storm基础详解
Storm基础详解
一、storm是什么
Storm是一个分布式的、可靠的、高容错的实时流式数据处理系统。
二、storm的特性
简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性,可以使用各种编程语言,容错性,水平扩展,可靠的消息处理等。
三、storm的应用场景
Storm主要的应用场景就是流式数据处理,例如实时推荐系统,实时监控系统等。
四、storm中的相关概念
在storm中,分布式的计算结构指的是一个topology(拓扑),一个topology由流式数据,spouts(流生产者),以及bolts(具体操作者)组成。Storm的topologies和其他的批处理任务系统很类似,例如Hadoop,这类批处理任务都定义了清晰的开始和结束点,然而storm的topologies是永不停息的在运行的,除非杀死或者反部署这个topologies。
Topology:storm都是以topology为单位运行的,topology就相当于网络中的拓扑图一样。
Tuple:tuple是storm结构中的核心数据,一个tuple可以简单的理解为一系列的的键值对(key-value pairs),是storm结构中最小的数据单元。如果你对CEP(complex event processing)熟悉的话,你可以认为tuples就是事件集。
Streams:streams是由无限的tuples组成。
Spouts:spouts代表一个storm topology的数据入口,spouts扮演者适配器的作用,连接着一个个的数据源,并将数据转换成tuples,同时以数据流的方式发送tuples。数据源的来源有如下几种:1、网络或者是移动应用;2、推特或者是微博等社交网络;3、传感器输出;4、应用日志事件。典型的spouts不会实现任何的特定业务逻辑,所以spouts可以经常被重复交叉的被多个topologies使用
Bolts:bolts可以想象成计算的操作者或者是一个函数,他们可以接收任意的数据流或者被处理过的数据,而且还可以随意的发送一个或多个tuples,bolts可以订阅spouts或者是其他bolts发送过来的数据流,bolts可以创造一个复杂的数据传输网络。bolts的典型作用如下:1、过滤tuples;2、连接或者是聚合;3、计算
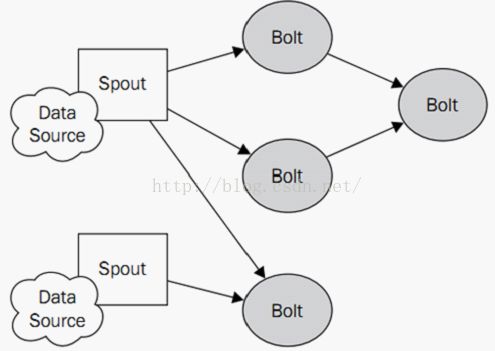
一个简单的topology如下图所示:
五、入门示例
下面我们来看一个简单的入门示例,该示例被誉为storm界的hello world,先来看下topology图:
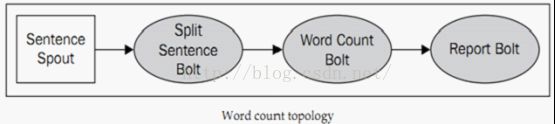
该图中的各个组件的作用如下:
Sentence Spout:是整个topology的数据源,会接收源源不断的英语句子,例如:my name is chhliu!
