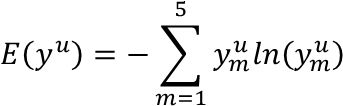- 李宏毅机器学习笔记——反向传播算法
小陈phd
机器学习机器学习算法神经网络
反向传播算法反向传播(Backpropagation)是一种用于训练人工神经网络的算法,它通过计算损失函数相对于网络中每个参数的梯度来更新这些参数,从而最小化损失函数。反向传播是深度学习中最重要的算法之一,通常与梯度下降等优化算法结合使用。反向传播的基本原理反向传播的核心思想是利用链式法则(ChainRule)来高效地计算损失函数相对于每个参数的梯度。以下是反向传播的基本步骤:前向传播(Forwa
- 李宏毅机器学习笔记 2.回归
Simone Zeng
机器学习机器学习
最近在跟着Datawhale组队学习打卡,学习李宏毅的机器学习/深度学习的课程。课程视频:https://www.bilibili.com/video/BV1Ht411g7Ef开源内容:https://github.com/datawhalechina/leeml-notes本篇文章对应视频中的P3。另外,最近我也在学习邱锡鹏教授的《神经网络与深度学习》,会补充书上的一点内容。通过上一次课1.机器
- 2023春季李宏毅机器学习笔记 02 :机器学习基本概念
女王の专属领地
机器学习深度学习#李宏毅2023机器学习机器学习笔记人工智能
资料课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.phpGithub:https://github.com/Fafa-DL/Lhy_Machine_LearningB站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800一、機器學習基
- 2023春季李宏毅机器学习笔记 03 :机器如何生成文句
女王の专属领地
#李宏毅2023机器学习机器学习深度学习笔记机器学习人工智能深度学习
资料课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.phpGithub:https://github.com/Fafa-DL/Lhy_Machine_LearningB站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800一、大语言模型
- Chat GPT4来了,它和3.5区别在哪?李宏毅机器学习笔记
抱抱小杠杠
机器学习人工智能笔记
听说GPT4模型更大、参数更多,功能更强,具体它好在哪里?GPT4真的能看懂图片吗?官方回答:不太能~~下面这张图片是将两个不存在的网址输入进GPT4,问它看到了什么,结果发现GPT真的会胡言乱语,它会根据网址中出现了“man”这个单词,就说他看到了“一个拿着手枪的男人。。。巴拉巴拉”明显就是在胡编乱造!而如果网址中出现了“girl”这个单词,GPT又会说他看到了“一个穿着校服的女孩子。。。巴拉巴
- 2023春季李宏毅机器学习笔记 05 :机器如何生成图像
女王の专属领地
#李宏毅2023机器学习机器学习笔记人工智能机器学习李宏毅AI产品
资料课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.phpGithub:https://github.com/Fafa-DL/Lhy_Machine_LearningB站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800一、图像生成常
- 2023春季李宏毅机器学习笔记01 :正确认识 ChatGPT
女王の专属领地
深度学习机器学习机器学习李宏毅人工智能AI产品
资料课程主页:https://speech.ee.ntu.edu.tw/~hylee/ml/2023-spring.phpGithub:https://github.com/Fafa-DL/Lhy_Machine_LearningB站课程:https://space.bilibili.com/253734135/channel/collectiondetail?sid=2014800一、对Chat
- 【23-24 秋学期】NNDL 作业11 LSTM
HBU_David
lstm机器学习人工智能
