安全的集合,应该首选java.util.Concurrent下面的相关集合