Linux文件系统(五)---三大缓冲区之buffer块缓冲区
在文件系统中,有三大缓冲为了提升效率:inode缓冲区、dentry缓冲区、块缓冲。
(内核:2.4.37)
二、块buffer缓冲区
0、整体来说,Linux 文件缓冲区分为page cache和buffer cache,每一个 page cache 包含若干 buffer cache。
》 内存管理系统和 VFS 只与 page cache 交互,内存管理系统负责维护每项 page cache 的分配和回收,同时在使用“内存映射”方式访问时负责建立映射。
》 VFS 负责 page cache 与用户空间的数据交换。
》 而具体文件系统则一般只与 buffer cache 交互,它们负责在存储设备和 buffer cache 之间交换数据,具体的文件系统直接操作的就是disk部分,而具体的怎么被包装被用户使用是VFS的责任(VFS将buffer cache包装成page给用户)。
》 每一个page有N个buffer cache,struct buffer_head结构体中一个字段b_this_page就是将一个page中的buffer cache连接起来的结构
看一下这个结构:/include/linux/mm.h,对于struct buffer_head下面再看。
看到下面167行代码就懂了~
typedef struct page {
156 struct list_head list; /* ->mapping has some page lists. */
157 struct address_space *mapping; /* The inode (or ...) we belong to. */
158 unsigned long index; /* Our offset within mapping. */
159 struct page *next_hash; /* Next page sharing our hash bucket in
160 the pagecache hash table. */
161 atomic_t count; /* Usage count, see below. */
162 unsigned long flags; /* atomic flags, some possibly
163 updated asynchronously */
164 struct list_head lru; /* Pageout list, eg. active_list;
165 protected by pagemap_lru_lock !! */
166 struct page **pprev_hash; /* Complement to *next_hash. */
167 struct buffer_head * buffers; /* Buffer maps us to a disk block. */
168
169 /*
170 * On machines where all RAM is mapped into kernel address space,
171 * we can simply calculate the virtual address. On machines with
172 * highmem some memory is mapped into kernel virtual memory
173 * dynamically, so we need a place to store that address.
174 * Note that this field could be 16 bits on x86 ... ;)
175 *
176 * Architectures with slow multiplication can define
177 * WANT_PAGE_VIRTUAL in asm/page.h
178 */
179 #if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
180 void *virtual; /* Kernel virtual address (NULL if
181 not kmapped, ie. highmem) */
182 #endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
183 } mem_map_t;
关系图如下:
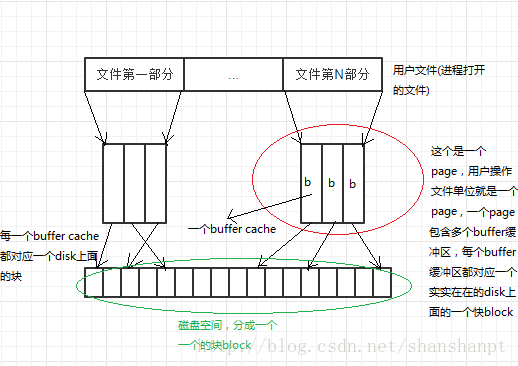
1、对于具体的Linux文件系统,会以block(磁盘块)的形式组织文件,为了减少对物理块设备的访问,在文件以块的形式调入内存后,使用块高速缓存进行管理。每个缓冲区由两部分组成,第一部分称为缓冲区首部,用数据结构buffer_head表示,第二部分是真正的存储的数据。由于缓冲区首部不与数据区域相连,数据区域独立存储。因而在缓冲区首部中,有一个指向数据的指针和一个缓冲区长度的字段。
Ps:内核同样有几种不同的链表来管理buffer cache,在fs/buffer.c中定义:
static struct buffer_head **hash_table;
static struct buffer_head *lru_list[NR_LIST];
static struct buffer_head * unused_list;
下面我们具体看看这个结构体struct buffer_head,这个版本中这个结构体在fs.h中,后面的一些版本,在buffer_head.h中。
246 struct buffer_head {
247 /* First cache line: */
248 struct buffer_head *b_next; /* Hash queue list */
249 unsigned long b_blocknr; /* block number */
250 unsigned short b_size; /* block size */
251 unsigned short b_list; /* List that this buffer appears */
252 kdev_t b_dev; /* device (B_FREE = free) */
253
254 atomic_t b_count; /* users using this block */
255 kdev_t b_rdev; /* Real device */
256 unsigned long b_state; /* buffer state bitmap (see above) */
257 unsigned long b_flushtime; /* Time when (dirty) buffer should be written */
258
259 struct buffer_head *b_next_free;/* lru/free list linkage */
260 struct buffer_head *b_prev_free;/* doubly linked list of buffers */
261 struct buffer_head *b_this_page;/* circular list of buffers in one page */