习题6-4推导LSTM网络中参数的梯度,并分析其避免梯度消失的效果习题6-3P编程实现下图LSTM运行过程李宏毅机器学习笔记:RNN循环神经网络_李宏毅rnn笔记_ZEERO~的博客-CSDN博客https://blog.csdn.net/weixin_43249038/article/details/132650998L5W1作业1手把手实现循环神经网络-CSDN博客https://blog.c
- 李宏毅老师机器学习课程笔记_ML Lecture 1: ML Lecture 1: Regression - Demo
leogoforit
引言:最近开始学习“机器学习”,早就听说祖国宝岛的李宏毅老师的大名,一直没有时间看他的系列课程。今天听了一课,感觉非常棒,通俗易懂,而又能够抓住重点,中间还能加上一些很有趣的例子加深学生的印象。视频链接(bilibili):李宏毅机器学习(2017)另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML-Notes)所以,接下来我的笔记只记录一些我自己的总结和听课当时的
- 李宏毅机器学习笔记.Flow-based Generative Model(补)
oldmao_2000
李宏毅机器学习笔记机器学习笔记人工智能
文章目录引子生成问题回顾:GeneratorMathBackgroundJacobianMatrixDeterminant行列式ChangeofVariableTheorem简单实例一维实例二维实例网络G的限制基于Flow的网络构架G的训练CouplingLayerCouplingLayer反函数计算CouplingLayerJacobian矩阵计算CouplingLayerStacking1×1
- 李宏毅机器学习笔记-transformer
ZEERO~
深度学习机器学习笔记transformer深度学习
transformer是什么呢?是一个seq2seq的model。具体应用如上图所示,输入和输出的序列长度不固定,由model自己决定。语音翻译指的是,直接输入一段语音信号,例如英文,输出的直接是翻译之后的中文。seq2seq如今已经是一个应用非常广泛的模型,可以应用于NLP的各种任务,如语义分析,语义分类,聊天机器人等。另外还有个值得说明的功能是做multilabelclassification
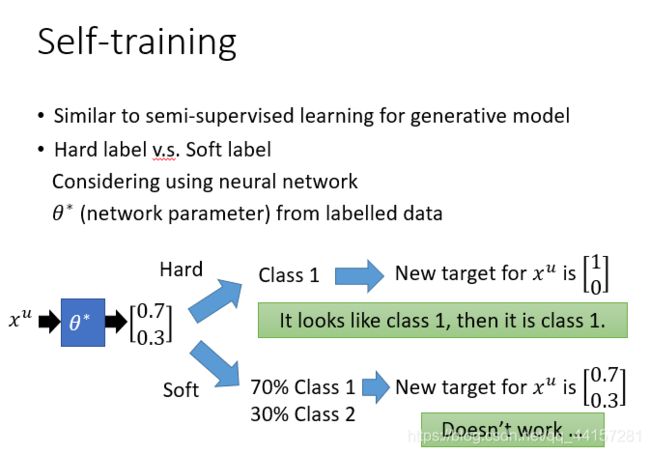
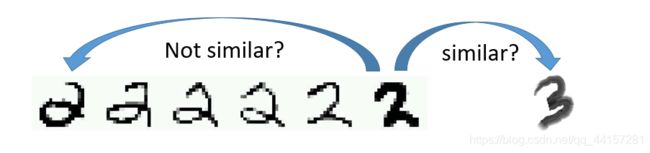
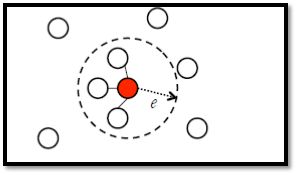
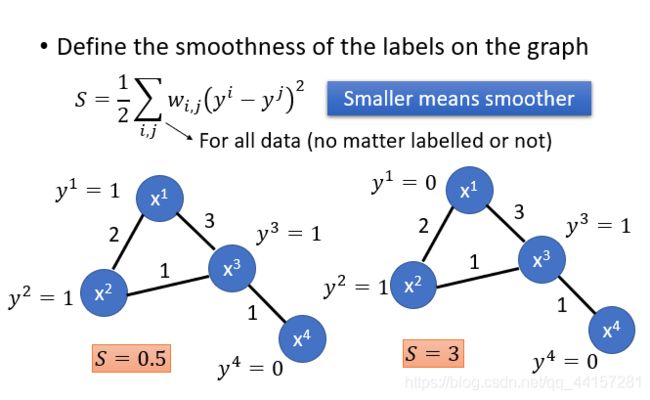
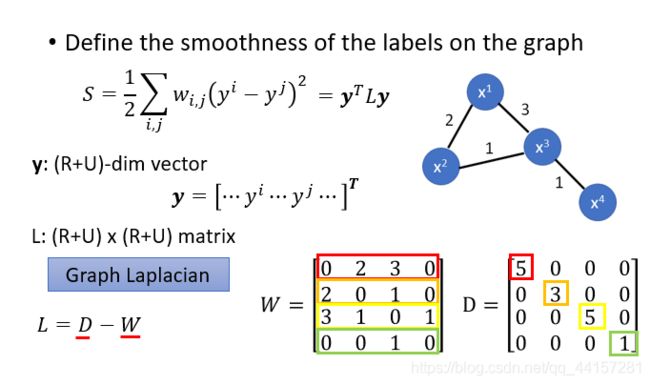
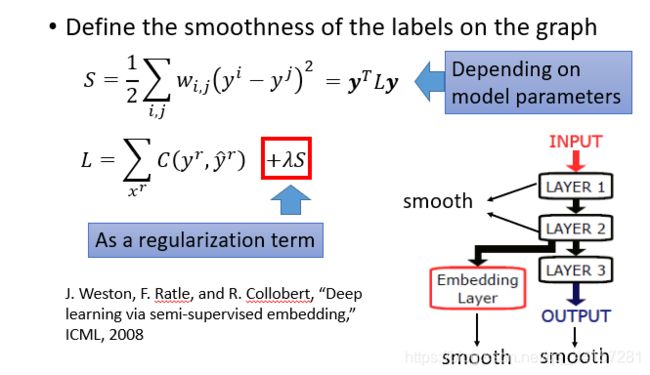
- 李宏毅机器学习笔记-半监督学习
ZEERO~
深度学习机器学习笔记学习
半监督学习,一般应用于少量带标签的数据(数量R)和大量未带标签数据的场景(数量U),一般来说,U>>R。半监督学习一般可以分为2种情况,一种是transductivelearning,这种情况下,将unlabeleddata的feature利用进来。另外一种是inductivelearning,这种情况下,在训练的整个过程中,完全不看任何unlabeleddata的信息。为什么要做semi-sup
- 李宏毅机器学习笔记第7周_局部最小值与鞍点
MoxiMoses
机器学习深度学习
文章目录一、OptimizationFailsbecause……二、TaylerSeriesApproximation三、Example总结一、OptimizationFailsbecause……1.问题:我们在做optimization的时候会发现,随着参数的不断更新,training的loss不会再下降,但是我们对loss并不满意。因此我们会发现,一开始model就train不起来,不管我们怎
- 李宏毅机器学习笔记:RNN循环神经网络
ZEERO~
深度学习机器学习机器学习笔记rnn
