PyQuery库使用详解
目录
- 一、初始化
- 1.字符串初始化
- 2. URL初始化
- 3.文件初始化
- 二、基本CSS选择器
- 三、查找元素
- 查找子元素
- 查找父元素
- 祖先节点
- 兄弟元素
- 四、遍历
- 五、获取信息
- 获取属性
- 获取文本
- 获取HTML
- 六、DOM操作
- addClass、removeClass
- attr、css
- remove
- 其他DOM方法
PyQuery是python中一个强大而又灵活的网页解析库,如果你觉得正则写起来太麻烦,又觉得BeautifulSoup语法太难记,如果你熟悉jQuery的语法那么,PyQuery就是你绝佳的选择。
安装:pip3 install pyquery
一、初始化
下面介绍三种初始化PyQuery的方法。
1.字符串初始化
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq#习惯写法,用字母pq来代替PyQuery类
doc = pq(html)#声明PyQuery对象doc,传入html这个参数(字符串)
print(doc('li'))#用css选择器来实现,如果要选id前面加#,如果选class,前面加.,如果选标签名,什么也不加

如图,所以li标签内容被选择,并将内容打印出来。
2. URL初始化
from pyquery import PyQuery as pq
doc=pq(url='http://www.baidu.com')#直接请求传入的url
print(doc('head'))

选择出了head标签。
3.文件初始化
from pyquery import PyQuery as pq
doc=pq(filename='demo.html')#指定文件名,该文件在运行目录下
print(doc('head'))
二、基本CSS选择器
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))
#会查找id为container class为list,标签为li的对象,只是层级关系,后者并非一定是前者的子对象
#注意用空格隔开

三、查找元素
查找子元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')#拿到items,里面选择了list类
print(type(items))
print(items)
lis = items.find('li')#利用find方法,查找items里面的li标签,得到的lis也可以继续调用find方法往下查找,层层剥离
print(type(lis))
print(lis)
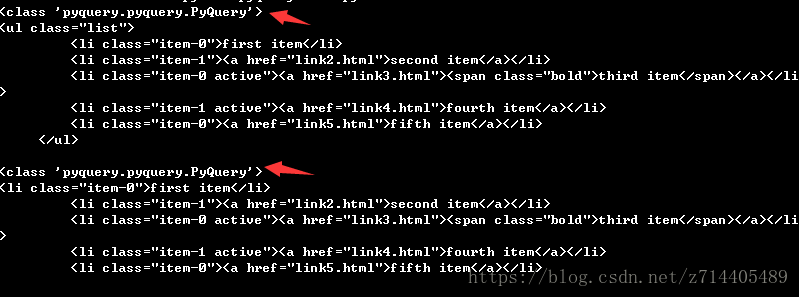
打印出来的内容如上图,上方的是list类中的所有内容,下方的是类中所有li标签的内容。
也可以用**.children()**查找直接子元素:
items = doc('.list')
lis = items.children()
print(type(lis))
print(lis)
lis = items.children('.active')
print(lis)
查找父元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
container = items.parent()#.parent()查找对象的父元素
print(type(container))
print(container)

list类的父节点是container,被全部打印出来了。
祖先节点
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
#parents = items.parents()#.parents()查找所有的祖先节点
parent = items.parents('.wrap')#可以传入参数,再次进行筛选
print(parent)
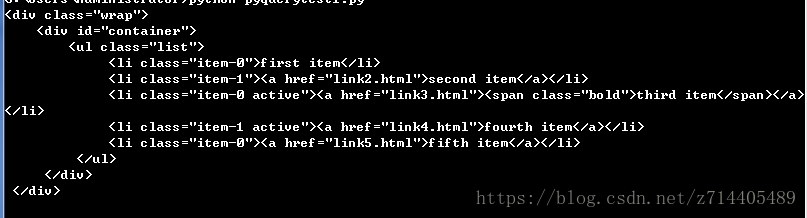
找出所有祖先节点中,类为wrap的节点。
兄弟元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
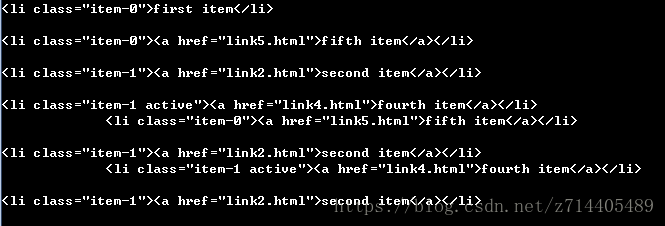
li = doc('.list .item-0.active')#空格表示下一层,没有空格表示并列
print(li.siblings())#.siblings()兄弟元素,即同级别的元素,不包括自己

