Pointer Network, copyNet与attention机制
经典decoder+ATT图:
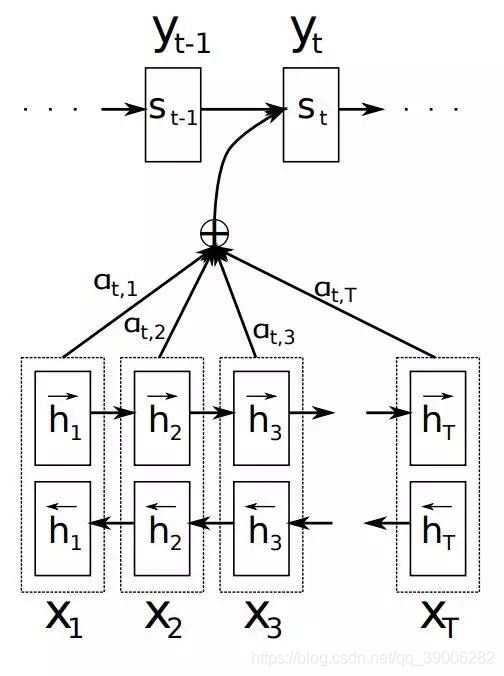
pointer network是encoder-decoder结构, 前面的encoder提取语义, 后面decoder预测(指针指向的)位置.
普通的seq2seq摘要的decoder部分都是常见的人体蜈蚣结构, 即输出作为下一级输入, 普通的attention就是前一项输出与encoder隐层相乘+softmax得到a, 再与encoder隐层权重加和.
pointer不一样, 它在attention的softmax时直接拿到最大的a的编号, 直接把编号的encoder输入作为decoder输入, 再与decoder前一单元的输出加和, 送入当前单元进行预测.
2019/12/20
PrtNet和copyNet的文章
回顾
PtrNet的提出是解决了OOV的问题的, 但论文里没有给出实际的落地使用.
copyNet套用Ptr的结构, 加上copy机制, 做到了文本摘要.
copyNet的论文
copyNet不算复杂, 前提是能看懂PtrNet.
copyNet修改了decoder部分的策略, 除了已有传统词表的概率矩阵输出, 还要有输入句子构成的词表的概率矩阵输出. 其中OOV词就在后面这个词表里.
每一步decoder的输入 h t h_t ht 都会接收attention和前一个的输出 y t − 1 y_{t-1} yt−1 的位置向量, 它们的长度等于输入句子的长度.因为这是文本摘要任务, 所以预测的词必在文本中.
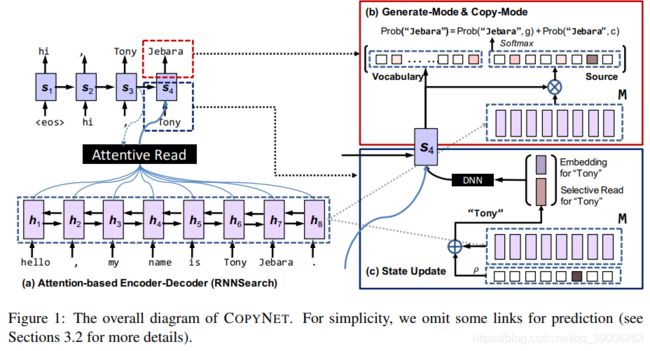
如图中 ( c ) S t a t e U p d a t e (c)State Update (c)StateUpdate框里所示, ρ ρ ρ和 M M M长度一样, 黑色代表上一个输出词"Tony"在输入句子中的位置.
虽然 M M M和 ρ ρ ρ一起指向了加和关系, 但实际上是 M M M和 ρ ρ ρ中时序对应的位置做 f ( ρ t , M t ) f(ρ_t, M_t) f(ρt,Mt), 再将每个t做累加, f f f的公式在论文中有.这样做的原因是有时候一个词对应到输入中会有很多个位置.
处理完后的向量包含了高浓度的"Tony"的上下文语境, 即图中的棕色方块Selective Read for “Tony”.
它会和"Tony"在传统词表中的embedding拼接, 经过DNN作为下一单元的一部分输入.
让人疑惑的是, 论文说这种机制similar to attention, 也就是说原本的attention被移除了, 只用视野狭窄的bi-RNNs做上下文语义提取.
至此, 单元的输入被改成了: 上一次的输出, 上一次输出词的词向量, 以及上一次输出词在原句的上下文信息.
三种信息经decoder单元融合, 一来可以做常规词表的"普通"关键词输出, 即Generate-Mode; 二来可以结合 M M M实现Pointer, 即Copy-Mode. 具体Copy-Mode的乘法公式在论文中, 有很多细节, 例如UNK词的处理.
得到Generate和Copy两部分词表后, 会将相同词的概率相加, 再softmax归一化, 得到最大概率的词.
对于OOV词, 论文假设它是UNK,和传统词表一起预测, 但没看到要怎么初始化它的向量. 一般做法是随机一个词向量做UNK.

copyNet的输入似乎有信息冗余, decoder部分既包含了 y t − 1 y_{t-1} yt−1这个隐层来表示之前预测的序列, 还用上个词的词向量 e t − 1 e_{t-1} et−1与Selective Read做DNN, 虽然没明说, 但attention机制被换掉了, 种种迹象表明, 这个网络的视野变窄了, 而且极倾向于用原文信息做文本摘要, 因为最后概率softmax的时候, 两边词表大小都不一样, 小词表这边的概率肯定普遍都高, 即使相同词概率加和也没有用, 从论文的示例里也能看出来, 所以这个模型相当于把意译摘要这条路掐死了.