计算机字符编码知识记录
字符集和字符编码
看战争片时,经常会看到剧中出现收发电报的情况,发报员拿着密码本将文字翻译成某种码文发出,收报员使用同样的密码本将收到的码文再翻译成文字。这个密码本其实是发送方和接收方约定的一套电码表,电码表中规定了文字和电码之间的一一对应关系。
在计算机之间,同样无法直接传输一个一个的字符,而只能传输二进制数据。为了使发送的字符信息能以二进制数据的形式进行传输,同样需要使用一种“密码本”,它叫做字符码表。字符码表是一种可以方便计算机识别的特定字符集,它是将每一个字符和一个唯一的数字对应而形成的一张表。针对不同的文宇,每个国家都制定了自己的码表。
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
编码和解码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。一般来说,把字符串转换成计算机识别的字节序列称为编码。把字节序列转换为普通人能看懂的明文字符串称为解码。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。
常见的字符编码
| 字符编码 | 发布时间 | 简述 |
| ASCII | 1967 | 美国信息交换标准代码,使用7位二进制数来表示所有的大小写字母、数字0~9、标点符号以及在美式英语中使用的特殊控制字符 |
| GB2312 | 1980 | 中文码表,也就是信息交换用汉字编码字符集,兼容ASCII,每个英文占1个字节,中文占2个字节(2个字节都为负数,最高位都为1) |
| GBK | 1995 | 汉字内码扩展规范,(GBK即“国标”、“扩展”汉语拼音的第一个字母),兼容GB2312,每个英文占1个字节,中文占2个字节(第1个字节为负数,第二个字节可正可负) |
| GB18030-2000 | 2000 | 全名是《信息技术 汉字编码字符集基本集的扩充》,GB18030-2000是GBK的取代版本,它的主要特点是在GBK基础上增加了CJK统一汉字扩充A的汉字。 |
| GB18030-2005 | 2005 | 在GB18030-2000基础上增加了CJK统一汉字扩充B的汉字。 |
| Unicode | 1991 | 国际标准码,它为每一种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求,每个字符占2个字节。 |
| UTF-8 | 1993 | 针对Unicode的可变长编码,可以用来表示Unicode标准中的任何字符,其中,英文占1个字节,中文占3个字节,这是程序开发中最常用的字符编码 |
关于ANSI
我们在使用Windows的文本文档时,都会看到这个编码:ANSI

图:记事本默认编码格式
ANSI,American National Standard Institite,美国国家标准协会的一种编码标准。ANSI编码是一种对ASCII码的扩展(ASCII则是ANSI的标准),为使计算机支持更多语言(非拉丁语系的语言),通常用0x00~0x7f (即十进制下的0到127)范围的1 个字节来表示 1 个英文字符,超出一个字节的 0x80~0xFFFF 范围来表示其他语言的其他字符,即扩展的ASCII编码。也就是说,ANSI码仅在前128(0-127)个与ASCII码相同,之后的字符全是某个国家语言的所有字符。
在CJK(Chinese Japanese Korean)系统中,ANSI还常常指代包括多字节内码的编码。中国制定了GB2312编码,用来把中文编进去,日本把日文编到SHIFT_JIS里,韩国把韩文编到EUC-KR里,各国有各国的标准。ANSI编码,就是一种未经国际标准化(也没办法标准化,因为扩展部分的内码存在交集)的兼容ASCII编码的,非Unicode字符集编码。
所以,ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码。英文系统中ANSI编码其实是ASCII编码,中文系统中ANSI编码其实是GBK编码,而韩文系统中ANSI编码其实是EUC-KR编码。不同语言之间的ANSI码之间不能互相转换,这就会导致在多语言混合的文本中会有乱码。
在不同的语言系统中,计算机怎么区分ANSI编码?
微软用一个叫“Windows code pages”(在命令行下执行chcp命令可以查看当前code page的值)的值来判断系统默认编码,比如:简体中文的code page值为936(它表示GBK编码,win95之前表示GB2312,详见:维基百科:代码页936),也就是说GB2312或GBK是ANSI的一个代码页,这个代码页是936。繁体中文的code page值为950(表示Big-5编码)。

