pandas字符串处理
1、pandas常用字符串处理函数
1.1字符串转大写upper
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.upper()1.2字符串转小写lower
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.lower()1.3字符串大小写转换 swapcase
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.swapcase()1.4字符串首字符大写 capitalize
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.capitalize()1.5字符串替换replace
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat'])
s.str.replace('_', '-')正则替换
s3 = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', '', np.nan, 'CABA', 'dog', 'cat'])
s3.str.replace('^.a|dog', 'XX-XX ', case=False)str.replace注意$符号,需要转义
dollars = pd.Series(['12', '-$10', '$10,000'])
dollars.str.replace('$','')dollars.str.replace('-\$', '-') 
1.6字符串拆分split
expand参数:将split拆分结果扩展成DataFrame
n:限制split拆分的个数
s2 = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'])
s2.str.split('_', expand=True)
s2.str.rsplit('_', expand=True, n=1)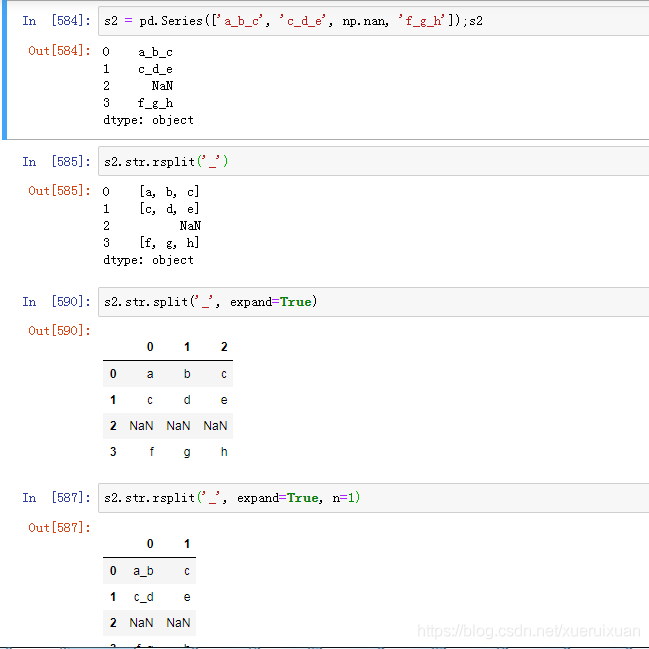
1.7字符串拼接cat
Series.str.cat(others=None, sep=None, na_rep=None)
Concatenate strings in the Series/Index with given separator.
Parameters others : list-like, or list of list-likes
If None, returns str concatenating strings of the Series
sep : string or None, default None
na_rep : string or None, default None
If None, NA in the series are ignored.
Returns concat : Series/Index of objects or str
df_work_order = pd.read_csv('D:/DMCC/20200724/work_order_per_day.csv', parse_dates=['stas_day'])
df_work_order['str_stas_day'] = df_work_order['stas_day'].dt.strftime('%Y-%m-%d')
#df_work_order['key_1'] = df_work_order['station_id'] + df_work_order['str_stas_day']
df_work_order['key_1'] = df_work_order['charge_station_id'].str.cat(df_worok_order['str_stas_day'], sep='-')na_rep如果不传,忽略NA
pd.Series(['a','b',np.nan,'c']).str.cat(['1','2','3','4'],sep='-', na_rep='?')
pandas拼接多列,others参数传入数组
df['key'] = df['org_str'].str.cat([df['str_stas_day'],df['id']], sep='-')