如何更有效使用Rational AppScan扫描大型网站
原文地址:http://www.2cto.com/Article/201207/141450.html
如何更有效使用Rational AppScan扫描大型网站(1)
-
简介: 本文针对大型网站的特点,结合 Rational AppScan 的工作原理,分析从扫描策略选择,扫描设置,任务分解等角度来如果更有效使用 Rational AppScan 进行应用安全扫描。“知己知彼,百战不殆”,在第一部分,首先我们一起来讨论分析 Rational AppScan 的工作原理和并分析大型网站的特点;在后续的第二部分将结合一个案例,看如何使用 Rational AppScan 来完成对大型网站的安全检查
Rational AppScan 工作原理
Rational AppScan(简称AppScan)其实是一个产品家族,包括众多的应用安全扫描产品,从开发阶段的源代码扫描的AppScan source edition,到针对Web 应用进行快速扫描的AppScan standard edition,以及进行安全管理和汇总整合的AppScan enterprise Edition 等。我们经常说的AppScan 就是指的桌面版本的AppScan,即AppScan standard edition。其安装在Windows 操作系统上,可以对网站等Web 应用进行自动化的应用安全扫描和测试。
来张AppScan 的截图,用图表说话,更明确。

图1. AppScan 标准版界面
请注意右上角,单击“扫描”下面的小三角,可以出现如下的三个选型“继续完全扫描”、“继续仅探索”、“继续仅测试”,有木有?什么意思?理解了这个地方,就理解了AppScan 的工作原理,我们慢慢展开:
还没有正式开始安全测试之前,所以先不管“继续”,直接来讨论“完全扫描”,“仅探索”,“仅测试”三个名词:
AppScan 三个核心要素
AppScan 是对网站等Web 应用进行安全攻击来检查网站是否存在安全漏洞;既然是攻击,需要有明确的攻击对象吧,比如北约现在的对象就是卡扎菲上校还有他的军队。对网站来说,一个网站存在的页面,可能成千上万。每个页面也都可能存在多个字段(参数),比如一个登陆界面,至少要输入用户名和密码吧,这就是一个页面存在两个字段,你提交了用户名密码等登陆信息,网站总要有地方接受并且检查是否正确吧,这就可能存在一个新的检查页面。这里的每个页面的每个参数都可能存在安全漏洞,所有都是被攻击对象,都需要来检查。
这就存在一个问题,我们来负责来检查一个网站的安全性,这个网站有多少个页面,有多少个参数,页面之间如何跳转,我们可能并不明确,如何知道这些信息?看起来很复杂,盘根错节;那就更需要找到那个线索,提纲挈领;想一想,访问一个网站的时候,我们需要知道的最重要的信息是哪个?网站主页地址吧?从网站地址开始,很多其他频道,其他页面都可以链接过去,对不对,那么可不可以有种技术,告诉了它网站的入口地址,然后它“顺藤摸瓜”,找出其他的网页和页面参数?OK,这就是“爬虫”技术,具体说,是“网站爬虫”,其利用了网页的请求都是用http 协议发送的,发送和返回的内容都是统一的语言HTML,那么对HTML 语言进行分析,找到里面的参数和链接,纪录并继续发送之,最终,找到了这个网站的众多的页面和目录。这个能力AppScan 就提供了,这里的术语叫“探索”,explorer,就是去发现,去分析,了解未知的,并记录之。
在使用AppScan 的时候,要配置的第一个就是要检查的网站的地址,配置了以后,AppScan 就会利用“探索”技术去发现这个网站存在多少个目录,多少个页面,页面中有哪些参数等,简单说,了解了你的网站的结构。
“探索”了解了,测试的目标和范围就大致确定了,然后呢,利用“军火库”,发送导弹,进行安全攻击,这个过程就是“测试”;针对发现的每个页面的每个参数,进行安全检查,检查的弹药就来自AppScan 的扫描规则库,其类似杀毒软件的病毒库,具体可以检查的安全攻击类型都在里面做好了,我们去使用即可。
那么什么是“完全测试呢”,完全测试就是把上面的两个步骤整合起来,“探索”+“测试”;在安全测试过程中,可以先只进行探索,不进行测试,目的是了解被测的网站结构,评估范围;然后选择“继续仅测试”,只对前面探索过的页面进行测试,不对新发现的页面进行测试。“完全测试”就是把两个步骤结合在一起,一边探索,一边测试。
AppScan 工作原理小结如下:
通过搜索(爬行)发现整个Web 应用结构
根据分析,发送修改的HTTP Request 进行攻击尝试(扫描规则库)
