pytorch入坑三 | nn.module
文章目录
-
-
- 1.两个基本结构
-
- 1.1 Parameter(参数)
- 1.2 Containers(容器)
-
- 1.2.1 Module(模型)
-
- 核心功能
- 查看模块
- 类型转换
- 设置功能
- 注册功能
- 1.2.2 Sequential(序列)
- 1.2.3 ModuleList模型列表
- 1.2.4 ParameterList参数列表
- 2.常用的网络层
-
之前我们介
autograd, 但对于比较大的复杂网络来说,
autograd 会显得有点太底层了,而在大多数的现有的深度学习框架,比如
Keras,
Tflearn 中都会提供更高级抽象的计算图来更有效的建立神经网络,我们也更习惯于利用优化器来调整带有可学习参数的网络层。
在 pytorch 中,nn包就为我们提供了这些大致可以看成神经网络层的模组,模组利用Variable 作为输入并输出 Variable, nn包同时也为训练模型定义了一些有用的损失函数(loss function) 。
1.两个基本结构
1.1 Parameter(参数)

Parameters 是 Variable的子类,但有两个不同点:
-
Parameters与modules一起使用时会有一些特殊的属性,其会被自动加到Module的parameters()迭代器中,Variable赋值给modules不会产生这样的效果。 -
Parameters不能被volatile, 而且默认设置requires_grad=True。
使用很简单:
torch.nn.Parameter(data, requires_grad)
data为tensor, requires_grad 默认为True,即在BP 的过程中会对其求微分。
>> custom_para=torch.nn.Parameter(data=torch.Tensor([1]),requires_grad=True)
>> custom_para
Parameter containing:
1
[torch.FloatTensor of size 1]
1.2 Containers(容器)
1.2.1 Module(模型)
class torch.nn.Module
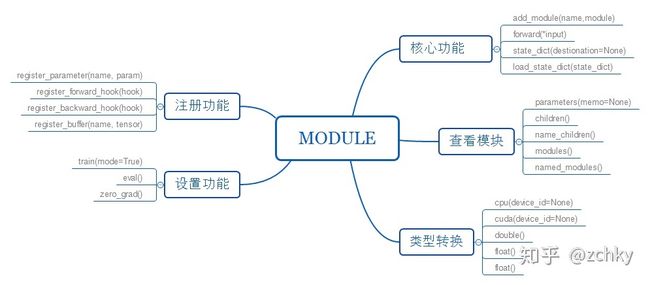
这是所有网络的基类,Modules也可以包括其他Modules,运行使用树结构来嵌入,可以将子模块给模型赋予属性,从下列看出,self.conv1 , self.conv2是模型的子模型。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1 = nn.Conv2d(1, 20, 5)# submodule: Conv2d
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
核心功能
add_module(name,module)将子模块加入当前的模块中,被添加的模块可以name来获取。forward(*input)每次运行时都会执行的步骤,所有自定义的module都要重写这个函数。state_dict(destination=None)返回一个字典,保存module的所有状态。load_state_dict(state_dict): 用来加载模型参数。
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv", nn.Conv2d(10, 20, 4))
#self.conv = nn.Conv2d(10, 20, 4) 和上面这个增加module的方式等价
>> model = Model()
>> print(model.conv)
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
查看模块
parameters(memo=None): 返回一个包含模型所有参数的迭代器,一般用作optimizer参数。children(): 返回当前模型子模块的迭代器。name_children(): 返回包含模型当前子模块的迭代器,yield模块名字和模块本身。modules(): 返回一个包含当前模型所有模块的迭代器。named_modules(): 返回包含网络中所有模块的迭代器,yielding模块名和模块本身。
注:modules()返回的iterator不止包含子模块,而children()只包含子模块,这是区别。
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv", nn.Conv2d(10, 20, 4))
self.add_module("conv1", nn.Conv2d(20 ,10, 4))
>> model = Model()
>> for module in model.modules():
>> print(module)
Model (
(conv): Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
(conv1): Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
)
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
>> for children in model.children():
>> print(module)
Conv2d(10, 20, kernel_size=(4, 4), stride=(1, 1))
Conv2d(20, 10, kernel_size=(4, 4), stride=(1, 1))
类型转换
cpu(device_id=None):将所有的模型参数(parameters)和buffers复制到CPUcuda(device_id=None):将所有的模型参数(parameters)和buffers赋值GPUdouble():将parameters和buffers的数据类型转换成doublefloat(): 将parameters和buffers的数据类型转换成float。half():将parameters和buffers的数据类型转换成half。
设置功能
train(mode=True):将module设置为training mode,只影响dropout和batchNorm。eval(): 将模型设置成evaluation模式,只影响dropout和batchNorm。zero_grad(): 将module中的所有模型的梯度设置为0。
注册功能
register_parameter(name, param):向module添加parameter,可以通过name获取。register_forward_hook(hook):在module上注册一个forward hook。 每次调用
forward()计算输出的时候,这个hook就会被调用。
register_backward_hook(hook):在module上注册一个bachward hook。每次计算
module的inputs的梯度的时候,这个hook会被调用
register_buffer(name, tensor):给module添加一个persistent buffer,通常用
来保存一个不需要看成模型参数的状态。
1.2.2 Sequential(序列)
class torch.nn.Sequential(*args)
当你使用Sequential时,Modules会以传入的顺序来添加layer到容器中,也可以传入一个OrderedDict, 下面是个简单的例子:
# Example of using Sequential
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Example of using Sequential with OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
1.2.3 ModuleList模型列表
class torch.nn.ModuleList(modules=None)
将你的子模型保存在一个list中,可以像python list一样被索引,moduleList 中包含的modules已经被正确的注册,对所有module method可见。
参数说明:
modules(list,optional)– 将要被添加到MuduleList中的modules列表。
方法:
append(module): 添加模型,等价于list的append。extend(modules): 等价于list的extend。
例子:
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, l in enumerate(self.linears):
x = self.linears[i // 2](x) + l(x)
return x
1.2.4 ParameterList参数列表
class torch.nn.ParameterList(parameters=None)
ParameterList 可以像一般的Python list一样被索引。而且 ParameterList中包含的parameters 已经被正确的注册,对所有的module method可见。
参数说明:
parameters(list, optional)–a list of nn.Parameter
方法:
append(parameter): 添加模型,等价于list的append。extend(parameters): 等价于list的extend。
例子:
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(10, 10)) for i in range(10)])
def forward(self, x):
# ModuleList can act as an iterable, or be indexed using ints
for i, p in enumerate(self.params):
x = self.params[i // 2].mm(x) + p.mm(x)
return x
2.常用的网络层
pytorch给我们封装了许多的网络层,激活函数,和损失函数,距离函数等.
在这里我提几个比较常用的
卷积层:
class torch.nn.Conv1d()class torch.nn.Conv2d()- …
激活函数:
class torch.nn.Sigmoid
对每个元素运用Sigmoid函数,Sigmoid 定义如下:
f(x)=1/(1+e−x)f(x)=1/(1+e−x)