!!!Chapter 7 The Application Layer
7.1 DNS --- The Domain Name System
Theoretically, programs could refer to web pages, mailboxes by using the network(IP) addresses of the computer which they are stored.
Back in the ARPANET days, there was simply a file, hosts.txt, that listed all the computer names and their IP addresses.
Very briefly, the way DNS is used is as follows. To map a name onto an IP address, an application program calls a library procedure called the resolver, passing it the name as a parameter. The resolver sends a query containing the name to a local DNS server, which looks up the name and returns a response containing the IP address to the resolver, which then returns it to the caller. The query and response messages are sent as UDP packets. Armed with the IP address, the program can then establish a TCP connection with the host or send it UDP packets.
7.1.1 The DNS Name Space
Conceptually, the Internet is divided into over 250 top-level domains, where each domain covers many hosts.
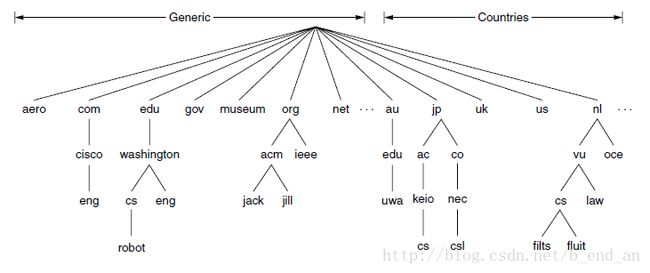
Each domain is named by the path upward from it to the root. The components are separated by periods.
Domain names are case-insensitive.
7.1.2 Domain Resource Records
Every domain, whether it is a single host or a top-level domain, can have a set of resource records associated with it. These records are the DNS database. For a single host, the most common resource record is just its IP address, but many other kinds of resource records also exist. When a resolver gives a domain name to DNS, what it gets back are the resource records associated with that name. Thus, the primary function of DNS is to map domain names onto resource records.
A resource record is a five-tuple:
Domain name Time to live Class Type Value
The Domain name tells the domain to which this record applies.
The Time to live field gives an indication of how stable the record is.(in seconds)
The third field of every resource record is the Class. For Internet information, it is always IN.
The Type field tells what kind of record this is. The most important record type is the A (Address) record. It holds a 32-bit IPv4 address of an interface for some host.
7.1.3 Name Servers
To avoid the problems associated with having only a single source of information, the DNS name space is divided into nonoverlapping zones.

Where the zone boundaries are placed within a zone is up to that zone’s administrator. Each zone is also associated with one or more name servers.
7.3 The World Wide Web
7.3.1 Architectural Overview
From the users’ point of view, the Web consists of a vast, worldwide collection of content in the form ofWeb pages, often just calledpages for short.
A piece of text, icon, image, and so on associated with another page is called ahyperlink.
The basic model behind the display of pages is also shown in Fig. 7-18. The browser is displaying a Web page on the client machine. Each page is fetched by sending a request to one or more servers, which respond with the contents of the page. The request-response protocol for fetching pages is a simple text-based protocol that runs over TCP, just as was the case for SMTP. It is called HTTP (HyperText Transfer Protocol). The content may simply be a document that is read off a disk, or the result of a database query and program execution. The page is a static page if it is a document that is the same every time it is displayed. In contrast, if it was generated on demand by a program or contains a program it is a dynamic page.

In this case, the cs.washington.edu server supplies the main page, the youtube.com server supplies an embedded video, and the google-analytics.com server supplies nothing that the user can see but tracks visitors to the site.
The Client Side
In essence, a browser is a program that can display a Web page and catch mouse clicks to items on the displayed page. When an item is selected, the browser follows the hyperlink and fetches the page selected.
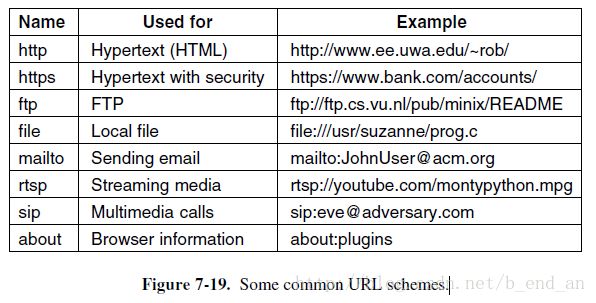
Each page is assigned a URL (Uniform Resource Locator) that effectively serves as the page’s worldwide name. URLs have three parts: theprotocol(also known as the scheme), the DNS name of the machine on which the page is located, and thepath uniquely indicating the specific page (a file to read or program to run on the machine).
7.3.2 Static Web Pages
HTML—The HyperText Markup Language
HTML is a markup language, or language for describing how documents are to be formatted.
The key advantage of a markup language over one with no explicit markup is that it separates content from how it should be presented.
A Web page consists of a head and a body, each enclosed by and tags (formatting commands), although most browsers do not complain if these tags are missing. The strings inside the tags are calleddirectives.
Some tags have (named) parameters, called attributes.
CSS—Cascading Style Sheets
The original goal of HTML was to specify the structure of the document, not its appearance. For example,
Deborah’s Photos
Deborah’s Photos A better alternative is the use of style sheets. Style sheets in text editors allow authors to associate text with a logical style instead of a physical style, for example, ‘‘initial paragraph’’ instead of ‘‘italic text.’’
CSS (Cascading Style Sheets) introduced style sheets to the Web with HTML 4.0.