RNN一、RNN1、场景引入2、如何将一个单词表示成一个向量3种典型的RNN网络结构二、LSTMLSTM和普通NN、RNN区别三、LSTM的训练一、RNN1、场景引入例如情景补充的情况,根据词汇预测该词汇所属的类别。这个时候的Taipi则属于目的地。但是,在订票系统中,Taipi也可能会属于出发地。到底属于目的地,还是出发地,如果不结合上下文,则很难做出判断。因此,使用传统的深度神经网络解决不了问
- 李宏毅机器学习笔记:结构学习,HMM,CRF
ZEERO~
机器学习机器学习笔记学习
李宏毅机器学习笔记:结构学习,HMM,CRF1、隐马尔可夫模型HMM1.1Sequence2Sequence1.2HMM1.3Viterbi算法1.3HMM模型的缺点2、CRF2.1CRF模型2.2CRF模型训练1、隐马尔可夫模型HMM1.1Sequence2Sequence什么是Seq2Seq问题呢?简单来说,就是输入是一个序列,输出也是一个序列。输入和输出的序列可以相等,也可以不相等。在本文中
- 李宏毅机器学习笔记——16. Conditional Generation by RNN&Attention(RNN条件生成与注意力机制)
HSR CatcousCherishes
机器学习基础课程知识机器学习人工智能神经网络
摘要:本章内容是讲解了Generation,Attention,TipsforGeneration,一是围绕用RNN实现Generation(生成)的方法与基本原理,先应用生成句子去介绍生成的基本原理,接着举例无条件的生成图片,其不同的是:将图片上的每个像素点看成一个word,并需要考虑各像素之间的几何关系,所以我们需要借助3D-LSTM完善了Generation图片功能。但是在实际应用中,我们的
- 李宏毅机器学习笔记——生成模型
荆棘鸟》
深度学习人工智能
介绍了三种方法,pixelRNN,VAE,GAN。笔记以VAE为主。pixelRNN比较容易理解,由已知推未知。这种方法还能应用到语音生成等领域在这里有个tips值得说一下,图的每个像素一般RGB三色,问题出在当RGB三个值相差不大时最终的结果像素点的颜色趋向灰色,于是乎,为了使生成的图像更加鲜亮,就需要拉高三个值的差距。简而言之,原本用三个数表示颜色,现在只用一个。VAE是一个相对复杂的东西,事
- 李宏毅机器学习笔记——概率模型
荆棘鸟》
机器学习人工智能神经网络
很有意思的一门课,但关于如何利用P(x)生成x还存在疑惑。在神经网络中y=w*x+b,为什么是这个形式?这门课将在最后归结到这一点上。举一个实际的例子,训练集中A类71个B类69个我们假定A类的71个点遵循gaussiondistribution,上图涉及的函数:输入一个点(代表一个实例的特征vector),输出sample中该点的概率,在下文中即为P(x|A)与P(x|B)该函数有两个参数,μ与
- 李宏毅机器学习笔记
learn_for_more
机器学习人工智能深度学习
DataWhale–李宏毅老师机器学习P5-P8《误差来源》和《梯度下降法》学习笔记学习笔记本文是李宏毅老师B站–《机器学习》课程的学习笔记,在此非常感谢DataWhale提供的平台,希望大家加入到这个学习的大家庭中,共同成长。本文主要是关于误差来源及梯度下降法的介绍,是在老师的讲解视频和学习文档的基础上总结而来。一、误差来源在机器学习中,模型估计的误差可以分为两种,偏差(Bias)和方差(Var
- 【ML入门】李宏毅机器学习笔记02-回归问题(Regression)
BG大龍
【ML入门】李宏毅机器学习笔记02-回归问题(Regression)-知乎https://zhuanlan.zhihu.com/p/74684108
- 李宏毅机器学习笔记第8周_批次与动量
MoxiMoses
机器学习深度学习
文章目录一、Review:OptimizationwithBatch二、SmallBatchv.s.LargeBatch三、Momentum1.SmallGradient2.VanillaGradient3.GradientDescent+Momentum一、Review:OptimizationwithBatch在计算微分的时候,并不是把所有的data对计算出来的L做微分,而是把data分成一个
- 【ML入门】李宏毅机器学习笔记01-Learning Map
BG大龍
【ML入门】李宏毅机器学习笔记01-LearningMap-知乎https://zhuanlan.zhihu.com/p/74377397
