特征选择

特征选择主要就是进行这两步操作
去除特征
我们不仅要添加新的特征,当特征不符合时我们还要去除特征。下面列举了一些可能的去除特征的原因。

注意:特征不等于信息
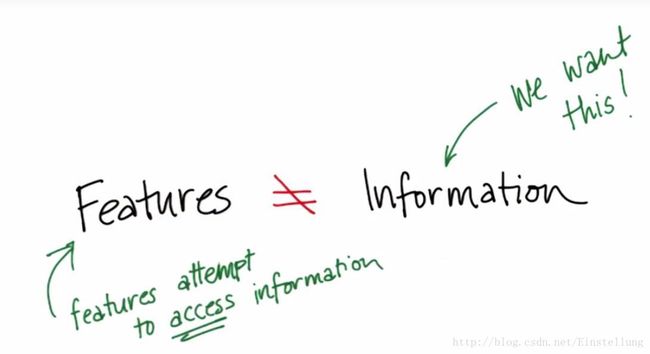
特征实际上是信息特点的一个载体,他和信息实际上是两个概念。不要搞混。我们希望有尽量少的特征和尽量多的信息。这样在分类的时候可以减少出错概率。
如果你只有特征而没有信息,那就应该删除这个特征,因为这个特征很有可能会引起算法漏洞。这个特征对应的指标会十分强烈,他没有对应的自己的信息,信息通常是通过算法人为添加的。最后拟合的时候可能就对应的100%的正确率,而这通常情况下是不可能发生的。
特征选择
单变量特征选择
在 sklearn 中自动选择特征有多种辅助方法。多数方法都属于单变量特征选择的范畴,即独立对待每个特征并询问其在分类或回归中的能力。
sklearn 中有两大单变量特征选择工具:SelectPercentile 和 SelectKBest。 两者之间的区别从名字就可以看出:SelectPercentile 选择最强大的 X% 特征(X 是参数),而 SelectKBest 选择 K 个最强大的特征(K 是参数)。
TfIdf向量器中的特征选择
### text vectorization--go from strings to lists of numbers
# df是document frequency的缩写
# max_df的意思是最大丢弃频率,也就是说在50%的文件中都出现这一个单词,那么这个单词会被丢弃
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
features_train_transformed = vectorizer.fit_transform(features_train)
features_test_transformed = vectorizer.transform(features_test)
### feature selection, because text is super high dimensional and
### can be really computationally chewy as a result
# 我们知道停止词是无用的特征,事实上除此之外我们还舍弃了大量的特征,只保留了1%的最好的特征用于分类器。
# 我们这样做实际上是切掉最表层的包含最多信息的特征,然后专注于用于分类器的东西
selector = SelectPercentile(f_classif, percentile=1)
selector.fit(features_train_transformed, labels_train)
features_train_transformed = selector.transform(features_train_transformed).toarray()
features_test_transformed = selector.transform(features_test_transformed).toarray()
通过上面丢弃50%的单词出现频率以及只保留1%的特征在这里再次强调特征和信息不是一个概念。我们可能丢弃了绝大多数的特征,但是对于分类器的精度可能并没有什么影响。事实上,由于特征更少,他可能运行更快,效果更好。
因此当我们在处理有大量的数据,特别是高维数据的时候,数据中包含大量特征,应当对这些特征持怀疑态度。思考哪些特征能够实现最高性价比是一件极为重要的事。
偏差、方差困境

