sklearn -特征工程-预处理
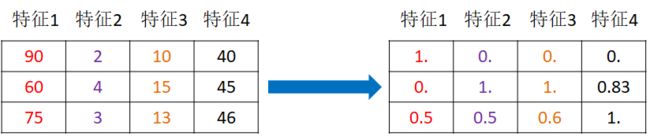
1 归一化:列数据映射到0-1之间(受异常点影响)
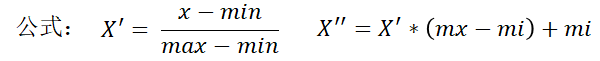

api:
from sklearn.preprocessing import MinMaxScaler
案例:
from sklearn.preprocessing import MinMaxScaler
def minmaxscaler():
data = [[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
mms = MinMaxScaler(feature_range=(0,1))
data = mms.fit_transform(data)
print(data)
结果
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]
2 标准化
归一化受异常点影响太大,标准化基本不受异常点影响
反应偏移平均值的程度。
负,小于平均值
正大于平均值。
绝对值越大,偏移量越大
公式
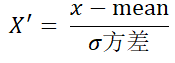

api:
from sklearn.preprocessing import StandardScaler
代码:
from sklearn.preprocessing import StandardScaler
def standarscaler():
data =[[1., -1., 3.],
[2., 4., 2.],
[4., 6., -1.]]
ss = StandardScaler()
data = ss.fit_transform(data)
print(data)
standarscaler()
[[-1.06904497 -1.35873244 0.98058068]
[-0.26726124 0.33968311 0.39223227]
[ 1.33630621 1.01904933 -1.37281295]]
缺失值填充:
numpy.NaN的填充,例如填充为平均值
api
from sklearn.preprocessing import Imputer
代码
from sklearn.preprocessing import Imputer
import numpy as np
def full():
data = [[1,2,3],
[2,np.NaN,1],
[3,4,1]]
imputer = Imputer(missing_values='NaN',strategy='mean',axis=0) # 0是列,1是行
data = imputer.fit_transform(data)
print(data)
full()
[[1. 2. 3.]
[2. 3. 1.]
[3. 4. 1.]]