- 李宏毅机器学习—机器学习介绍
修_远
李宏毅机器学习
李宏毅机器学习笔记github链接:https://github.com/datawhalechina/leeml-notes李宏毅机器学习笔记在线阅读链接:https://datawhalechina.github.io/leeml-notes机器学习介绍这门课,我们预期可以学到什么呢?我想多数同学的心理预期就是你可以学到一个很潮的人工智慧。我们知道,从今年开始,人工智慧这个词突然变得非常非常非
- 【李宏毅机器学习笔记】9、卷积神经网络(Convolutional Neural Network,CNN)
qqqeeevvv
机器学习深度学习机器学习深度学习
【李宏毅机器学习笔记】1、回归问题(Regression)【李宏毅机器学习笔记】2、error产生自哪里?【李宏毅机器学习笔记】3、gradientdescent【李宏毅机器学习笔记】4、Classification【李宏毅机器学习笔记】5、LogisticRegression【李宏毅机器学习笔记】6、简短介绍DeepLearning【李宏毅机器学习笔记】7、反向传播(Backpropagatio
- 李宏毅机器学习笔记第8周_自动调整学习速率
MoxiMoses
机器学习深度学习
文章目录一、Trainingstuck≠SmallGradient二、Waitaminute三、Trainingcanbedifficultevenwithoutcriticalpoints四、Differentparametersneedsdifferentlearningrate五、Rootmeansquare六、RMSProp七、Adam:RMSProp+Momentum八、Learning
- 【李宏毅机器学习笔记1】第一节 机器学习基本概念简介(上)
freezing001
深度学习深度学习机器学习
第一节机器学习基本概念简介(上)1.机器学习第一步:function机器学习MachineLearning≈LookingforFunctionML的三大任务:Regression(回归)+classification(分类)+strcturedlearning(createsomethingwithstructure)即让机器产生有结构的东西机器学习的model:带有未知parameters的f
- 李宏毅机器学习笔记-Lecture1
不废江河954
笔记深度学习学习机器学习学习人工智能
李宏毅机器学习笔记-Lecture1_续机器学习基本概念(下)PiecewiseLinearCurvesBeyondPiecewiseLinearCurvesSigmoidFunction各参数对Sigmoid的影响用Sigmoid拟合PiecewiseLinearCurvesNewModelwithMoreFeatures最终模型对各个参数的认识MLFramework构造模型构造损失函数找到最优
- 2021李宏毅机器学习笔记--7.1 backpropagation
guoxinxin0605
机器学习神经网络人工智能深度学习
2021李宏毅机器学习笔记--7.1backpropagation1摘要2步骤2.1chainrule链式法则2.2lossfunction2.2.1forwardpass2.2.2backwardpasscase1未知的两项在输出层case2未知的两项并不在输出层3小结及展望1摘要上文讲到可以用Backpropagation的方法对网络中的所有参数(w和b)进行更新,最终使totalloss达到
- 2021李宏毅机器学习笔记--16 Recursive Network
guoxinxin0605
网络神经网络
2021李宏毅机器学习笔记--16RecursiveNetwork递归网络摘要一、Application:SentimentAnalysis(应用:情绪分析)二、RecursiveNetwork三、RecursiveNetworkTensorNetwork四、Matrix-VectorRecursiveNetwork五、TreeLSTM六、MoreApplication(更多应用:句子关联)总结摘
- 2021李宏毅机器学习笔记--7 deep learning深度学习 与 fully connect feedforward network全连接前馈网络
