Sklearn学习_02数据的预处理
对单个数据进行标准化
函数介绍
sklearn.preprocessing.scale(
X:{array-like, sparse matrix}, 需要进行变换的数据阵
axis=0:指分别按照列(0)或是整个样本(1)计算均数、标准差并进行变换
注意:在sklearn中没有按行计算均数的,若有需要则需将此矩阵进行转置。然后再进行列变化,最后再转置回原样即可
with_mean=True:是否中心化数据(移除均数)
with_std=True:是否均一化标准差(除以标准差)
copy=True:是否生成副本而不是替换原数据
)
代码解释
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn import datasets
boston = datasets.load_boston()
bostondf = pd.DataFrame(boston.data, columns=boston.feature_names)
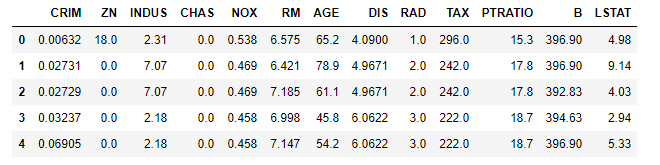
# 查看原始数据,默认显示前5行
bostondf.head()
运行结果:
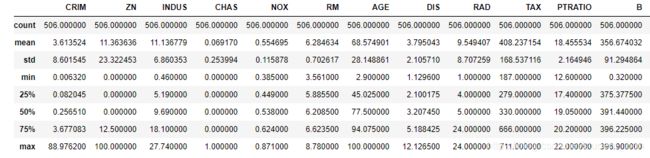
bostondf.describe()
对表格中的数据进行描述,结果如下:
以CRIM这一列为例,用sklearn对该列做数据的标准变换
from sklearn import preprocessing
# 对数据进行标化,做标准正太变换
x_scaled = preprocessing.scale(bostondf)
# 取出数据的前两行
x_scaled[:2]
结果如下

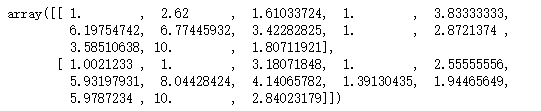
# 计算转换后的均数和标准差
x_scaled.mean(axis=0), x_scaled.std(axis=0)

从上图可以看出,每一列的均数都非常接近于0,标准差都为1。显然每一列都进行了标化
# 对整个矩阵统一做标化
X_scaled1 = preprocessing.scale(bostondf, axis=1)
X_scaled1[:2]
结果如下

# 分列进行计算
X_scaled1.mean(axis=0), X_scaled1.std(axis=0)

从上图看出,每一列的均数或者是标准差都没有规划到一个统一的数字,显然我们并没有按照列标化。但我们若是对整个数据做标准化呢?
# 对整个矩阵做计算
X_scaled1.mean(), X_scaled1.std()
![]()
看出均数与标准差都只有一个值。近似的可以认为整个数据的均数为0,标准差为1
# scale可以直接对单列的因变量做标准化
preprocessing.scale(boston.target)[:10]
![]()
对多个数据集使用标准化变换
可以使用API接口,将标准化变化方法设置为可调用的函数,每次直接调用即可
函数介绍
sklearn.preprocessing.StandardScaler(
copy=True:是否生成副本而不是替换原数据
with_mean=True:对稀疏矩阵无效
with_std=True:
)
StandardScaler类的属性:
scale_: ndarray, shape(n_features,)
mean_: array of floats with shape [n_features]
var_: array of floats with shape [n_features](方差)
n_samples_seen_: int
StandardScaler类的方法:
inverse_transform(X[, copy]) 将数据进行逆变换
partial_fit(X[,y]) 在线计算数据特征用于后续拟合
fit(X,[,y]) 计算数据特征用于后续拟合
transform(X[, y, copy]) 使用模型设定进行转换
fit_transform(X[,y]) 计算数据特征,并进行转换
get_params([deep]) 获取模型的参数设定
set_params(**params) 设置模型参数
代码解释
std = preprocessing.StandardScaler()
std.fit(bostondf)
# scale:标准差
std.mean_, std.scale_

此结果可以参考第二幅图中的数据来看
# 对数据阵的前两行使用模型设定进行转换
std.transform(bostondf[:2])

该结果与之前用scale方法相类似
缩放数据
通常是将数据转换至0~1,也可以将每个特征的最大绝对值转换至指定数值大小
class sklearn.preprocessing.MinMaxScaler(feature_range=(0,1), copy=true)
将数据缩放至指定的范围内
class sklearn.preprocessing.MaxAbsScaler(copy=true)
将数据的最大值缩放至1
代码解释
# 将数据缩放至1~10
scaler = preprocessing.MinMaxScaler((1,10))
scaler.fit_transform(bostondf)[:2]
数据正则化
sklearn.preprocessing.normalize(
X, axis=1, copy=True
norm = ‘l2’: ‘l1’, ‘l2’, or ‘max’, 用于正则化的具体范数
return_norm=False:是否返回所使用的范数
)
代码解释
# 数据正则化
X = [[-1., -1., 2.]]
X_normalized = preprocessing.normalize(X, norm='l2', return_norm=True)
X_normalized
![]()
就相当于-1/2.44948974,2/2.44948974
稳健标准化
将中位数和百分位数分别代替均数和标准差用于数据的标准化
此方法更加适用于已知离群值的数据,而之前讲的那些对有离群值的数据非常的敏感
函数介绍
sklearn.preprocessing.robust_scale(
X, axis=0, with_centering=True
quantile_range=(25.0, 75.0): 用于计算离散程度的百分位数
copy=True
)
class sklearn.preprocessing.RobustScaler(
with_centering=True, with_scaling=True
quantile_range=(25.0, 75.0), copy=True
)
代码解释
rscaler = preprocessing.RobustScaler()
rs = rscaler.fit_transform(bostondf)
rs[:2]