Split Sentence Bolt:用来将英语句子拆分为一个个单词,例如my,name,is,chhliu。
Word Count Bolt:用来计算每个单词出现的数量和。
Report Bolt:用来展示最后的统计结果。
虽然上面的topology图看上去比较简单,但是如果分布式部署的话,就可以扩展到无穷大,如下图所示:

下面我们用代码实现上面的这个拓扑图功能。
1、新建一个maven项目,并加入storm的依赖如下:
org.apache.storm
storm-core
0.9.1-incubating
2、建立一个spout,用来产生源源不断的数据,代码如下:
public class SentenceSpout extends BaseRichSpout {
/**
*
*/
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private static final String[] sentences = {
"my dog has fleas",
"i like cold beverages",
"the dog ate my homeword",
"don't have a cow man",
"i don't think i like fleas"
};
// 由于涉及到多线程并发,对该值的修改,需要加锁
private int index = 0;
private ReentrantLock lock;
@Override
public void nextTuple() {
lock.lock();
try{
// this.collector.emit(new Values(sentences[index]));
// index++;
// if(index >= sentences.length){
// index = 0;
// }
if(index < sentences.length){
this.collector.emit(new Values(sentences[index]));
index++;
}
}finally{
lock.unlock();
}
}
@SuppressWarnings("rawtypes")
@Override
public void open(Map arg0, TopologyContext arg1, SpoutOutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}Spout需要继承BaseRichSpout抽象类,或者是实现IRichSpout接口,一旦启动,nextTuple() 方法会不停的执行,从而产生源源不断的数据,open()方法是用来初始化的,例如初始化发射器,初始化文件等,declareOutputFields()方法定义了一个字段,该字段的作用就相当于给tuple定义了一个key值,我们在向下一个组件发送数据的时候,就只需要发送该Field对应的value即可,例如this.collector.emit(new Values(sentences[index]));这个方法表示向下一个组件(比如Bolt)发送了一个key-value的数据,key值为declareOutputFields()方法中定义的字段,value值则是sentences[index]。上面的key-value值对应的效果如下:
{"sentence":"my dog has fleas"}
{"sentence":"i like cold beverages"}
{"sentence":"the dog ate my homeword"}
{"sentence":"don't have a cow man"}
{"sentence":"i don't think i like fleas"}下面,我们来实现Split Sentence Bolt,该Bolt负责接收Spout发送过来的数据,然后拆分成一个个的单词,并将这些拆分好的单词发送到Word Count Bolt,代码如下:
public class SplitSentenceBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
@Override
public void execute(Tuple tuple) {
// String sentence = tuple.getString(0);
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split("\\s+");
for(String word:words){
this.collector.emit(new Values(word));
}
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}Bolt需要继承BaseRichBolt抽象类,或者是实现IRichBolt接口,一旦系统启动,该Bolt就会不断的运行execute()方法,来处理由上一个组件发送过来的数据(比如Spout),其中Bolt中的prepare()方法和Spout中的Open方法类似,也是用来做初始化操作的,上面示例中的declareOutputFields()方法和Spout中的方法一样,也是用来定义域的,declarer.declare(new Fields("word",));这句代码表示会发送一个key-value数据给下一个组件,其中key为”word”,tuple.getStringByField("sentence");该方法表示接收上个组件中key为”sentence”的值。
下面我们来看下Word Count Bolt,该Bolt负责将接收到的每个单词进行叠加,统计每个单词出现的次数,并将统计的结果发送到Report Bolt,代码如下:
public class WordCountBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private OutputCollector collector;