通过对于Respone 的分析验证是否存在安全漏洞
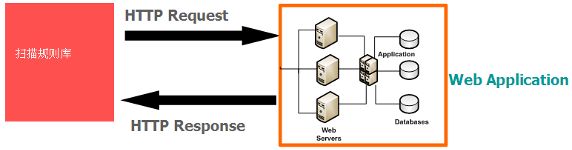
图2. AppScan 扫描原理:扫描规则库+ 爬行+ 测试
步骤1:探索(又叫爬行,爬网)
图3. 探索(爬网,爬行)

步骤2:测试(针对找到的页面,生成测试,进行安全攻击)

图4. 针对探索发现的页面和参数,进行安全测试
所以,简言之,AppScan 的核心是提供一个扫描规则库,然后利用自动化的“探索”技术得到众多的页面和页面参数,进而对这些页面和页面参数进行安全性测试。“扫描规则库”,“探索”,“测试”就构成了AppScan 的核心三要素。而在安全扫描过程中,如何进行优化,就要结合这三个要素,看哪些部分需要优化,应该如何优化。
AppScan 结果文件
同时,对于AppScan 标准版来说,扫描的配置和结果信息都保存为后缀名为Scan 文件,Scan 文件里面主要包括的内容如下:
扫描配置信息:扫描配置信息,如扫描的目标网站地址,录制的登陆过程脚本等,选择的扫描设置等都保存在Scan 文件中。
所有访问到页面信息:针对每个发现的页面,即使没有进行测试,在探索过程也会访问该页面并纪录http request/response 信息;所以如果探索的页面访问的时候返回的页面内容比较多,页面比较大,那么即使只做了探索根本没有扫描,整个Scan 文件也会很大。
测试阶段,记录测试成功的测试变体和页面访问信息:针对每个页面都会发送多次测试(测试变体),每次测试都会有Request/response 信息,这些信息如果测试通过,即发现了一个安全问题,则会把该测试变体对应得request/response 都会纪录下来,保存在.scan 文件中;由于AppScan 的扫描测试用例库全面,对于每种安全威胁漏洞,都会发送多个安全测试变体(Variant)进行测试,比如对于XSS 问题,AppScan 发送了100 个变体,其中30 个执行失败,70 个变体执行成功,则会纪录 70 次执行成功的具体变体信息,以及每个变体对应的Request/Response 信息。这就是一个很大的数据量。这些信息保存以后,就可以在不连接在网站的情况下进行结果分析,快速显示当时测试的页面快照等。
我们以http://demo.testfire.net/bank/customize.aspx 为例,如下就有74 个变体都发现了Customize 页面的Lang 参数存在跨站点脚本执行(XSS)类型的安全漏洞:
图5. 测试变体显示
所以针对AppScan 标准版来说,由于需要保存的信息比较多,结果文件是会比较大的,最根本的方法还是有针对性地进行扫描和测试,使用排除页面等排除冗余页面,把一个大的系统分解为多个小的扫描任务等。
好的,了解了AppScan 的原理,我们就结合原来讨论下为什么扫描大型网站时候可能遇到问题了。
回页首
大型网站技术特点分析
AppScan 扫描的对象是网站等Web 应用,而网站规模的大小和使用的技术,都需要针对性的进行扫描设置,我们遇到的很多问题,都是在扫描规模比较大的网站时候遇到的,如一个网站页面数目超过2000 个,需要执行的扫描用例是50,000 个,在扫描这样的网站时候,默认情况下AppScan 的扫描scan 文件可能超过100M 了,扫描效率就可能比较慢,需要长时间的扫描运行时间。
下面,我们就来分析大型网站中存在的一些可能影响AppScan 扫描的技术特点。
网站页面多,页面参数多,则AppScan 需要发送的测试用例多
什么叫大型网站,顾名思义,网站规模大,提供内容多;具体说是页面很多,内容很全。比如www.sina.com.cn,比如http://music.10086.cn/,网站中都有多个频道,包括上万个页面。而且除了页面多,可能还有一个特点--- 页面参数多,即要填写的地方多,和用户的交互多;比如一个网站如果都是静态页面(.html、.jpg 等),没有让用户输入的地方,那么可以利用,可以作为攻击点的地方也就不多。如果页面到处都是有输入有查询,要求用户来参与的,你输入的越多,可能泄露的信息也越多,可能被别人利用的攻击点也就越多,所以和页面参数也是有关系的。
AppScan 产生测试用例的时候,也是根据每个参数来产生的,简单说,如果一个参数,对应了200 个安全攻击测试用例,那么一个登陆界面至少就对应400 个了,为什么?登陆界面至少有用户名(username)和密码(password)两个字段吧?每个字段200 个攻击用例。
这个简单吧,还可以更复杂:如果遇到下面的两个地址,那要扫描多少次呢?