guoxinxin0605
神经网络机器学习深度学习人工智能网络
2021李宏毅机器学习笔记--7deeplearning深度学习与fullyconnectfeedforwardnetwork全连接前馈网络摘要步骤step1NeuralnetworkFullyConnectFeedforwardNetwork全连接前馈网络step2goodnessofafunctionstep3Backpropagation小结与展望摘要近些年来。在各个领域,用到深度学习的地方
- 二分查找排序算法
周凡杨
java二分查找排序算法折半
一:概念 二分查找又称
折半查找(
折半搜索/
二分搜索),优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。因此,折半查找方法适用于不经常变动而 查找频繁的有序列表。首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表 分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步
- java中的BigDecimal
bijian1013
javaBigDecimal
在项目开发过程中出现精度丢失问题,查资料用BigDecimal解决,并发现如下这篇BigDecimal的解决问题的思路和方法很值得学习,特转载。
原文地址:http://blog.csdn.net/ugg/article/de
- Shell echo命令详解
daizj
echoshell
Shell echo命令
Shell 的 echo 指令与 PHP 的 echo 指令类似,都是用于字符串的输出。命令格式:
echo string
您可以使用echo实现更复杂的输出格式控制。 1.显示普通字符串:
echo "It is a test"
这里的双引号完全可以省略,以下命令与上面实例效果一致:
echo Itis a test 2.显示转义
- Oracle DBA 简单操作
周凡杨
oracle dba sql
--执行次数多的SQL
select sql_text,executions from (
select sql_text,executions from v$sqlarea order by executions desc
) where rownum<81;
&nb
- 画图重绘
朱辉辉33
游戏
我第一次接触重绘是编写五子棋小游戏的时候,因为游戏里的棋盘是用线绘制的,而这些东西并不在系统自带的重绘里,所以在移动窗体时,棋盘并不会重绘出来。所以我们要重写系统的重绘方法。
在重写系统重绘方法时,我们要注意一定要调用父类的重绘方法,即加上super.paint(g),因为如果不调用父类的重绘方式,重写后会把父类的重绘覆盖掉,而父类的重绘方法是绘制画布,这样就导致我们
- 线程之初体验
西蜀石兰
线程
一直觉得多线程是学Java的一个分水岭,懂多线程才算入门。
之前看《编程思想》的多线程章节,看的云里雾里,知道线程类有哪几个方法,却依旧不知道线程到底是什么?书上都写线程是进程的模块,共享线程的资源,可是这跟多线程编程有毛线的关系,呜呜。。。
线程其实也是用户自定义的任务,不要过多的强调线程的属性,而忽略了线程最基本的属性。
你可以在线程类的run()方法中定义自己的任务,就跟正常的Ja
- linux集群互相免登陆配置
林鹤霄
linux
配置ssh免登陆
1、生成秘钥和公钥 ssh-keygen -t rsa
2、提示让你输入,什么都不输,三次回车之后会在~下面的.ssh文件夹中多出两个文件id_rsa 和 id_rsa.pub
其中id_rsa为秘钥,id_rsa.pub为公钥,使用公钥加密的数据只有私钥才能对这些数据解密 c
- mysql : Lock wait timeout exceeded; try restarting transaction
aigo
mysql
原文:http://www.cnblogs.com/freeliver54/archive/2010/09/30/1839042.html
原因是你使用的InnoDB 表类型的时候,
默认参数:innodb_lock_wait_timeout设置锁等待的时间是50s,
因为有的锁等待超过了这个时间,所以抱错.