如图,选出了4个兄弟元素。
当然啦,还可以从结果里再次进行筛选:
print(li.siblings('.active'))#
![]()
四、遍历
如果查找的结果有多个元素,并且你想对每一个都进行操作,那么就要用到遍历了。遍历的关键就是items。
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
lis = doc('li').items()#.items会是一个生成器,可以用来遍历
print(type(lis))
for li in lis:
print(li)
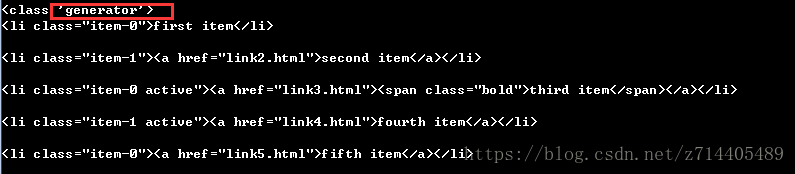
五、获取信息
获取属性
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')#选出同时具备这item-0,active两个信息的标签 空格表示这个标签内层的标签
print(a)
print(a.attr('href'))#a标签的href属性的内容,也就是一个超链接
print(a.attr.href)#另一种写法
![]()
获取文本
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')#选出同时具备这item-0,active两个信息的标签 空格表示这个标签内层的标签
print(a)
print(a.text())#获取该标签中的内容

获取HTML
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')#选中一个li标签
print(li)
print(li.html())#获得该标签中的html内容

六、DOM操作
对节点进行一些操作。这部分有许多的API,这里举一些例子。
addClass、removeClass
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')#删除active这个class属性
print(li)
li.addClass('active')#增加
print(li)

attr、css
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name','link')#如果不存在,就会向标签中添加一个内容为link的name属性,如果存在,那就改变之
print(li)
li.css('font-size','14px')#增加一个css
print(li)

remove
看下面的一段html,我们想要单独获得“Hello World”内容,但是和他并列的还有另外的内容,如果我们直接选中wrap标签然后.text,那么会获取两段内容。这时候可以先用remove方法把不需要的并列内容删除掉。
html = '''
Hello, World
This is a paragraph.
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()#找到p标签然后删除
print(wrap.text())
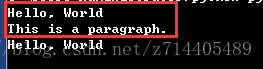
红框中的是删除之前的内容。删除之后就可以单独取得代码之祖:“Hello World”啦!
其他DOM方法
其他DOM方法
http://pyquery.readthedocs.io/en/latest/api.html
以上网址列出了所以的API,有需求时可查看。
#七、伪类选择器
根据自身需要(顺序之类的),选择指定的标签。
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:first-child')#选择li标签中的第一个
print(li)
li = doc('li:last-child')
print(li)
li = doc('li:nth-child(2)')#获取第2个li标签
print(li)
li = doc('li:gt(2)')#获取索引2个以后的li标签。注意!索引是从0开始的
print(li)
li = doc('li:nth-child(2n)')#获取第偶数个的li标签
print(li)
li = doc('li:contains(second)')#查找包含"second"文本的li标签
print(li)
更多CSS选择器可以查看 http://www.w3school.com.cn/css/index.asp
官方文档
http://pyquery.readthedocs.io/