http://www.Test.com/focus/satisfy/file.jsp?id=1
http://www.Test.com/focus/satisfy/file.jsp?id=2
上面的两个地址有类似的,“?”号以前的URL 地址完全一样,“?”号后面带的参数不同,这种可以认为是重复页面,那么对于重复页面,是否要重复测试呢?
这取决于“冗余路径设置”,默认的是最多测试5 次;即,这种类型URL 出现的前5 次,那么就是要测试1000 个攻击用例了。
如果再继续修改下:遇到下面的URL 呢
http://www.2cto.com /focus/satisfy/file.jsp?id=&Item=open
http://www.Test.com/focus/satisfy/file.jsp?id=2&Item=close
每个URL 里面都有2 个参数,测试的次数就更多了。想象下,如果这个网页里面的参数如果是10 个,或者更多的呢?比如很多网站提交注册信息的时候,要填写的栏位就很多,要进行的安全测试用例也就随之不断增加…
这是网站规模的影响,还有一个问题,就出在“每个参数,发送200 个安全测试用例”这个假设上。这个假设的前提来源于哪里?来源于我们选择的扫描规则库。即你关心那些安全威胁,这个需要在测试策略里面选择。同样来参照杀毒软件,你会用杀毒软件来查找一些专用的病毒吗,比如CIH、木马;应用安全扫描也是一样的道理,如果有明确的安全指标或者安全规则范围,那么就选择之。这些可能来源于企业的规范,来源于政府的法律法规。就要根据你的理解,在这里选择。
图6. 选择测试策略
在实际工作中,我们也很难在最开始的阶段,就把扫描规范制定下来,按照项目经理们的口头禅“渐进明细”,“滚动式规划”,在实践中,更多时候也是摸着石头过河,选择了一个扫描策略,然后根据结果分析,看是否需要调整,不断优化。比如选择默认的“缺省值”扫描策略,对网站进行扫描,发现其“敏感信息”里面会去检查页面上是否含有Email 地址,是否含有信用卡号码等,如果我们觉得这些信息,显示在页面上是正常的业务需要(比如这样的链接:有问题请联系[email protected]),我们就可以取消掉这些规则,所以扫描规则也很大程度上影响着我们的扫描效率。
网站采用多种混合的技术,需要不同的扫描设置
一些大型网站,往往是一个统一的入口,在里面提供不同的内容,而这些内容可能来源于不同的技术。如我们熟悉的门户网站,里面就有“财经”、“体育”、“娱乐”等多个频道;每个频道的内容,可能是采用不同的技术,对应不同的服务器。如一个网站的“ 论坛”频道,就有很多类似的页面:
http://www.Test.com/bbs/showthread. php?id=1
Http://www.Test.com/bbs/showthread.php?id=2
Http://www.Test.com/bbs/showthread.php?id=3
这里的showthread.php 页面存在多次,每次都是参数值不同,访问后发现这些页面除了文本内容外,其他的页面结构等都相同,则这些页面只需要选择几个典型的扫描即可,没有必要全部扫描。
而同时,在另外的一些频道,存在另外类型的页面:
http://www.Test.com/default. aspx?content=inside_community.htm
http://www.Test.com/default.aspx?content=inside_press.htm
http://www.Test.com/default.aspx?content=inside_executives.htm
这些动态页面,也是网址相同,参数相同,但是具有不同的参数值,访问时候发现每种类型的参数值都指向了完全不同的页面,则需要每种参数值都要测试到。这种情况经常存在跳转页面中。
