android集成科大讯飞语音听写和语音合成
集成科大讯飞语音听写和语音合成,语音听写只是语音识别下面的一部分,别弄混淆了,由于科大讯飞暂未开放gradle引包方式,所以目前集成还是手动引包。我的流程是点击语音合成按钮然后播放语音,点击语音合成按钮说话然后识别出文字。
1、语音合成:文字转语音
2、语音听写:语音转文字,可以使用原生UI,也可以不使用,区别就是在于两者的监听方法不一样而已。
集成步骤:
一、下载语音听写和语音合成sdk包(离线语音是要收费的,所以选择在线语言)
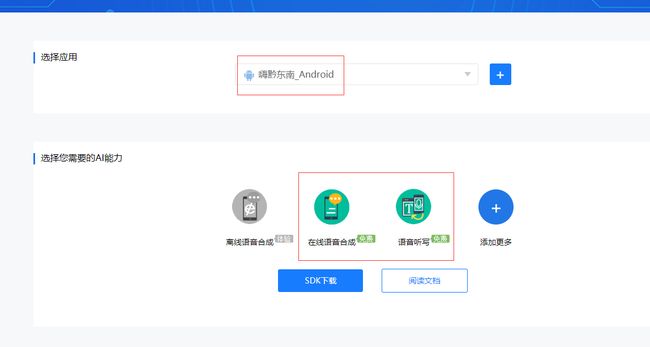
二、sdk引入项目,androidstudio项目目录结构如图所示,我的是webview加载的h5界面发起的语音请求,就算是原生,思路也一样,做好动态权限,不然是没有权限的,如果只是测试那你去手动开启麦克风权限也可以,但是不是科学的办法
1、原libs下面的Msc.jar引入android libs下面
2、iflytek引入assets下面
3、原libs下面的除Msc.jar其他包引入android 的jniLibs下面
4、build.gradle依赖里面加入
//科大讯飞语音包 implementation files('libs/Msc.jar')5、项目目录结构大致如下所示

三、加入权限,6.0之后需要做动态权限,不然只在清单文件里面申请是开启不了权限的。动态权限可以参考http://blog.csdn.net/u013144287/article/details/79298358这篇文章
四、初始化即创建语音配置对象,只有初始化后才可以使用MSC的各项服务。建议将初始化放在程序入口处(如Application、Activity的onCreate方法),初始化代码如下:这个代码写在activity里面
// 将“12345678”替换成您申请的APPID,申请地址:http://www.xfyun.cn
// 请勿在“=”与appid之间添加任何空字符或者转义符
SpeechUtility.createUtility(context, SpeechConstant.APPID +"=12345678");五、语音合成和语音听写代码写法(代码直接写在一个工具类JavaScriptUtils里面,只不过是利用构造函数把activity的context传过来而已)
//语音听写对象
private SpeechRecognizer mAsr;
//语音合成对象
private SpeechSynthesizer mTts;
//语音识别动画效果
private RecognizerDialog iatDialog;
//存储所有的语音识别文字
private String voiceResult = "";
/**
* 语音合成 文字转声音
*/
@JavascriptInterface
public void speechSynthesizerVoice(String strTextToSpeech){
//初始化语音合成
mTts= SpeechSynthesizer.createSynthesizer(mContext, new InitListener() {
@Override
public void onInit(int i) {
System.out.println("语音合成错误码:"+ i);
}
});
mTts.setParameter(SpeechConstant.VOICE_NAME, "xiaoyan");//设置发音人
mTts.setParameter(SpeechConstant.SPEED, "50");//设置语速
mTts.setParameter(SpeechConstant.VOLUME, "80");//设置音量,范围0~100
mTts.setParameter(SpeechConstant.ENGINE_TYPE, SpeechConstant.TYPE_CLOUD); //设置云端
mTts.startSpeaking(strTextToSpeech, mSynListener);
}
/**
* 语音合成监听器
*/
SynthesizerListener mSynListener = new SynthesizerListener(){
//会话结束回调接口,没有错误时,error为null
public void onCompleted(SpeechError error) {
mHandler.sendEmptyMessage(6007);
}
//缓冲进度回调
//percent为缓冲进度0~100,beginPos为缓冲音频在文本中开始位置,endPos表示缓冲音频在文本中结束位置,info为附加信息。
public void onBufferProgress(int percent, int beginPos, int endPos, String info) {}
//开始播放
public void onSpeakBegin() {}
//暂停播放
public void onSpeakPaused() {}
//播放进度回调
//percent为播放进度0~100,beginPos为播放音频在文本中开始位置,endPos表示播放音频在文本中结束位置.
