linux的文件系统和虚拟文件系统(VFS)
http://www.ibm.com/developerworks/cn/linux/l-cn-hardandsymb-links/
1.软链接和硬链接的区别
我们知道文件都有文件名与数据,数据分两部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块
为解决文件的共享使用,Linux 系统引入了两种链接:硬链接 (hard link) 与软链接(又称符号链接,即 soft link 或 symbolic link)。链接为 Linux 系统解决了文件的共享使用,还带来了隐藏文件路径、增加权限安全及节省存储等好处。若一个 inode 号对应多个文件名,则称这些文件为硬链接。硬链接就是同一个文件使用了多个别名
由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制:
- 软链接有自己的文件属性及权限等;
- 可对不存在的文件或目录创建软链接;
- 软链接可交叉文件系统;
- 软链接可对文件或目录创建;
- 创建软链接时,链接计数 i_nlink 不会增加;
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。
- 一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
2.Linux VFS
Linux 有着极其丰富的文件系统,大体上可分如下几类:
-
网络文件系统,如 nfs、cifs 等; -
磁盘文件系统,如 ext4、ext3 等; -
特殊文件系统,如 proc、sysfs、ramfs、tmpfs 等。
实现以上这些文件系统并在 Linux 下共存的基础就是 Linux VFS(Virtual File System 又称 Virtual Filesystem Switch),即虚拟文件系统。VFS 作为一个通用的文件系统,抽象了文件系统的四个基本概念:文件、目录项 (dentry)、索引节点 (inode) 及挂载点,其在内核中为用户空间层的文件系统提供了相关的接口。VFS 实现了 open()、read() 等系统调并使得 cp 等用户空间程序可跨文件系统。VFS 真正实现了上述内容中:在 Linux 中除进程之外一切皆是文件。
Linux VFS 存在四个基本对象:超级块对象 (superblock object)、索引节点对象 (inode object)、目录项对象 (dentry object) 及文件对象 (file object)。超级块对象代表一个已安装的文件系统;索引节点对象代表一个文件;目录项对象代表一个目录项,如设备文件 event5 在路径 /dev/input/event5 中,其存在四个目录项对象:/ 、dev/ 、input/ 及 event5。文件对象代表由进程打开的文件。为文件路径的快速解析,Linux VFS 设计了目录项缓存(Directory Entry Cache,即 dcache)。
3.文件的打开过程
open()系统调用的过程如下:
1.查看system-wide open-file table(系统打开文件表)中是否有该文件,即查看该文件是否已经被其他进程打开了
2.如果存在,那么该进程会在自己的per-process open-file table(进程打开文件表)中,建立一个项目,指向system-wide open-file table中的该文件
3.如果不存在,则需要根据file name在directory中查找该file,通常directory中的部分内容在cache中,这样可以加快搜索速度。
4.一旦文件被找到,那么FCB(file control block)文件控制块会被复制到system-wide open-file table中,该表不仅仅保存FCB,而且记录每个文件被多少个进程打开
5.接下来,在per-process open-file table(进程打开文件表)中,简直一个entry,指向进程打开文件表中该项目
当进程close()一个文件时:
1.该进程的per-process open-flle table中的对应项会被删除,系统打开表中的该文件计数器会减1
2.如果系统打开表中的计算为0,那么删除该文件项
4.inode的理解
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号;其次,通过inode号,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
目录(directory)也是一种文件,目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
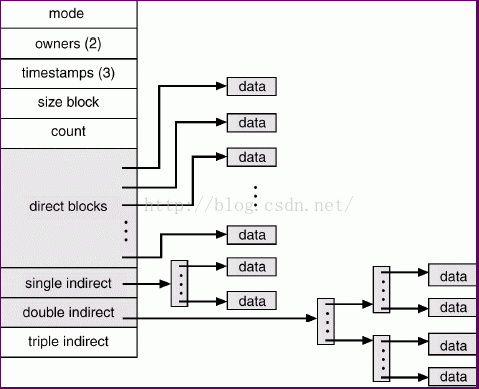
数据块寻址
inode中记录了文件数据块的位置,有三种寻址方式:direct blocks直接指向数据块;single indirect指向一个block,该block中为数据块的指针;double indirect,两级block
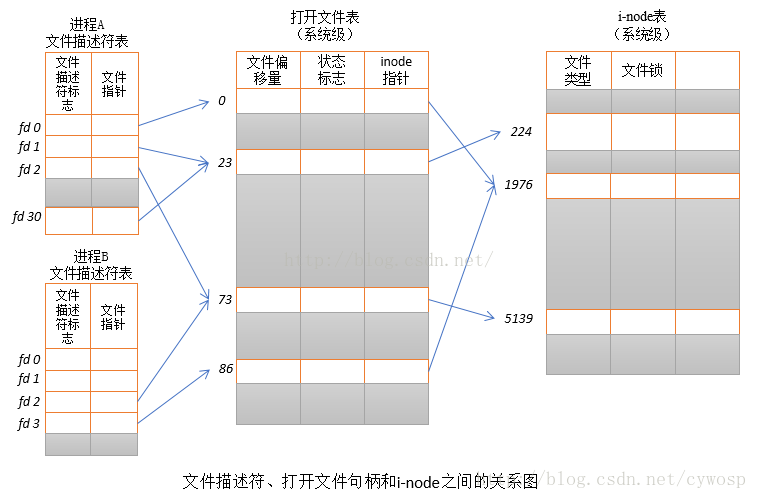
5.文件描述符
http://blog.csdn.net/cywosp/article/details/38965239
在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(file descriptor)是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。程序刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。如果此时去打开一个新的文件,它的文件描述符会是3。POSIX标准要求每次打开文件时(含socket)必须使用当前进程中最小可用的文件描述符号码
文件描述符是系统的一个重要资源,虽然说系统内存有多少就可以打开多少的文件描述符,但是在实际实现过程中内核是会做相应的处理的,一般最大打开文件数会是系统内存的10%(以KB来计算)(称之为系统级限制)