而这两个频道中,第一种情况,可以选择典型的页面扫描之,而第二种情况则需要进行完全的扫描,每种参数值都需要考虑到。这就需要不同的扫描设置。
同时,可能大家也注意到了,第一种情况下的是php 页面,而第二种情况下的则是aspx 页面,对应不同的开发技术,这也可能需要不同的扫描设置。
所以,总结下,AppScan 的扫描受到如下因素的影响:
网站规模(页面个数,页面参数)
扫描策略的选择
扫描设置
而对于大型的网站,我们经常需要从几个方面来优化配置
选择合适的,最小化的扫描规则
分解扫描任务,把一个大的扫描任务分解为多个小的扫描任务
根据页面特点,设置可以过滤的类似页面(冗余页面)
回页首
接下来
工欲善其事,必先利其器,选择了AppScan 这个专业的Web 应用安全测试工具,那么接下来的第二部分,我们结合一个例子,来讨论么可以更好的优化设置,把工具充分利用起来。
如何更有效使用Rational AppScan扫描大型网站(2)
本文针对大型网站的特点,结合 Rational AppScan 的工作原理,分析从扫描策略选择,扫描设置,任务分解等角度来如果更有效使用 Rational AppScan 进行应用安全扫描。“知己知彼,百战不殆”,在第一部分中,已经讨论分析了 Rational AppScan 的工作原理和并分析大型网站的特点;在第二部分中将结合一个案例,看如何使用 Rational AppScan 来完成对大型网站的安全检查。
使用AppScan 进行扫描
针对大型网站的扫描,我们按照戴明环PDCA 的方法论来进行规划和讨论,建议AppScan 使用步骤:计划(Plan)、执行(Do)、检查(check)、分析(Analysis and Action)。
在计划阶段:明确目的,进行策略性的选择和任务分解。
明确目的:选择合适的扫描策略
了解对象:首先进行探索,了解网站结构和规模
确定策略:进行对应的配置
按照目录进行扫描任务的分解
按照扫描策略进行扫描任务的分解
执行阶段:一边扫描一遍观察
进行扫描
先爬后扫(继续仅测试)
检查阶段(Check)
检查和调整配置
结果分析(Analysis)
对比结果
汇总结果(整合和过滤)
下面我们针对每个阶段,进行具体的阐述。
回页首
准备阶段
AppScan 安装环境要求和检查
为了保证更好的扫描效果,安装AppScan 的硬件建议配置如下:
表1. Rational AppScan 安装配置要求
硬件 最低需求
处理器 Pentium P4,2.4 GHz
内存 2 GB RAM
磁盘空间 30 GB
网络 1 NIC 100 Mbps(具有已配置的TCP/IP 的网络通信)
其中,处理器和内存建议越大越好,而磁盘空间,建议系统盘(一般是C 盘)磁盘空间至少保留10G,如果系统盘磁盘空间比较少,可以考虑把用户文件等保存在其他盘;如默认的用户文件是:C:\Documents and Settings\Administrator\My Documents\AppScan;可以修改为其他路径。该路径可以在菜单栏中依次选择工具- 选项- 一般- 文件位置部分修改。
图1. 设置文件保存路径
磁盘要求:修改临时文件路径
有时候大家会发现,已经把上面的地址都修改到了其他盘,但是在扫描过程中,还是会发现C 盘的空间快速被消耗,分析原因,是因为很多临时文件都保存在C 盘,AppScan 中有一个隐藏的参数APPSCAN_TEMP 来设置临时文件位置。在扫描过程中,如果系统盘空间比较下,可以通过修改系统变量来修改到其他硬盘空间。
临时文件位置说明:描述正常操作期间AppScan 将其临时文件保存到的位置。缺省情况下,AppScan 将其临时文件存储在以下位置:
C:\Documents and Settings\All Users\Application Data\IBM\Rational AppScan\temp