# 每一列的中位数
np.median(rs, axis=0), rs.mean(axis=0), rs.std(axis=0)

二值化
函数介绍
sklearn.preprocessing.binarizer(
X, copy=True
threshold=0.0 : 设定一个非负的阈值,小于等于阈值的赋值0,大于阈值则赋值1
)
class sklearn.preprocessing.Binarizer(threshold=0.0, copy=True)
代码解释
preprocessing.binarize(bostondf, threshold=2.5)[:2]
![]()
分类特征的重编码(哑变量化)
sklearn中的模型默认只能使用连续变量,无法识别分类特征
函数介绍
class sklearn.preprocessing.OneHotEncoder(
n_values=‘auto’,: int or array of ints, 每个特征的取值数
‘auto’:通过训练数据来自动确定
int:指定类别数,具体类别的取值必须在range(n_values)范围内
array:n_values[i]表示在X[:, i]中的类别数
categorical_features=‘all’: ‘all’ or array of indices or mask
将哪些列作为分类进行处理,其余列将直接在结果中输出
dtype = np.float : number type, 输出的数据类型
sparse = True:是否返回稀疏矩阵而不是普通矩阵
handle_unknown = ‘error’, : str, ‘error’ or ‘ignore’,有未知类别时如何处理
)
代码解释
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3],
[1, 1 ,0],
[0, 2, 1],
[1, 0, 2]])
enc.transform([[0, 1, 3]]).toarray() # toarray()转换成标准的矩阵
![]()
图中的前两个数对应原先的第一列,看出0的那一列取值为1;中间三个数对应原先的第二列,得出1的那一列取值为1;最后四个数对应的是原数据的最后一列,看出3的那一列取值为1
注意:sklearn在做数据转换时只能是数值型的,对于字符串是毫无办法的
用pandas完成分类特征的哑变量化
pandas不仅可以完成sklearn的工作,还可以很容易的完成字符串变量的数值化转换
函数介绍
pd.get_dummies(
data: 希望转换的数据框/变量列
prefix=None: 哑变量名称前缀
prefix_sep=’_’: 前缀和序号之间的连接字符,设定有prefix或列名时生效
dummy_na=False: 是否为NaNs专门设定一个哑变量列
columns=None:希望转换的原始列名,如果不设定,则转换所有符合条件的列
drop_first=False: 是否返回k-1个哑变量, 而不是k个哑变量
)# 返回值为数据框
代码解释
bostondf.RAD.value_counts()
bostondf.RAD.astype('int').astype('str').value_counts()

pd.get_dummies(bostondf.RAD.astype('int').astype('str'), prefix='RAD').head()
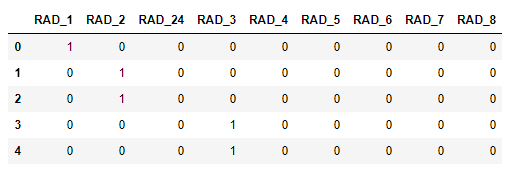
列名的排列,是由于字符串造成的
缺失值的补充
在sklearn中绝大部分的模型都不能自动处理缺失值,必须进行预处理
函数介绍
class sklearn.preprocessing.Imputer(
missing_values=‘NaN’: integer or ‘NaN’, 缺失值在数据中的表示方法
strategy=‘mean’: 填充方法,‘mean’, ‘median’, ‘most_frequent’
axis=0: integer,按列(0)还是行(1)进行填充
verbose=0:integer,控制填充的冗余度
copy=True
)
Imputer类的属性:
statistics_:array of shape (n_features, )按列填充时各属性的填充值
代码解释
from sklearn.preprocessing import Imputer
imp = Imputer()
# nan表示的是缺失值
imp.fit([[1, 2],
[np.nan, 3],
[7, 6]])
imp.transform([[np.nan, 2],
[6, np.nan]])
![]()
第一个缺失值的由来:(1+np.nan+7)/2
第二个缺失值的由来:(2+3+6)/3
# 查看填充的值
imp.statistics_
![]()
在实际的操作过程中,一般不采用这种方法
生成多项式特征(交互项)
建模时能找到对模型改善有贡献的二次交互项,至于其它高次项则很少需要考虑,原因是其不仅对建模改善贡献率小,还有可能造成过拟合
函数介绍
class skearn.preprocessing.PolynomialFeatures(
degree=2:希望计算的多项式的阶数
interaction_only=False:是否只计算交互项,而不包括原变量的任何高次项
include_bias=True:是否加入一个偏移量/常数项
)
代码解释
from sklearn.preprocessing import PolynomialFeatures
poly =PolynomialFeatures(degree=3, interaction_only=True)
polyer = poly.fit_transform(bostondf.iloc[:, [0, 1, 2, 3]])
# 列名分别为: cons 0 1 2 3 01 02 03 12 13 23 012 013 023 123
# 未生成的列: 00 000 0012 0123等
polyer[:1]
由于设置了degree=3,因此不会出现4阶的多项式