你可以把这个时间加长,或者优化存储
- Socket编程 基本的聊天实现。
alleni123
socket
public class Server
{
//用来存储所有连接上来的客户
private List<ServerThread> clients;
public static void main(String[] args)
{
Server s = new Server();
s.startServer(9988);
}
publi
- 多线程监听器事件模式(一个简单的例子)
百合不是茶
线程监听模式
多线程的事件监听器模式
监听器时间模式经常与多线程使用,在多线程中如何知道我的线程正在执行那什么内容,可以通过时间监听器模式得到
创建多线程的事件监听器模式 思路:
1, 创建线程并启动,在创建线程的位置设置一个标记
2,创建队
- spring InitializingBean接口
bijian1013
javaspring
spring的事务的TransactionTemplate,其源码如下:
public class TransactionTemplate extends DefaultTransactionDefinition implements TransactionOperations, InitializingBean{
...
}
TransactionTemplate继承了DefaultT
- Oracle中询表的权限被授予给了哪些用户
bijian1013
oracle数据库权限
Oracle查询表将权限赋给了哪些用户的SQL,以备查用。
select t.table_name as "表名",
t.grantee as "被授权的属组",
t.owner as "对象所在的属组"
- 【Struts2五】Struts2 参数传值
bit1129
struts2
Struts2中参数传值的3种情况
1.请求参数绑定到Action的实例字段上
2.Action将值传递到转发的视图上
3.Action将值传递到重定向的视图上
一、请求参数绑定到Action的实例字段上以及Action将值传递到转发的视图上
Struts可以自动将请求URL中的请求参数或者表单提交的参数绑定到Action定义的实例字段上,绑定的规则使用ognl表达式语言
- 【Kafka十四】关于auto.offset.reset[Q/A]
bit1129
kafka
I got serveral questions about auto.offset.reset. This configuration parameter governs how consumer read the message from Kafka when there is no initial offset in ZooKeeper or
- nginx gzip压缩配置
ronin47
nginx gzip 压缩范例
nginx gzip压缩配置 更多
0
nginx
gzip
配置
随着nginx的发展,越来越多的网站使用nginx,因此nginx的优化变得越来越重要,今天我们来看看nginx的gzip压缩到底是怎么压缩的呢?
gzip(GNU-ZIP)是一种压缩技术。经过gzip压缩后页面大小可以变为原来的30%甚至更小,这样,用
- java-13.输入一个单向链表,输出该链表中倒数第 k 个节点
bylijinnan
java
two cursors.
Make the first cursor go K steps first.
/*
* 第 13 题:题目:输入一个单向链表,输出该链表中倒数第 k 个节点
*/
public void displayKthItemsBackWard(ListNode head,int k){
ListNode p1=head,p2=head;
- Spring源码学习-JdbcTemplate queryForObject
bylijinnan
javaspring
JdbcTemplate中有两个可能会混淆的queryForObject方法:
1.
Object queryForObject(String sql, Object[] args, Class requiredType)
2.
Object queryForObject(String sql, Object[] args, RowMapper rowMapper)
第1个方法是只查
- [冰川时代]在冰川时代,我们需要什么样的技术?
comsci
技术
看美国那边的气候情况....我有个感觉...是不是要进入小冰期了?
那么在小冰期里面...我们的户外活动肯定会出现很多问题...在室内呆着的情况会非常多...怎么在室内呆着而不发闷...怎么用最低的电力保证室内的温度.....这都需要技术手段...