如果需要修改此缺省位置,请按照要求编辑环境变量APPSCAN_TEMP 的路径。(访问环境变量的方法是,右键单击我的电脑,然后依次选择属性> 高级> 环境变量。)
注意:在新位置的路径中绝不能有任何Unicode 字符。
修改AppScan 中的临时文件:
桌面上鼠标右键选择“我的电脑”,选择“属性”
选择“高级”,“环境变量”
增加一个新的“用户环境变量”,名字是“APPSCAN_TEMP”,设定路径,指向您希望保存临时文件的目录。
回页首
计划阶段
在计划阶段,首先明确几个问题:
关心哪些类型的安全问题,根据这些安全问题来设置扫描规则。
要扫描的网站地址,网站的业务特点。
扫描策略的选择
试想,我们现在要扫描的是某个移动公司的网站系统,该网站系统提供多个内容频道,还可以连接到多个其他移动公司网站和业务网站,我们本次安全测试重点关心的是门户网站本身和其上面的网上营业厅业务。这就是一个比较明确的测试目标对象。
然后,确定扫描策略,我们主要关心该网站是否存在跨站点脚本执行和SQL 注入的问题,则在扫描规则中,我们就可以选择这两种类型的规则,其他规则都排除。
具体的扫描规则定制,可以在扫描配置- 测试- 测试策略中选择:
在测试策略中,有多种不同的分组模式,最经常使用的是“严重性”,“类型”,“侵入式”、“WASC 威胁分类”等标准,根据不同分组选择的扫描策略,最后组成一个共同的策略集合。
根据我们这次扫描的目标,关心的是跨站点脚本执行和SQL 注入的问题,而且不考虑“基础结构”级别的安全问题。则就可以首先选择一个默认的扫描策略,然后全部置空,再选择
跨站点脚本执行和SQL 注入,最后再去除这两种扫描策略中和基础结果相关的安全问题。
方法如下:
选择缺省的扫描策略,或者把当前的扫描策略,切换到按照“类型”分类,取消掉“基础结构”和“应用程序”两种类型。
说明:则把扫描策略置空,没有选择任何的扫描策略,指所有分布类型选择“类型”分类,是因为类型分类里面含有的类型,只有两种类型,可以快速全部都取消掉。
分组类型,切换到“WASC 威胁分类”,选择“SQL 注入”和“跨站点脚本编制”。
分组类型,切换到“类型”,发现这时候“基础结构”和“应用程序”两种类型的扫描策略都是选择上的模式,而且是虚线,说明这两种类型下均有部分扫描策略被选择了。
我们不关心“基础结构”级别的安全问题,所以在这里取消“基础结构”。
图2. 按“类型”分类的测试策略
分组类型,切换到“侵入式”类型,下面有“非侵入式”和“侵入式”两种分类。取消“基础结构”级别的测试。
侵入式的测试用例,往往因为有比较强的副作用,可能对系统造成伤害,所以一般扫描生产系统的时候,很少选择。我们可以查看一个SQL 注入类型的侵入式安全问题,在“输入以查找”输入框中输入“SQL”,然后回车查询。可以看到测试变体的描述“将参数值设置为Declare/Case SQL 注入攻击(尝试关闭DB 服务器)”,则扫描过程中,会使用该测试用例去执行尝试关闭数据库的命令,如果该测试用例执行通过,则就关闭了数据库,则整个系统就瘫痪!所以,要很慎重的选择“侵入式的测试用例”。
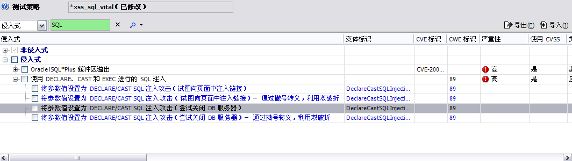
图3. 查询测试策略
其他的在“类型”中,“应用程序”类型表示该问题的存在是因为应用程序不严谨,代码存在安全问题而造成的,修改方法就是修改原代码;而“基础结构”类型,则表示该问题是配置问题,建议修改系统配置或者安装最新的补丁(经常是中间件或数据库补丁)。
了解被测试网站
在对网站进行测试之前,我们经常需要先大概了解下这个网站,比如该网站使用了哪些技术,提供什么类型的业务(功能),网站规模等。这些都和我们的扫描设置相关。如下图,就是我们经常使用的一个调查表,了解被测试系统的基本特点。
表2. 记录被测网站特点
应用系统名称 访问地址 应用系统架构(JEE/.Net/PHP…) URL 数量 登陆方式 备注