// 由于涉及到多线程操作,此处需要用ConcurrentHashMap
private ConcurrentHashMap counts = null;
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count ++;
this.counts.put(word, count);
this.collector.emit(new Values(word, count));
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
this.counts = new ConcurrentHashMap();
System.out.println("================WordCount Bolt===================");
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
} 最后的key-value值对应如下:
{"word":"dog ", "count":"2"}{"word":"like ", "count":"3"}
{"word":"fleas", "count":"1"}{"word":"I", "count":"4"}最后我们来看下Report Bolt,代码如下:
public class ReportBoltImprovement extends BaseRichBolt {
private OutputCollector collector;
private static final long serialVersionUID = 1L;
private ConcurrentHashMap counts = null;
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = tuple.getLongByField("count");
this.counts.put(word, count);
this.collector.ack(tuple);
}
@SuppressWarnings("rawtypes")
@Override
public void prepare(Map arg0, TopologyContext arg1, OutputCollector collector) {
this.collector = collector;
this.counts = new ConcurrentHashMap();
}
@Override
public void declareOutputFields(OutputFieldsDeclarer arg0) {
}
@Override
public void cleanup() {
System.out.println("-----------------FINAL COUNTS--------------------");
List keys = new ArrayList();
keys.addAll(this.counts.keySet());
Collections.sort(keys);
for (String key : keys) {
System.out.println(key + " : " + this.counts.get(key));
}
System.out
.println("---------------------------------------------------------------");
}
} 六、Grouping策略
现在,我们所有的Spout和Bolt都编写完毕了,下面我们要做的就是来“画”topology结构了,那么如何来将Spout和Bolt组合成一个完整的topology结构了,这就要说到storm的Grouping了,storm总共支持以下的Grouping,如下:
| Name |
Function |
| Shuffle grouping |
随机的分发到每个Bolt,并且每个Bolt收到的tuples数基本相同 |
| Fields grouping |
根据指定的fields的值来决定tuples会被分发到哪个Bolt,例如一个数据流以word为field字段来分组的话,那么只要是field字段为word的tuple都会被分发到同一个Bolt中 |
| All grouping |
所有的Bolt都会收到一个tuple的副本,这种分发方式相当于广播模式 |
| Global grouping |
所有的tuples都会被路由到一个单独的task中,并且只会选中task的ID值最小的那个,如果我们使用了此策略的话,那我们用过设置并行度(后面会介绍)来提高并发率是毫无意义的,因为所有的tuples都只会发送到同一个Bolt的去,此策略的使用需要谨慎,有可能成为整个集群的一个瓶颈 |
| None grouping |
目前和Shuffle grouping策略是一样的,是一个预留的策略,未来可能会使用 |
| Direct grouping |
使用该策略的使用,源数据流可以指定哪些组件会接收这个tuple,例如我们可以在Spout中指定由哪个Bolt来接收数据,然后直接发送到对应的Bolt中,这种方式只有在定义了direct流的时候才有用 |
| Local or shuffle grouping |
Local or shuffle grouping和shuffle grouping非常类似,但是会优先随机发送tuples到用一个worker(JVM)进程的Bolt中去,如果不在同一个worker中,那么效果是和shuffle grouping策略是一样的,在网络传输限制的情况下,这种分组方式可以提高整个topology的性能 |
| CustomStreamGrouping |
这种策略是storm提供给用户的自定义分组策略,由用户来决定如何进行分组,通过实现CustomStreamGrouping这个接口中的prepare和chooseTasks方法来实现 |
说完了Grouping,下面就来完成上面代码中的topology结果,代码如下:
