CTF逆向之小白入门必备基础知识
一、前言
CTF中主要有四个方向,web 逆向 密码 杂项,其中最难入门的,就是逆向啦。逆向由于需要汇编语言的基础,考验你对计算机底层原理的探究,所以很多时候不仅需要编程和安全基础,更需要有钻研编程原理的精神,和一定的逆向思维。
二、破解软件
逆向不仅仅破解软件,写注册机,有调试程序,找到深层次的bug,还有底层驱动的开发等等。
对软件进行破解
基本汇编指令
mov A B **将B的值复制到A里面去**
push A **将A压栈**
pop A **将A从栈中弹出来**
call Funtion **跳转到某函数**
ret --> 相当于 pop ip **从栈中pop出一个值放到EIP里面**
je jz **如果ZF(0标志位)=1,就跳转,否则跳过这条语句,执行下面的语句。

接下来,我们就来找一个软件下的dll文件开始我们的工作吧,我们用逆向来破解它
首先我们用我们的工具OllyDug打开软件的dll文件
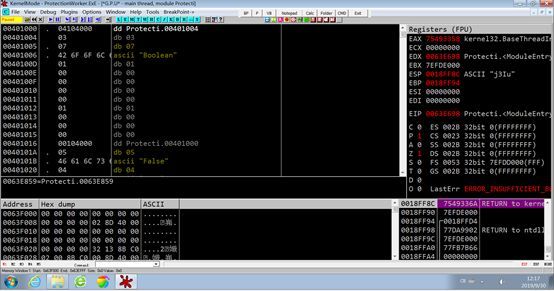
我们认识一下OllyDug的界面,它的左端是加载入内存的地址,第二列是机器码,中间部分是汇编窗口,右边部分是注释或者字符串显示的窗口。左下角以16进制或者ASCII码来显示文件的,右下角是栈的内容。
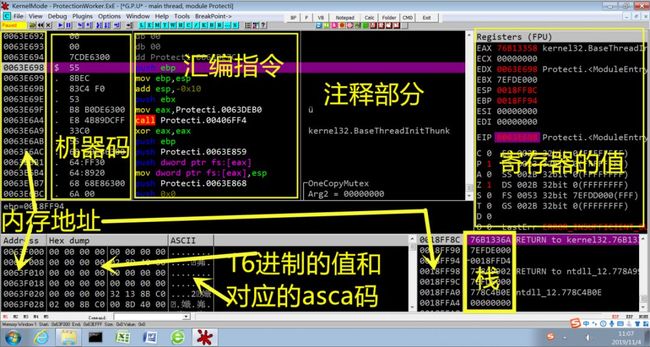
1.点击运行键运行,再点击中文搜索中的智能搜索
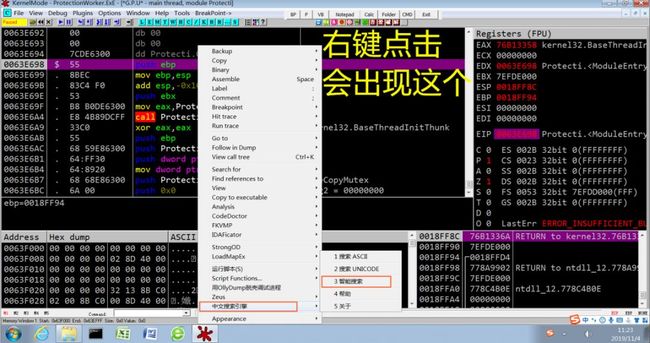
2.按下Ctrl + F ,搜索字符串中的关键字,比如 登陆失败、密码错误等

