Pandas玩转数据(七) -- Series和DataFrame去重
Python3数据科学汇总: https://blog.csdn.net/weixin_41793113/article/details/99707225
import numpy as np
import pandas as pd
from pandas import Series, DataFramels ..\homework##查看homework文件夹下的目录
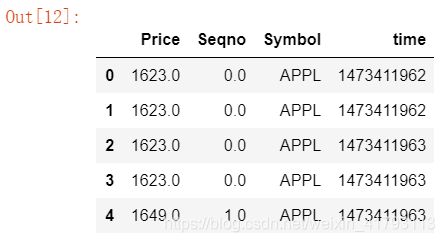
df = pd.read_csv('../homework/demo_duplicate.csv') ##读入csvdf.head() ##查看前5行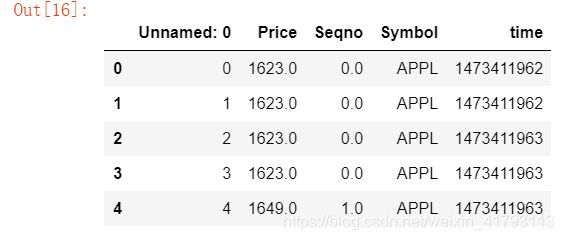
##'Unnamed: 0'属性并不是我们想要的,删了!!
del df['Unnamed: 0']df.size ##查看df的个数![]()
len(df)![]()
len(df['Seqno'].unique())![]()
df.head(8)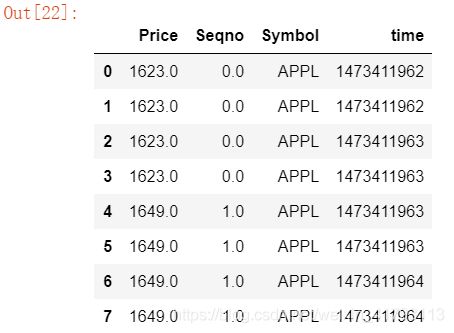
df['Seqno'].duplicated() ##查看重复值,准备对'Seqno'去重##返回布尔值 第一个出现的是False,后面出现重复的是True,如果我们想保留的是最后一个呢?

df.drop_duplicates(['Seqno'],keep='last') ##keep='last'保留最后一个出现的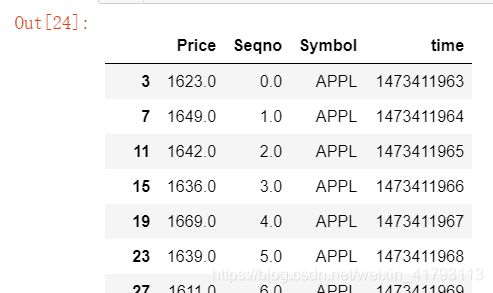
df.head() ##查看df可以发现,并没有影响原来的df