其中,用户经常迷惑的是URL 数量,有些时候,用户很难评估出一个系统的大概页面数量,而按照AppScan 的工作原理,扫描是针对页面的每个参数的,如果页面越多,参数越多,则扫描要运行的时间也就越长,扫描保存成的接过文件也是越大,更需要进行分解。如果一个扫描任务,本身的已访问URL 数超过5000,评估的要运行的安全测试用例数超过50,000,则建议进行扫描配置的分析,并根据分析结果,决定是否需要进一步的任务分解和分工。
那么,如果可以了解到网站具体有哪些页面呢?这里我们就可以利用AppScan 的探索(页面爬行)能力。
在扫描配置里面设置了主URL 以后,工作菜单中中依次选择扫描- 仅探索。对网站进行探索。一般会让探索工具运行10 到30 分钟,看该网站具体存在哪些页面,哪些参数等。这个就可以切换到“应用程序数据”视图来查看。
我们一般关心这几个视图:
已访问的URL():AppScan 已经探索到并且进行了分析的页面
已过滤掉的URL():AppScan 已经发现,同时根据扫描配置,认为不需要进行安全扫描的页面。
中断链接URL():AppScan 发现了,但是无法访问到或者访问出错的页面,如404 页面不存在,或者500 服务器错误等。
伪静态页面
可以选择左边“我的应用程序数据”中的URL 树下的每一个节点,察看该节点已访问的URL,已过滤掉的URL 等。
如在已访问的URL() 中,我们发现大量类似如下结构的HTML 页面:
http://www.Test.com//focus/satisfy/file5.html
http://www.Test.com//focus/satisfy/file6.html
http://www.Test.com/m-zone/news/dgdd/quanbu/bylb/file5.html
其共同特征,都是以html 为后缀名,最后的文件名格式都是file+ 数字格式;这种类型的页面经常存在新闻,论坛等。如果访问这些页面,发现页面结构相同,差异的都是里面的文本内容,如提供不同的新闻内容等,这些页面就是所谓的“伪静态页面”,其实是网站发布系统动态产生的,由于结果相似,在安全扫描中,没有必要针对这些页面每次都进行扫描。如针对每个目录下面存在的file+ 数字格式的页面,我们就可以设置正则表达式来过滤,比如,在扫描配置- 排除路径和文件中
排除所有该类型的页面;.*file\d+.html
增加“例外”,对该类型的页面只扫描file1.html 和file20.html
经常存在的其他类似页面,还有news1.html、content200.html 等类型,采用方法类似。
业务类型的“冗余路径”
和“伪静态页面”对应的有另外一种动态页面,这些页面按照默认的扫描规则,会被自动过滤,但是根据真实的业务场景,这些页面确实不能被过滤的,如访问demo.testfire.net 时候在“已过滤URL”内会显示有如下的URL 地址,过滤原因都是“路径限制”:
http://www.Test.com/default.aspx?content=inside_community.htm
http://www.Test.com/default.aspx?content=inside_press.htm
http://www.Test.com/default.aspx?content=inside_executives.htm
选择URL 地址,鼠标右键“在浏览器中显示”,会发现这里显示的页面内容完全不一样,和上面的“伪静态页面”正好相反,这些参数相同,参数值不同的动态页面,是真正的业务页面,是不能过滤掉;如果过滤,则会很多后续的业务页面无法发现。那这些页面为什么会被过滤了呢?按照什么样的规则被过滤掉的?
在AppScan 中,默认情况下是有一个“冗余路径限制”(在“扫描配置- 探索选型- 冗余路径限制”),默认对于冗余的页面,最多扫描5 次,关键的问题是,什么页面被被Appscan 认为是冗余页面呢?