public class WordCountTopology {
// 以下定义各个组件的ID
private static final String SENTENCE_SPOUT_ID = "sentence-spout";
private static final String FILE_SPOUT_ID = "file-spout";
private static final String SPLIT_BOLT_ID = "split-bolt";
private static final String COUNT_BOLT_ID = "count-bolt";
private static final String REPORT_BOLT_ID = "report-bolt";
private static final String TOPOLOGY_NAME = "word-count-topology";
public static void main(String[] args) throws InterruptedException {
SentenceSpoutImprovement spout = new SentenceSpoutImprovement();
SplitSentenceBoltImprovement splitBolt = new SplitSentenceBoltImprovement();
WordCountBoltImprovement countBolt = new WordCountBoltImprovement();
ReportBoltImprovement reportBolt = new ReportBoltImprovement();
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(FILE_SPOUT_ID, fileSpout);
builder.setSpout(SENTENCE_SPOUT_ID, spout);
/*
* SentenceSpout --> SplitSentenceBolt
* 通过fieldsGrouping策略来分组
*/
builder.setBolt(SPLIT_BOLT_ID, splitBolt).fieldsGrouping(SENTENCE_SPOUT_ID, new Fields("sentence"))
/*
* SplitSentenceBolt --> WordCountBolt
* 注意,此处需要使用fieldsGrouping来分组,要不然统计的数据会不准,例如一个Bolt中接收到{"word":"dog","count":"1"}
* 然后又来了一个{"word":"dog","count":"1"},但是又没有发送到同一个Bolt中,那么就会重新统计
*/
builder.setBolt(COUNT_BOLT_ID, countBolt).fieldsGrouping(SPLIT_BOLT_ID, new Fields("word"));
// WordCountBolt --> ReportBolt
builder.setBolt(REPORT_BOLT_ID, reportBolt).globalGrouping(COUNT_BOLT_ID);
// 配置类,该类中的所有配置文件,都会在Spout的open方法中被加载
Config config = new Config();
config.put("wordsFile", "src/main/resources/words.txt");
// 配置超时时间
config.put(Config.NIMBUS_SUPERVISOR_TIMEOUT_SECS, 10);
// 新建一个本地集群
LocalCluster cluster = new LocalCluster();
// 将topology提交到集群中
cluster.submitTopology(TOPOLOGY_NAME, config, builder.createTopology());
// 等待10s
Utils.wait4Second(10);
// 手动杀死集群中的topology
cluster.killTopology(TOPOLOGY_NAME);
// 关闭集群
cluster.shutdown();
}
}这样,我们的整个topology就完成了,下面来看下storm的并行度。先来看下上面例子中的默认情况的并行度,如下图所示:
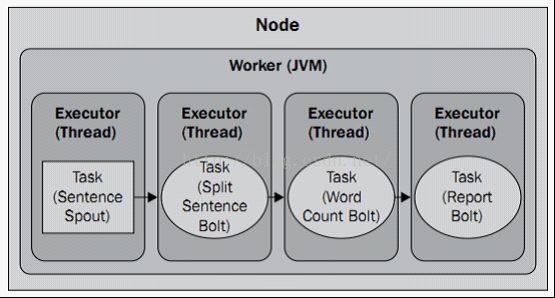
默认情况下,只有一台机器,一个worker,每个组件只有一个Executor和一个Task。上图中的Node表示一台物理机,Worker表示一个JVM进程,Executor我们可以理解成线程池,Task表示Executor中运行的任务数,上面的这些都是可以动态改变的,如下:
// 设置2个Worker
Config config = new Config();
config.setNumWorkers(2);
// 设置2个Executor
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2);
// 设置2个task
builder.setSpout(SENTENCE_SPOUT_ID, spout, 2).setNumTasks(2);
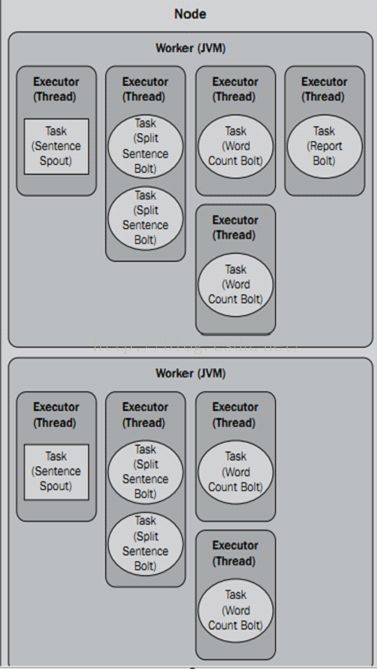
通过上面的设置可以大大的提高topology的并行度,但是在本地模式下,设置多个Worker是不起作用的,因为本地模式下,只有一个JVM。|
上图中,表示一台物理机(Supervisor)上,有两个虚拟机(Worker),Sentence Spout设置了2个Executor,每个Executor中有一个task,Split Sentence Bolt设置了2个Executor,每个Executor中有2个task,Word Count Bolt设置了4个Executor,每个Executor中有1个task。 |