图:使用chcp查看code page值
我们在cmd里编译编码格式为UTF-8的java代码时,可能会遇到下图中的情况:

图:DOS下编译java代码错误
public class demo
{
public static void main(String args[]) {
int num; // 声明一个整型变量num
num = 3; // 将整型变量赋值为3
// 输出字符串,这里用"+" 号连接变量
System.out.println("这是数字"+num);
System.out.println("我有"+num+" 本书!");
}
}编译器提示“编码GBK的不可映射字符”意思就是这个字符无法转换(映射)为GBK编码的字符。本来是英文的提示,直译过来就变成那样子了。java文件的编码为UTF-8,命令提示符的输出编码格式为GBK。系统默认的编码输出方式和文件编码方式不一样时就会出错。
要知道系统编码信息可以使用Python查看:
import sys
import locale
print sys.getdefaultencoding()
print locale.getdefaultlocale()
print sys.stdout.encoding
print sys.stdin.encoding 
图:python输出相关系统编码信息
系统的缺省编码(一般就是ASCII):sys.getdefaultencoding()
系统的当前编码:locale.getdefaultlocale()
终端的输出编码:sys.stdout.encoding
终端的输入编码:sys.stdin.encoding
从输出结果中可以看到系统默认编码是ASCII,系统当前编码为cp936,cp936也就是GBK编码,并且终端的输入输出编码都是GBK,这也可以解释为什么前面的java代码会提示“编码GBK的不可映射字符”。
使用终端编译java代码,在Notepad++里可以将编码转换为ANSI,在中文系统里就是GBK。不要选择直接使用ANSI编码,那样会乱码。
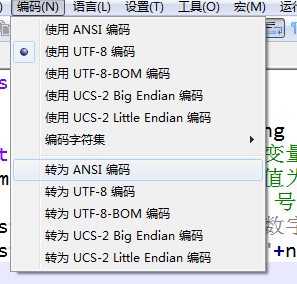
图:转为ANSI编码
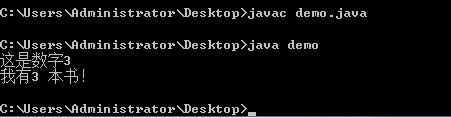
图:转换编码后运行成功
以下这段java代码通过编码解码方式验证cmd使用的是GBK编码:
import java.util.*;
public class demo {
public static void main(String[] args) throws Exception {
String str = "测试";
byte[] b1 = str.getBytes();// 使用默认的码表编码
System.out.println(Arrays.toString(b1));// 打印出字节数组的字符串形式
String result1 = new String(b1, "GBK");// 使用GBK解码
System.out.println(result1);// 打印解码后的字符串
byte[] b2 = str.getBytes("GBK");// 使用GBK编码
System.out.println(Arrays.toString(b2));// 打印出字节数组的字符串形式
String result2 = new String(b2, "GBK");// 使用GBK解码
System.out.println(result2);// 打印解码后的字符串
byte[] b3 = str.getBytes("UTF-8");// 使用UTF-8编码
System.out.println(Arrays.toString(b3));// 打印出字节数组的字符串形式
String result3 = new String(b3, "UTF-8"); //使用UTF-8解码
System.out.println(result3);// 打印解码后的字符串
}
}

图:编码后解码的输出内容
参考
- 字符编码ANSI和ASCII区别、Unicode和UTF-8区别
- ANSI是什么编码?
- ASCII和ANSI是同一种编码吗?
- 字符集和字符编码(Charset & Encoding)
- python输出系统编码
- 解决 java “错误:编码GBK 的不可映射字符”
- 维基百科:代码页936
- 百度百科:美国国家标准学会
- 百度百科:ANSI
- 百度百科:ASCII
- 百度百科:GB2312
- 百度百科:GBK
- 百度百科:GB18030