爬虫入门之scrapy部署
安装相关库
scrapyd
是运行scrapy爬虫的服务程序,它支持以http命令方式发布、删除、启动、停止爬虫程序。而且scrapyd可以同时管理多个爬虫,每个爬虫还可以有多个版本
pip3 install scrapyd
scrapyd-client
发布爬虫需要使用另一个专用工具,就是将代码打包为EGG文件,其次需要将EGG文件上传到远程主机上这些操作需要scrapyd-client来帮助我们完成
pip3 install scrapyd-client
安装完成后可以使用如下命令来检查是否安装成功
scrapyd-deploy -h
修改scrapy项目目录下的scrapy.cfg配置文件
首先需要修改scrapyd.egg (项目的配置文件)
[deploy]
url=http://localhost:6800
project=项目名称
本地部署
本地部署
项目部署相关命令: 注意这里是项目的名称而不是工程的名称
scrapyd-deploy -p <项目名称>
也可以指定版本号
scrapyd-deploy -p <项目名称> --version <版本号>
运行
$ curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
暂停
curl http://localhost:6800/cancel.json -d project=myproject -d job=6487ec79947edab326d6db28a2d86511e8247444
delproject.json 删除项目及其所有上载版本。
curl http://localhost:6800/delproject.json -d project=myproject
远端部署
- 配置python环境(ubuntu自带python3环境))
- 安装pip3:sudo apt install python3-pip
- 安装scrapy:pip3 install scrapy -i https://pypi.douban.com/simple/
- 如果安装失败添加如下依赖:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
- 安装scrapyd: pip3 install scrapyd
- 安装scrapyd-client: pip3 install scrapyd-client
- 添加爬虫运行的三方库:
- pip3 install requests
- pip3 install pymysql
- pip3 install pymongodb
修改scrapyd的配置文件,允许外网访问
- 查找配置文件的路径:find -name default_scrapyd.conf
- 修改配置文件: sudo vim 路径
- 注意:此时启动scrapayd服务6800端口还不能访问,需要把ind_address改为ind_address = 0.0.0.0
要去服务器安全组配置
进入服务安全组选项添加安全组
添加成功后,点击修改规则,添加如下信息(配置目的:允许访问6800端口)
完成后返回到云主机菜单,找到配置安全组菜单,跟换为刚才添加的安全组
之后跟上面的部署步骤一样
Gerapy使用
介绍:
Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy、Scrapyd、Scrapyd-Client、Scrapy-Redis、Scrapyd-API、Scrapy-Splash、Jinjia2、Django、Vue.js 开发,Gerapy 可以帮助我们:
- 更方便地控制爬虫运行
- 更直观地查看爬虫状态
- 更实时地查看爬取结果
- 更简单地实现项目部署
- 更统一地实现主机管理
- 提供在线编辑代码功能
Greapy 安装和使用
gerapy下载
pip3 install gerapy
查看是否安装成功
gerapy
初始化gerapy
gerapy init
执行完毕之后,便会在桌面下生成一个名字为 gerapy 的文件夹,接着进入该文件夹,可以看到有一个 projects 文件夹
初始化数据库
进入到gerapy文件夹下
cd gerapy
执行(会在gerapy目录下生产一个sqlite数据库,同时创建数据表,数据库中会保存各个主机配置信息、部署版本等)
gerapy migrate
运行gerapy服务
gerapy runserver
访问gerapy管理界面,在浏览器中输入如下网址
http://127.0.0.1:8000
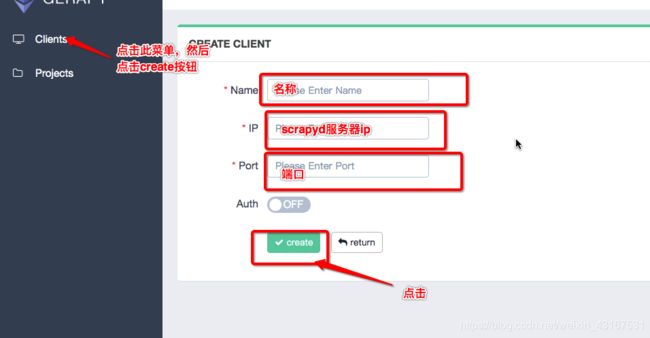
在主机管理中添加个台主机的Scrapyd运行地址和端口,并设置名称,然后个台主机则会出现在主机列表中,Gerapy会监控个台主机的运行状态。

之后就可以实现调度了
处理可以管理控制已经部署好的项目外,Gerapy还支持打包和部署项目
进入到gerapy文件夹下,找到projects目录
cd gerapy
```在此页面进行打包和部署项目到指定服务器
部署完成后就可以运行和管理爬虫项目了