public void onSpeakProgress(int percent, int beginPos, int endPos) {}
//恢复播放回调接口
public void onSpeakResumed() {}
//会话事件回调接口
public void onEvent(int arg0, int arg1, int arg2, Bundle arg3) {}
};
/**
* 语音听写 声音转文字
*/
@JavascriptInterface
public void speechRecognizerVoice() {
//初始化语音听写对象
mAsr = SpeechRecognizer.createRecognizer(mContext, new InitListener() {
@Override
public void onInit(int i) {
System.out.println("语音听写对象错误码" + i);
}
});
//初始化语音UI
// iatDialog = new RecognizerDialog(mContext, new InitListener() {
// @Override
// public void onInit(int i) {
// System.out.println("语音ui" + i);
// }
// });
// 清空参数
mAsr.setParameter(SpeechConstant.PARAMS, null);
// 设置听写引擎
mAsr.setParameter(SpeechConstant.ENGINE_TYPE, SpeechConstant.TYPE_CLOUD);
// 设置返回结果格式
mAsr.setParameter(SpeechConstant.RESULT_TYPE, "json");
// 设置语言
mAsr.setParameter(SpeechConstant.LANGUAGE, "zh_cn");
// 设置语言区域
mAsr.setParameter(SpeechConstant.ACCENT, "mandarin");
// 设置语音前端点:静音超时时间,即用户多长时间不说话则当做超时处理
mAsr.setParameter(SpeechConstant.VAD_BOS,"5000");
// 设置语音后端点:后端点静音检测时间,即用户停止说话多长时间内即认为不再输入, 自动停止录音
mAsr.setParameter(SpeechConstant.VAD_EOS, "5000");
//3.设置回调接口
// iatDialog.setListener(new RecognizerDialogListener() {
// @Override
// public void onResult(RecognizerResult recognizerResult, boolean isLast) {
// if (!isLast) {
// //解析语音
// String result = parseVoice(recognizerResult.getResultString());
// System.out.println("--------------------------------" + result);
// }
// }
//
// @Override
// public void onError(SpeechError speechError) {
// System.out.println(speechError.getErrorCode() + "*******" + speechError.getErrorDescription());
// }
// });
// //4.开始听写
// iatDialog.show();
mAsr.startListening(new RecognizerListener() {
@Override
public void onVolumeChanged(int i, byte[] bytes) {
Message message = new Message();
message.what = 6005;
message.obj = i;
mHandler.sendMessage(message);
}
@Override
public void onBeginOfSpeech() {
System.out.println("开始讲话");
}
@Override
public void onEndOfSpeech() {
System.out.println("结束讲话");
}
@Override
public void onResult(RecognizerResult recognizerResult, boolean b) {
if (!b) {
//解析语音
voiceResult = voiceResult + parseVoice(recognizerResult.getResultString());
}else{
Message message = new Message();
message.what = 6006;
message.obj = voiceResult;
mHandler.sendMessage(message);
}
}
@Override
public void onError(SpeechError speechError) {
}
@Override
public void onEvent(int i, int i1, int i2, Bundle bundle) {
}
});
}
/**
* 取消语音识别
*/
@JavascriptInterface
public void cancelSpeechRecognizerVoice(){
if(mAsr != null){
mAsr.cancel();
}
}
/**
* 停止语音识别
*/
@JavascriptInterface
public void stopSpeechRecognizerVoice(){
if(mAsr != null){
mAsr.stopListening();
}
}
/**
* 解析语音json
*/
public String parseVoice(String resultString) {
Gson gson = new Gson();
Voice voiceBean = gson.fromJson(resultString, Voice.class);
StringBuffer sb = new StringBuffer();
ArrayList ws = voiceBean.ws;
for (Voice.WSBean wsBean : ws) {
String word = wsBean.cw.get(0).w;
sb.append(word);
}
return sb.toString();
}
/**
* 语音对象封装
*/
public class Voice {
public ArrayList ws;
public class WSBean {
public ArrayList cw;
}
public class CWBean {
public String w;
}
} 上面方法是提供给js调用的,这是h5才会这么干,不过思路差不多哈哈,语音听写里面注释的部分就是调用原生科大讯飞UI,测试时候调用起来是这样的
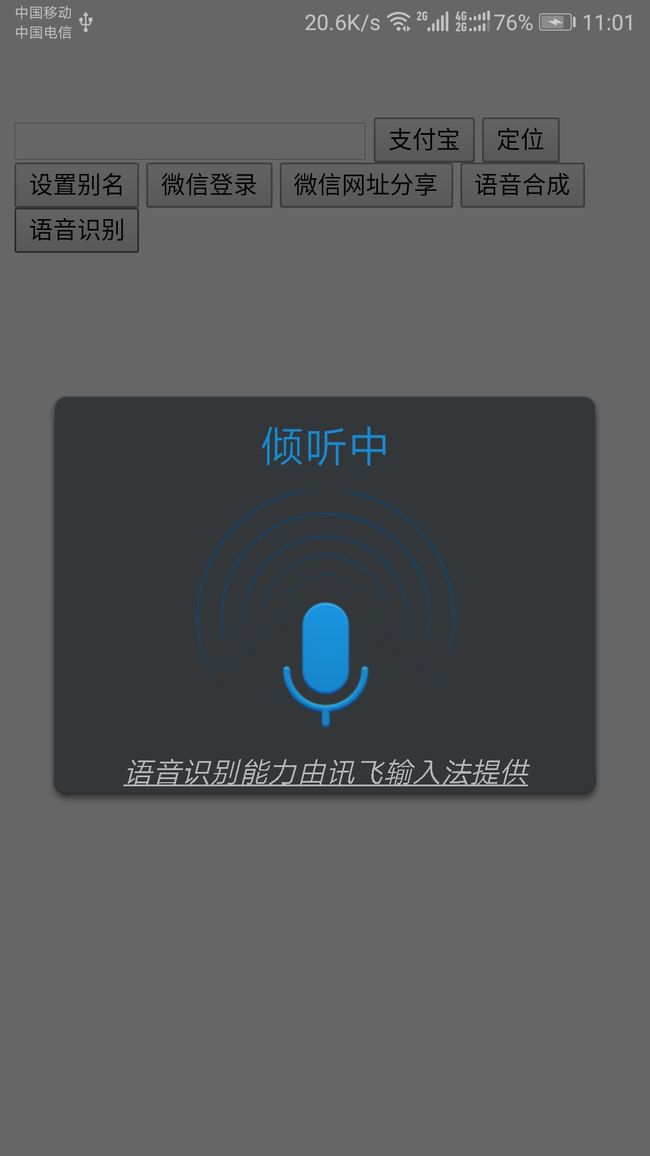
自此,也就集成成功了