262 struct buffer_head *b_reqnext; /* request queue */
263
264 struct buffer_head **b_pprev; /* doubly linked list of hash-queue */
265 char * b_data; /* pointer to data block */
266 struct page *b_page; /* the page this bh is mapped to */
267 void (*b_end_io)(struct buffer_head *bh, int uptodate); /* I/O completion */
268 void *b_private; /* reserved for b_end_io */
269
270 unsigned long b_rsector; /* Real buffer location on disk */
271 wait_queue_head_t b_wait;
272
273 struct list_head b_inode_buffers; /* doubly linked list of inode dirty buffers */
274 };b_next:用于链接到块缓冲区的hash表
b_blocknr:本block的块号
b_size:block的大小
b_list:表示当前的这个buffer在那个链表中
b_dev:虚拟设备标识
b_count:引用计数(几个人在使用这个buffer)
b_rdev:真实设备标识
b_state:状态位图,如下:
212 /* bh state bits */
213 enum bh_state_bits {
214 BH_Uptodate, /* 如果缓冲区包含有效数据则置1 */
215 BH_Dirty, /* 如果buffer脏(存在数据被修改情况),那么置1 */
216 BH_Lock, /* 如果缓冲区被锁定,那么就置1 */
217 BH_Req, /* 如果缓冲区无效就置0 */
218 BH_Mapped, /* 如果缓冲区有一个磁盘映射就置1 */
219 BH_New, /* 如果缓冲区是新的,而且没有被写出去,那么置1 */
220 BH_Async, /* 如果缓冲区是进行end_buffer_io_async I/O 同步则置1 */
221 BH_Wait_IO, /* 如果要将这个buffer写回,那么置1 */
222 BH_Launder, /* 如果需要重置这个buffer,那么置1 */
223 BH_Attached, /* 1 if b_inode_buffers is linked into a list */
224 BH_JBD, /* 如果和 journal_head 关联置1 */
225 BH_Sync, /* 如果buffer是同步读取置1 */
226 BH_Delay, /* 如果buffer空间是延迟分配置1 */
227
228 BH_PrivateStart,/* not a state bit, but the first bit available
229 * for private allocation by other entities
230 */
231 };
232b_next_free:指向lru链表中next元素
b_prev_free:指向链表上一个元素
b_this_page:连接到同一个page中的那个链表
b_reqnext:请求队列
b_pprev:hash队列双向链表
data:指向数据块的指针
b_page:这个buffer映射的页面
b_end_io:IO结束时候执行函数
b_private:保留
b_rsector:缓冲区在磁盘上的实际位置
b_inode_buffers:inode脏缓冲区循环链表
3、关于VFS怎么去管理几个buffer cache的链表,如下:
》 hash表:用于管理包含有效数据的buffer,在定位buffer的时候很快捷。哈希索引值由数据块号以及其所在的设备标识号计算(散列)得到。
关于这段hash代码如下:
539 /* After several hours of tedious analysis, the following hash
540 * function won. Do not mess with it... -DaveM
541 */
542 #define _hashfn(dev,block) \
543 ((((dev)<<(bh_hash_shift - 6)) ^ ((dev)<<(bh_hash_shift - 9))) ^ \
544 (((block)<<(bh_hash_shift - 6)) ^ ((block) >> 13) ^ \
545 ((block) << (bh_hash_shift - 12))))当我们在一个具有的文件系统中,当我们需要读取一块数据的时候,需要调用bread函数(面包?ヾ(。`Д´。),应该是buffer read的缩写吧。。。)。
如下:
1181 /**
1182 * bread() - reads a specified block and returns the bh
1183 * @block: number of block 块号
1184 * @size: size (in bytes) to read 需要读取的size
1185 *
1186 * Reads a specified block, and returns buffer head that
1187 * contains it. It returns NULL if the block was unreadable. 返回一个包含这个block的buffer
1188 */
1189 struct buffer_head * bread(kdev_t dev, int block, int size)
1190 {
1191 struct buffer_head * bh;
1192
1193 bh = getblk(dev, block, size); /* 找到这个buffer */
1194 if (buffer_uptodate(bh)) /* 判断是否存在有效数据,如果存在那么直接返回即可 */
1195 return bh;
1196 set_bit(BH_Sync, &bh->b_state); /* 如果不存在有效数据,将这个buffer设置成同步状态 */
1197 ll_rw_block(READ, 1, &bh); /* 如果没有,那么需要从磁盘中读取这个block到buffer中,这个是一个底层的读取操作 */
1198 wait_on_buffer(bh); /* 等待buffer的锁打开 */
1199 if (buffer_uptodate(bh)) /* 理论上这个时候应该是存在有效数据的了,直接返回就可以 */
1200 return bh;
1201 brelse(bh);
1202 return NULL;
1203 }第一:通过dev号+block号找到相应的buffer,使用函数getblk,如下:
1013 struct buffer_head * getblk(kdev_t dev, int block, int size)
1014 {
1015 for (;;) {
1016 struct buffer_head * bh;
1017