如图所示,如果特征使用较少,往往队长数据不会很敏感,会过度简化,导致偏差较高。
反之,如果用的特征较多,会导致对于数据过于敏感,使方差过高。
我们希望特征越少越好,拟合的越大越好。但这显然是矛盾的。为此我们只能在二者之间寻求一个平衡点。以较少的特征,实现较大的拟合。
下面举一个过拟合的糟糕例子,以便可以形成直观印象。
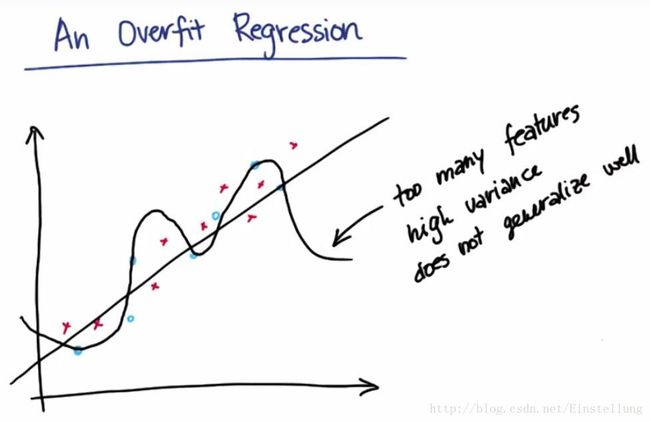
正则化
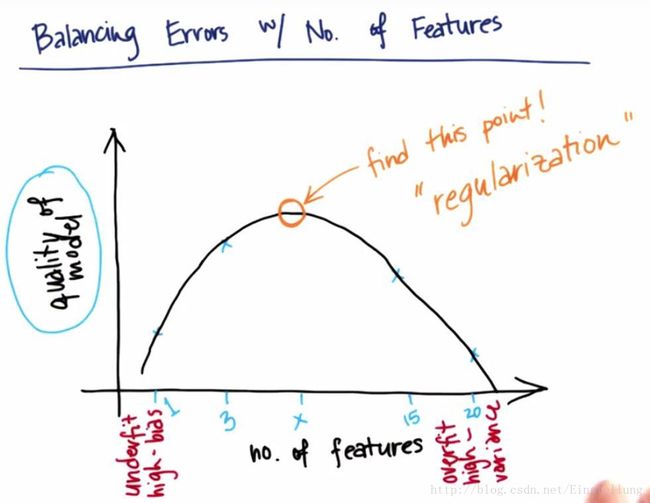
如图所示,特征过少的时候,数据质量非常糟糕,偏差过高,导致欠拟合。而特征过多的时候,方差有比较高,容易导致过拟合。如果我们将数据质量用一条线连接起来,我们可以发现有一个点对应的数据质量有最高值,我们的目的就是找到这个数据质量最好的值。我们可以使用正则化的方法
能够非常有效的词用正则化的一个地方就是回归
正则化是处理额外特征的一种方法
Lasso(套索)回归
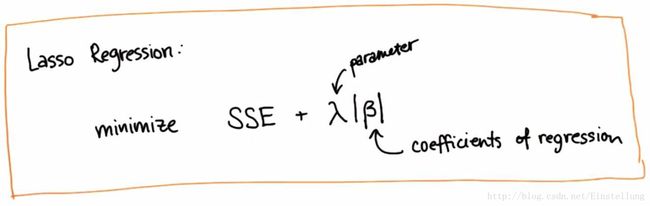
如图所示为Lasso回归的公式,他不仅要求最大限度的降低拟合过程中的平方误差,他还要最大化的减少使用中的特征数量。所以加入了第二项。其中 λ 为惩罚参数, λ|β| 描述的就是使用特征的数量。
这个公式也就是说我回归适当拟合得到的好处SSE,必须比使用额外特征造成的损失更大。也就是说,特征越多SSE会越小。但同时, λ|β| 也会越大。我们目的是找到一个总体最小值。
Lasso回归可以自动的考虑惩罚参数,这样,他就能帮你指出哪些特征对你的回归有最重要多的影响,它可以发现或完全删除对你用处不大的特征系数。
他的具体操作是这样的:
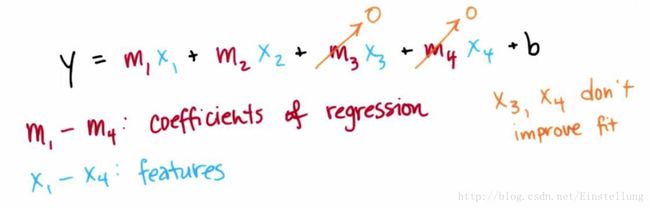
如图所示,我们可能有一个这样的特征多项式,如果x1和x2是对回归有较大影响的特征,而x3和x4是对回归没有较大影响的特征。如果一个新特征的改善拟合程度,无法超出包含此特征的惩罚,就不添加此特征,不添加就是将系数设置为0。
正则化是对额外特征添加惩罚项,它能够自动帮你选择。
Lasso编码
from sklearn import linear_model.Lasso
features,labels = get_my_data()
regression = Lasso()
# 注意回归是一种监督学习,因此进行拟合时要同时输入特征和标签
regression.fit(features, labels)
# 通过执行这个语句可以找到回归系数,回归系数大的表明对于这个特征是重要特征
print regression.coef_