深入浅出MYSQL,部分知识点小记
MYSQL存储引擎
1、支持的引擎包括:MyISAM\InnoDB\MERGE等等
2、通过两种方法查询:
第一种:SHOW ENGINES
第二种: SHOW VARIABLES LIKE ‘have%’
3、在创建表时可以通过增加ENGINE来设置
CREATE TABLE ai (
i bigint(20) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (i)
) ENGINE=MyISAM DEFAULT CHARSET=gbk;
CREATE TABLE country (
country_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
country VARCHAR(50) NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (country_id)
)ENGINE=InnoDB DEFAULT CHARSET=gbk
4、几种引擎对比
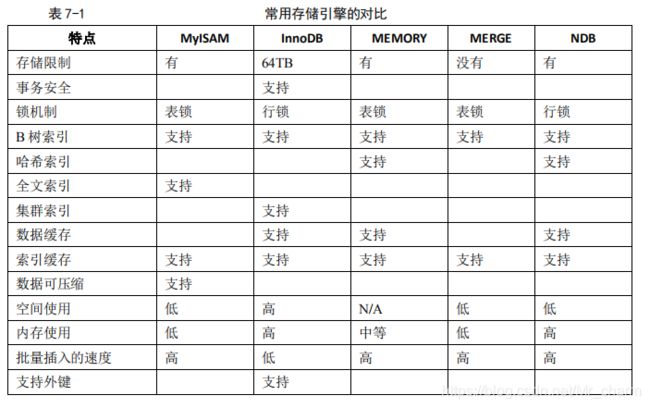
5、主要介绍两个
- MyISAM不支持事务、也不支持外键,优势是访问速度快,表损坏可能导致数据库异常重新启动,需要尽快修复并尽可能地确认损坏的原因。
- InnoDB提供了具有提交、回滚和崩溃恢复能力的事务安全,但他的占用磁盘空间相对更大
6、怎么选择合适的引擎
- 如果应用以读和插入操作为主,很少的更新和删除操作,对事务的完整性、并发性要求不是很高,选择MyISAM,其在Web、数据仓储和其他应用环境下最常使用
- InnoDB用于事务处理应用程序,支持外键,对事务完整性有较高要求,除了插入、查询还包括很多更新、删除操作,类似计费系统,财务系统常常都是用它作为选择
- MERGE:用于将一系列等同的 MyISAM 表以逻辑方式组合在一起,并作为一个对象引用它们。MERGE 表的优点在于可以突破对单个 MyISAM 表大小的限制,并且通过将不同的表分布在多个磁盘上,可以有效地改善MERGE表的访问效率。这对于诸如数据仓储等VLDB环境十分适合。
索引的设计和使用
1、MyISAM和InnoDB存储的表默认创建的都是Btree,但支持前缀索引,即对前N个字符创建索引
2、创建索引语法:create index index_name on table_name(index_col_name,…)
删除索引:DROP INDEX index_name ON tbl_name
3、设计索引的原则:
- 最适合索引的列是在where中或者连接中的指定列,而不是在select 关键字后选择的列
- 索引列的基数越大,索引效果越好,例如不要再性别列创建索引
- 不要过度索引,
- 尽量自己指定主键
BTREE 索引与 HASH 索引
MEMORY 存储引擎的表可以选择使用 BTREE 索引或者 HASH 索引,两种不同类型的索引各有其不同的适用范围。HASH 索引有一些重要的特征需要在使用的时候特别注意,如下所示。
- 只用于使用=或<=>操作符的等式比较。
- 优化器不能使用 HASH 索引来加速 ORDER BY 操作。
- MySQL 不能确定在两个值之间大约有多少行。如果将一个 MyISAM 表改为 HASH 索引的 MEMORY 表,会影响一些查询的执行效率。
- 只能使用整个关键字来搜索一行。
而对于 BTREE 索引,当使用>、<、>=、<=、BETWEEN、!=或者<>,或者 LIKE ‘pattern’(其 中’pattern’不以通配符开始)操作符时,都可以使用相关列上的索引。
下列范围查询适用于 BTREE 索引和 HASH 索引:
SELECT * FROM t1 WHERE key_col = 1 OR key_col IN (15,18,20);
下列范围查询只适用于 BTREE 索引:
SELECT * FROM t1 WHERE key_col > 1 AND key_col < 10;
SELECT * FROM t1 WHERE key_col LIKE 'ab%' OR key_col BETWEEN 'lisa' AND 'simon';
SQL优化
1、利用explain分析低效的SQL执行计划
例如:
explain select sum(moneys) from sales a,company b where a.company_id = b.id and a.year = 2006;

简单解释


创建索引注意点
1、使用索引
- 创建复合索引,对于多列索引,只要查询到最左边的列,索引就会被使用
例:按 company_id,moneys 的顺序创建一个复合索引,具体如下:
create index ind_sales2_companyid_moneys on sales2(company_id,moneys);
2、使用Like的查询,后面是常量且只有%号不在第一个字符内,索引才会被使用
例如:
mysql> explain select * from company2 where name like '%3'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: company2
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra: Using where
1 row in set (0.00 sec)
mysql> explain select * from company2 where name like '3%'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: company2
type: range
possible_keys: ind_company2_name
key: ind_company2_name
key_len: 11
ref: NULL
rows: 103
Extra: Using where
1 row in set (0.00 sec)
常用的几种优化
①大批量插入数据
针对MyISAM 表,用load data infile…这种语句,耗时比较少

针对INnoDB,上面方法没有很高效率,而是通过导入的时候数据按照主键的顺序排列能提高导入效率。
第二是在导入数据前执行 SET UNIQUE_CHECKS=0,关闭唯一性校验,在导入结束后执行SET UNIQUE_CHECKS=1,恢复唯一性校验,可以提高导入的效率。

②优化order by 语句
在某些情况中,MySQL 可以使用一个索引来满足 ORDER BY 子句,而不需要额外的排序。WHERE 条件和 ORDER BY 使用相同的索引,并且 ORDER BY 的顺序和索引顺序相同,并且ORDER BY 的字段都是升序或者都是降序。

③优化OR语句
对于含有 OR 的查询子句,如果要利用索引,则 OR 之间的每个条件列都必须用到索引;如果没有索引,则应该考虑增加索引。
④FORCE INDEX
为强制 MySQL 使用一个特定的索引,可在查询中使用 FORCE INDEX 作为 HINT。例如,当不强制使用索引的时候,因为 id 的值都是大于 0 的,因此 MySQL 会默认进行全表扫描,而不使用索引,如下所示:
mysql> explain select * from sales2 where id > 0
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales2
type: ALL
possible_keys: ind_sales2_id
key: NULL
key_len: NULL
ref: NULL
rows: 1000
Extra: Using where
1 row in set (0.00 sec)
但是,当使用 FORCE INDEX 进行提示时,即便使用索引的效率不是最高,MySQL 还是选择使用了索引,这是 MySQL 留给用户的一个自行选择执行计划的权力。加入 FORCE INDEX 提示后再次执行上面的 SQL:
mysql> explain select * from sales2 force index (ind_sales2_id) where id > 0
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: sales2
type: range
possible_keys: ind_sales2_id
key: ind_sales2_id
key_len: 5
ref: NULL
rows: 1000