1018 bh = get_hash_table(dev, block, size); /* 关键函数,得到hash表中的buffer */
1019 if (bh) {
1020 touch_buffer(bh);
1021 return bh; /* 返回这个buffer */
1022 }
1023 /* 如果没有找到对应的buffer,那么试着去增加一个buffer,就是使用下面的grow_buffers函数 */
1024 if (!grow_buffers(dev, block, size))
1025 free_more_memory();
1026 }
1027 }简单看一下这个查找buffer函数:get_hash_table
628 struct buffer_head * get_hash_table(kdev_t dev, int block, int size)
629 {
630 struct buffer_head *bh, **p = &hash(dev, block); /* 首先通过hash值得到对应的位置,这个函数h很easy */
631 /* 其实就是 #define hash(dev,block) hash_table[(_hashfn(HASHDEV(dev),block) & bh_hash_mask)]。hashfn函数上面已经说过了,就是通过hash值得到buffer*/
632 read_lock(&hash_table_lock);
633
634 for (;;) { /* 下面就是判断这个得到的buffer数组中有没有我们需要的buffer */
635 bh = *p;
636 if (!bh)
637 break;
638 p = &bh->b_next;
639 if (bh->b_blocknr != block)
640 continue;
641 if (bh->b_size != size)
642 continue;
643 if (bh->b_dev != dev)
644 continue;
645 get_bh(bh); /* 如果有那么直接执行这个函数,这个函数很easy,其实就是增加一个使用计数器而已: atomic_inc(&(bh)->b_count);*/
646 break;
647 }
648
649 read_unlock(&hash_table_lock);
650 return bh;
651 }如果没找到对应的buffer,那么使用grow_buffers函数增加一个新的buffer,看函数:
2596 /*
2597 * Try to increase the number of buffers available: the size argument
2598 * is used to determine what kind of buffers we want.
2599 */
2600 static int grow_buffers(kdev_t dev, unsigned long block, int size)
2601 {
2602 struct page * page;
2603 struct block_device *bdev;
2604 unsigned long index;
2605 int sizebits;
2606
2607 /* Size must be multiple of hard sectorsize */
2608 if (size & (get_hardsect_size(dev)-1))
2609 BUG();
2610 /* Size must be within 512 bytes and PAGE_SIZE */
2611 if (size < 512 || size > PAGE_SIZE)
2612 BUG();
2613
2614 sizebits = -1;
2615 do {
2616 sizebits++;
2617 } while ((size << sizebits) < PAGE_SIZE);
2618
2619 index = block >> sizebits;
2620 block = index << sizebits;
2621
2622 bdev = bdget(kdev_t_to_nr(dev));
2623 if (!bdev) {
2624 printk("No block device for %s\n", kdevname(dev));
2625 BUG();
2626 }
2627
2628 /* Create a page with the proper size buffers.. */
2629 page = grow_dev_page(bdev, index, size);
2630
2631 /* This is "wrong" - talk to Al Viro */
2632 atomic_dec(&bdev->bd_count);
2633 if (!page)
2634 return 0;
2635
2636 /* Hash in the buffers on the hash list */
2637 hash_page_buffers(page, dev, block, size);
2638 UnlockPage(page);
2639 page_cache_release(page);
2640
2641 /* We hashed up this page, so increment buffermem */
2642 atomic_inc(&buffermem_pages);
2643 return 1;
2644 }
2645 第二:如果没有找到需要的buffer,那么执行底层读取函数ll_rw_block将数据从磁盘去读进来,这个函数在/source/drivers/block/ll_rw_blk.c中,具体的代码不看了。
OK,至此,寻找一个我们需要的buffer就结束了。
》 LRU链表
对于每一种不同缓冲区都会使用一个LRU来管理未使用的有效缓冲区
Ps:缓冲区类型如下:
1152 #define BUF_CLEAN 0
1153 #define BUF_LOCKED 1 /* Buffers scheduled for write */
1154 #define BUF_DIRTY 2 /* Dirty buffers, not yet scheduled for write */这个三种链表怎么得到的呢,看代码也知道是吻合的,看LRU的声明:static struct buffer_head *lru_list[NR_LIST];
再看:#define NR_LIST 3,OK
当我们需要寻找一块buffer的时候,如果发现buffer在缓冲区中,且在LRU链表中,那么从LRU表中删除。
结合上面的一个hash链表,基本过程就是:
首先呢在hash表中寻找,如果找到,那就OK,如果没有找到,那么需要分配新的buffer,如果分到,那么加载数据进来,继续...如果没有足够的空间分配,那么, 需要将LRU中一个取出(LRU链首元素),先看是否置了“脏”位,如已置,则将它的内容写回磁盘。然后清空内容,将它分配给新的数据块。
在缓冲区使用完了后,将它的b_count域减1,如果b_count变为0,则将它放在某个LRU链尾,表示该缓冲区已可以重新利用。
unused_list 用于辅助就不多说了~~~