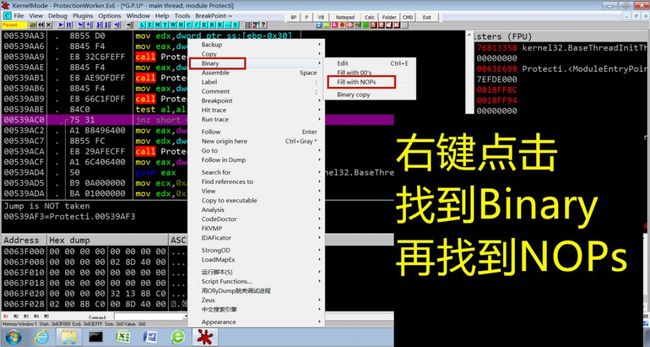
3.因为0x00539AF3地址处是由0x00539AC0的指令跳转过来的,所以这里我们把0x00539AC0的指令右键nop掉,这样在打开软件的时候就直接执行账号正确的指令了,这样这个软件就破解了
三、栈帧
如果你想用某个公式的话,那么肯要先理解这个公式,栈帧也是如此,当你想利用栈溢出的漏洞时,为什么栈溢出会造成这样的结果?是怎么做到的?栈帧的重要性就不言而喻啦
栈帧基础知识
1.在32位系统中,堆栈每个数据单元的大小为4字节。小于等于4字节的数据,比如字节、字、双字和布尔型,在堆栈中都是占4个字节的;大于4字节的数据在堆栈中占4字节整数倍的空间。
2.ESP寄存器总是指向堆栈的栈顶,执行PUSH命令向堆栈压入数据时,ESP减4,然后把数据拷贝到ESP指向的地址;执行POP命令时,首先把ESP指向的数据拷贝到内存地址/寄存器中,然后ESP加4。EBP寄存器是用于访问堆栈中的数据,它指向堆栈中间的某个位置,函数的参数地址比EBP的值高,而函数的局部变量地址比EBP的值低,因此参数或局部变量总是通过EBP加减一定的偏移地址来访问的。
3.一个堆栈帧对应一次函数的调用。在函数开始时,对应的堆栈帧已经完整地建立了(所有的局部变量在函数帧建立时就已经分配好空间了,而不是随着函数的执行而不断创建和销毁的);在函数退出时,整个函数帧将被销毁。
4.我们把函数的调用者称为caller(调用者),被调用的函数称为callee(被调用者)。
接下来,我们用一段示例代码来走进栈帧
int foo(int a, int b)
{
int c = a+1;
int d = b+1;
int e = c + d ;
return e;
}
int main()
{
int result=foo(3,4);
return 0;
}1. 首先main函数,也是函数,所以main函数也有它自己的栈帧
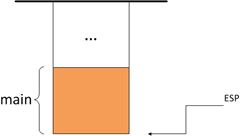
2. 然后,程序执行到了int result=foo(3,4);,然后根据调用约定入栈,即参数都是从右往左入栈的,因此b=4先压入堆栈,a=3后压入
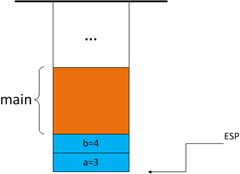
3. 当函数结束时,代码要返回到上一层函数继续执行,那么,函数如何知道该返回到哪个函数的什么位置执行呢?当上一个函数在 Call function的时候,这时的EIP已经指向了call function 的下一条指令,然后在把参数压栈完之后,就把EIP的值(就是进入被调函数的下一条指令的地址)也压入栈中,当函数指向完成时,再把这个返回地址 pop到EIP中
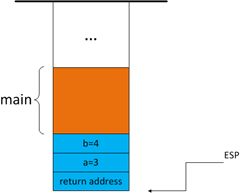
返回地址入栈后,代码跳转到被调用函数foo中执行。到目前为止,堆栈帧的前一部分,是由caller构建的;而在此之后,堆帧的其他部分是由callee来构建
4.在foo函数中,首先将EBP寄存器的值压入堆栈。因为此时EBP寄存器的值还是用于main函数的,用来访问main函数的参数和局部变量的,因此需要将EBP暂存在堆栈中,在foo函数退出时恢复
5.并且将ESP(此时的栈顶)的值赋给EBP

6.前面的环节搞完之后,整个栈帧的核心的初步理解是差不多了,接下来就是对foo函数的局部变量分配地址空间,将函数中使用到的通用寄存器入栈,暂存起来,以便函数结束时恢复。至此,一 个完整的堆栈帧建立起来了

7.当然栈帧的知识不止有这么一点,想了解更多的话,就百度一下吧
更多信息安全教程(upload-labs靶场笔记 SQL注入 新手向入门系列教程)
尽在蝰蛇安全实验室(微信公众号)呦
我们专注于打造清晰准确 新手友好的信息安全公众号
期待您的关注与支持