下面,我们来加入一个Spout,这个Spout是另一个数据源,从文本文件中读取英语句子,代码如下:
public class FileSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
@SuppressWarnings("rawtypes")
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
try {
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["+conf.get("wordFile")+"]");
}
this.collector = collector;
}
@Override
public void nextTuple() {
if(completed){
return;
}
String str;
BufferedReader reader = new BufferedReader(fileReader);
try {
while((str = reader.readLine()) != null){
System.out.println("reader thread:"+Thread.currentThread().getName());
// Values是ArrayList的一个实现,其中把list的元素传到了构造方法中
this.collector.emit(new Values(str));
}
} catch (IOException e) {
throw new RuntimeException("Error reading tuple", e);
}finally{
completed = true;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}加入了一个新的Spout数据源,那怎么将这个Spout数据源的数据发送到Split Sentence Bolt了,方法如下:
builder.setBolt(SPLIT_BOLT_ID, splitBolt, 4).fieldsGrouping(SENTENCE_SPOUT_ID, new Fields("sentence")).fieldsGrouping(FILE_SPOUT_ID, new Fields("line"));
这一句代码表示将SENTENCE_SPOUT,和FILE_SPOUT的数据都发送到SPLIT_BOLT我们来看下上面示例中,最后的运行结果:

九、可靠的Spout和Bolt
下面,我们再来说下,storm如何实现可靠的Spout和Bolt,这也是storm如何保证消息被至少处理一次的重要原因,首先,storm的所有组件和机器都是无状态和失败快速返回的,也就是说,整个storm集群在运行的过程中都不会保存中间状态,一旦运行失败了,则返回重新处理。先来说下可靠的Spout。
要实现Spout的可靠性,需要解决以下几个问题:1、如果持续的跟踪由自己发送的tuples;2、当下游的程序处理tuple失败,或者是任意的子tuple失败如何准备重发。在topology中,会生成一棵tuple树,如下图所示:
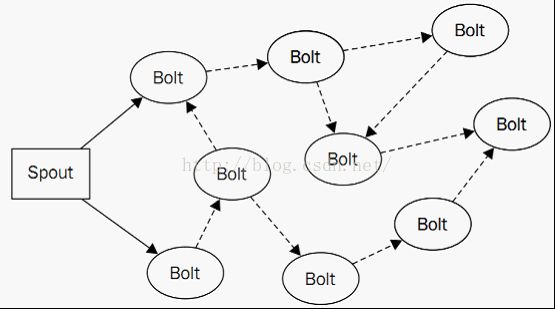
Topology会根据两个必要条件来判断一条消息是否被正确处理,条件1、tuple树不在增长,2、收到tuple树上的每个组件的回复。其实storm使用了一个非常技巧的算法来实现,例如每增加一个组件就做一次异或操作,没收到一个组件的回复就又做一次异或操作,直到异或操作的最终结果为0,则说明消息被正常处理,这样的话,程序不需要保存任何的中间结果,节约了大量的内存空间。实现可靠的Spout也非常简单,分如下两步完成:1、使用emit(values, msgId)方法锚定,注意第二个参数,该id会作为跟踪的一个凭证;2、失败重发,如下:
@Override
public void ack(Object msgId) {
System.out.println("发送成功:"+this.pending.get(msgId));
this.pending.remove(msgId);
}
@Override
public void fail(Object msgId) {
System.out.println("发送失败:"+this.pending.get(msgId)+" 重新发送");
this.collector.emit(this.pending.get(msgId), msgId);
}同理,实现可靠的Bolt也一样,代码如下:
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Long count = this.counts.get(word);
if(count == null){
count = 0L;
}
count ++;
this.counts.put(word, count);
// 注意第一个参数,用来锚定该tuple
this.collector.emit(tuple, new Values(word, count));
// 如果处理成功,则向上反馈
this.collector.ack(tuple);
}当我们真正的分布式部署的时候,结构如下:
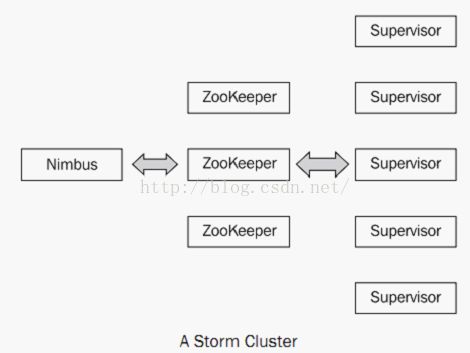
在整个分布式集群中,有且只有一个Nimbus节点,这也是storm存在的一个缺点,但网上已经有很多双Nimbus的解决方案供参考。Nimbus的主要作用就是分配,协调任务,以及故障检测等,如果Supervisor停止心跳,则通过Zookeeper动态的将失败的任务分配到其他的Supervisor机器上,Supervisor用来监控Workers的执行任务,是真正运行topology的单元,当topology被提交到整个集群的时候,Supervisor会通过Thrift协议从Nimbus上下载topology并运行。在整个集群中Zookeeper负责整体的协调工作。