&nb
- js 获取浏览器型号
cuityang
js浏览器
根据浏览器获取iphone和apk的下载地址
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" content="text/html"/>
<meta name=
- C# socks5详解 转
dalan_123
socketC#
http://www.cnblogs.com/zhujiechang/archive/2008/10/21/1316308.html 这里主要讲的是用.NET实现基于Socket5下面的代理协议进行客户端的通讯,Socket4的实现是类似的,注意的事,这里不是讲用C#实现一个代理服务器,因为实现一个代理服务器需要实现很多协议,头大,而且现在市面上有很多现成的代理服务器用,性能又好,
- 运维 Centos问题汇总
dcj3sjt126com
云主机
一、sh 脚本不执行的原因
sh脚本不执行的原因 只有2个
1.权限不够
2.sh脚本里路径没写完整。
二、解决You have new mail in /var/spool/mail/root
修改/usr/share/logwatch/default.conf/logwatch.conf配置文件
MailTo =
MailFrom
三、查询连接数
- Yii防注入攻击笔记
dcj3sjt126com
sqlWEB安全yii
网站表单有注入漏洞须对所有用户输入的内容进行个过滤和检查,可以使用正则表达式或者直接输入字符判断,大部分是只允许输入字母和数字的,其它字符度不允许;对于内容复杂表单的内容,应该对html和script的符号进行转义替换:尤其是<,>,',"",&这几个符号 这里有个转义对照表:
http://blog.csdn.net/xinzhu1990/articl
- MongoDB简介[一]
eksliang
mongodbMongoDB简介
MongoDB简介
转载请出自出处:http://eksliang.iteye.com/blog/2173288 1.1易于使用
MongoDB是一个面向文档的数据库,而不是关系型数据库。与关系型数据库相比,面向文档的数据库不再有行的概念,取而代之的是更为灵活的“文档”模型。
另外,不
- zookeeper windows 入门安装和测试
greemranqq
zookeeper安装分布式
一、序言
以下是我对zookeeper 的一些理解: zookeeper 作为一个服务注册信息存储的管理工具,好吧,这样说得很抽象,我们举个“栗子”。
栗子1号:
假设我是一家KTV的老板,我同时拥有5家KTV,我肯定得时刻监视
- Spring之使用事务缘由(2-注解实现)
ihuning
spring
Spring事务注解实现
1. 依赖包:
1.1 spring包:
spring-beans-4.0.0.RELEASE.jar
spring-context-4.0.0.
- iOS App Launch Option
啸笑天
option
iOS 程序启动时总会调用application:didFinishLaunchingWithOptions:,其中第二个参数launchOptions为NSDictionary类型的对象,里面存储有此程序启动的原因。
launchOptions中的可能键值见UIApplication Class Reference的Launch Options Keys节 。
1、若用户直接
- jdk与jre的区别(_)
macroli
javajvmjdk
简单的说JDK是面向开发人员使用的SDK,它提供了Java的开发环境和运行环境。SDK是Software Development Kit 一般指软件开发包,可以包括函数库、编译程序等。
JDK就是Java Development Kit JRE是Java Runtime Enviroment是指Java的运行环境,是面向Java程序的使用者,而不是开发者。 如果安装了JDK,会发同你
- Updates were rejected because the tip of your current branch is behind
qiaolevip
学习永无止境每天进步一点点众观千象git
$ git push joe prod-2295-1
To
[email protected]:joe.le/dr-frontend.git
! [rejected] prod-2295-1 -> prod-2295-1 (non-fast-forward)
error: failed to push some refs to '
[email protected]
- [一起学Hive]之十四-Hive的元数据表结构详解
superlxw1234
hivehive元数据结构
关键字:Hive元数据、Hive元数据表结构
之前在 “[一起学Hive]之一–Hive概述,Hive是什么”中介绍过,Hive自己维护了一套元数据,用户通过HQL查询时候,Hive首先需要结合元数据,将HQL翻译成MapReduce去执行。
本文介绍一下Hive元数据中重要的一些表结构及用途,以Hive0.13为例。
文章最后面,会以一个示例来全面了解一下,
- Spring 3.2.14,4.1.7,4.2.RC2发布
wiselyman
Spring 3
Spring 3.2.14、4.1.7及4.2.RC2于6月30日发布。
其中Spring 3.2.1是一个维护版本(维护周期到2016-12-31截止),后续会继续根据需求和bug发布维护版本。此时,Spring官方强烈建议升级Spring框架至4.1.7 或者将要发布的4.2 。
其中Spring 4.1.7主要包含这些更新内容。