图4. 冗余路径设置
简单说:
http://www.Test.com/default.aspx?content=inside_community.htm
http://www.Test.com/default.aspx?content=inside_press.htm
Appscan 是根据“?”号来分隔的,如果? 号前面的内容都相同,则就被认为是冗余页面,所以上面的页面就是冗余页面了。
遇到这样情况的页面,最多被访问5 次。而这5 次,具体是使用了哪些参数,是随机的,具体访问到的页面也会在“应用程序数据”视图的“已访问的URL”中查看:
http://www.Test.com/default.aspx?content=business.htm
http://www.Test.com/default.aspx?content=business_lending.htm
http://www.Test.com/default.aspx?content=inside_contact.htm
可是,在本例中content 参数值不同的时候,其实根据业务逻辑,不应该算作“冗余页面的”,而按照配置,也会被自动过滤了,遇到这种情况,就需要考虑增加“冗余路径限制”,如设置为20 或者50。以可以更多次访问这些页面。
这些情况经常存在于跳转参数等情况。
顺便备注下,“冗余路径限制”,功能设置的目的是为了处理类似论坛BBS 等页面,只有文本内容不同,页面架构完全相同的页面:如
http://www.Test.com/showthread.php?id=1
http://www.Test.com/showthread.php?id=2
http://www.Test.com/showthread.php?id=3
而我们在测试demo.testfire.net 时候会发现每次的安全测试结果都可能有差别,一个很大的原因就是每次访问的页面是不同的,就是这个设置的影响。
分析重复的“脚本参数”
在上面的步骤中,分析了“伪静态页面”,对其应该通过“排除路径或者文件名”的方法设置排除规则;而对于“业务类型的冗余路径”,则需要通过增加“冗余路径显示”个数等的方法进行扩充,以扫描到这些URL。我们在这个步骤来分析另外一种参数,脚本参数。
在“我的应用程序数据”树状结构下,鼠标选择目录以后,在右边视图中选择“脚本参数”,然后查看是否存在不同页面(URL) 存在相同或者类似参数的情况:如下图,在不同URL 中,都存在kbKey 参数,默认的参数值是“请输入您要搜索的问题”:

图5. 脚本参数
访问这些URL,发现每个页面内都包含了一个搜索功能,这就是为什么在不同页面都发现了该参数。而从业务角度,这些搜索页面在一个URL 中进行测试以后,没有必要在另外一个页面也进行测试。而且该参数值的变化,可以认为是冗余页面,没有必要进行下一步的重新探索和测试。这可以通过上图中,选择该参数后,鼠标右键,选择“添加到‘参数和Cookie’选项卡中的列表”来实现。选择后弹出下面的页面:
图表6 添加参数定义(根据参数来设置冗余路径)
图6 大图
在该页面中,点击“其他选项-冗余调整”,取消选择任何一个选择框,则表示无论是否含有该参数,无论该参数值是否发生变化,都不认为是新页面,没有必要重新测试,而且不应该因为该参数的变化去影响其他参数的测试。
我们知道,AppScan 中的测试,是针对页面的每个参数进行的,而且一个参数值的变化会要求重新测试其他的参数,所以该设置,可以大大减少测试用例数。
关于更多的设置说明,可以参照下面的解释:
表3. 设置说明

查看每个目录页面个数
如果一个扫描任务,本身的已访问URL 数超过5000,评估的要运行的安全测试用例数超过20,000,则建议进行扫描配置的分析,并根据分析结果,决定是否需要进一步的任务分解和分工。
我们在“我的应用程序数据”树状结构下,鼠标选择目录以后,在右边视图中选择“已访问的URL()”,记录URL 数目,如果该目录URL 数目比较大(超过500)则可以考虑为该目录单独建立一个扫描任务,只扫描该目录下面的链接。
回页首
执行阶段
根据在“计划阶段”确定的扫描策略,和进行的扫描设置,重新进行探索(扫描菜单依次选择:重新扫描- 重新探索);后继续分析页面数和测试用例数目,如果控制页面数5000 个以内,测试用例数20,000 个以内,则可以直接进行扫描;如果没有,建议继续分析,优化扫描配置。
分阶段测试
AppScan 的扫描过程分为“探索”和“测试”两个阶段,默认情况下,使用的是完全扫描模式,即是边探索边测试的。如果网站比较大,建议考虑先探索后测试的模式。
如当URL 达到5000,需要进行的测试达到50000 的时候,可以暂停扫描,手工停止探索,选择“继续仅测试”。对已经发现和分析的页面进行测试,测试完毕,再来选择“继续仅探索”,即:
继续仅探索--- 继续仅测试—继续仅探索- 仅测试的一个循环过程。
在这个过程,一个阶段结束以后,建议查看下.Scan 文件的大小,如果大小超过了500M,则建议考虑任务分解,可以根据目录把一个扫描任务分解为多个,或者根据扫描策略来进行分解。
该方法是利用了AppScan 扫描过程中,探索测试可以分离,而且支持扫描过程中断后继续扫描的特性。
按照业务分解扫描任务
在实际工作中,我们扫描的一个大型网站,往往包含多个频道,而每个频道可能需要的扫描配置都不同,这些配置甚至互相冲突。如一个网站的提供了BBS 论坛功能:
http://www.Test.com/WWW.TEST.COM/showthread?channel=1&thread=1001
http://www.Test.com/WWW.TEST.COM/showthread?channel=30&thread=2001
对于这样的页面,访问后发现页面结构相同,只是文本内容不同,则应该使用“冗余路径限制”参数,控制扫描次数,没有必要多次扫描。
同时,该网站的一个服务频道存在如下的页面:
http://www.Test.com/default.aspx?content=inside_executives.htm
http://www.Test.com/default.aspx?content=privacy.htm
即上面提到的业务类型的“冗余路径”,应该多次扫描,配置上要求增大“冗余路径限制”参数。
在这种情况下,就很有必要根据业务分别建立扫描任务,每个任务采用不同的扫描配置。
回页首
检查阶段
在扫描执行过程中,需要检查,看是否存在下面的情况:
提示网络连接不上,或者提示部分页面无法打开。则检查是否是扫描速度过快,服务器不能承受不了,根据情况修改扫描配置- 连接- 通信和代理,增加“超时”数,并考虑减少“并发线程数”,以允许更长时间的等待页面影响并减少对服务器的访问连接数。
发现扫描出的安全问题,包含我们不关心的安全隐患,则取消掉这些规则。如发现了一个安全隐患,类型是“SQL 注入文件写入(需要用户验证)”,该问题是需要用户根据提示来检查的,并且是针对SQL 数据库的,如果我们使用的数据库不是SQL 数据库,或用户确认后没有发现线索,则就可以在扫描配置- 测试- 测试策略中取消选择该策略。
执行“计划阶段”的检查,看是否还存在“伪静态页面”,“业务类型的冗余路径”等,如果存在,则调整扫描配置。
回页首
分析阶段
在分析阶段,结合业务特点,检查是否扫描范围,分析扫描结果,并针对扫描出来的问题,进行分析,产生多种类型的报告等。
扫描结果检查
扫描结束后,建议切换到“应用程序数据”视图中,对页面进行分析,检查是否核心页面都被测试到了。重点检查如下部分:
交互式URL:一些页面,必须输入正确的信息,才可以跳转到下一个页面,比如查询手机欠费的页面,必须输入正确的11 位手机号码;查询身份信息的页面,必须输入18 位的身份证号才可以进入后续页面。如果没有配置,AppScan 怎么知道输入这些信息?所以如果存在“交互式”URL,可以选择该URL 以后,鼠标右键,选择手动探索,在AppScan 浏览器中访问这些页面,输入对应的数据,则AppScan 会自动记录这些输入,并填充到扫描配置- 自动表单填充中。
中断链接:看哪些页面在扫描过程中,访问出错或者无法访问,如针对time out 的页面,就可能是因为网络原因,扫描过程中没有及时响应,可以选择“重试所有中断链接”重新进行访问。
报告分析
我们需要对报告进行对比分析或者报告汇总合并,方法如下:
增量分析:在实际工作中,经常对一个网站进行定期扫描,那么我们可以使用报告对比功能,对比两次产生的结果,检查哪些问题已经修改,哪些是新发现的安全隐患。方法是选择报告- 增量分析。
报告汇总和合并:而如果我们在执行阶段,按照业务或者目录进行了分解,最后可能需要对多份扫描结果进行合并和汇总,合并过程中重复的问题只记录一次,如扫描任务A 和任务B 都发现了apply.jsp 的ID 参数存在XSS 安全隐患,则合并后只记录一次。报告的合并需要使用到AppScan 企业版,其具有AppScan 标准版的扫描功能和强大的报告汇总功能,可以产生仪表盘,报告的对比分析,趋势分析等。可以把AppScan 标准版的报告发布到AppScan 企业版中,方法是菜单栏中依次选择文件- 导出- 将结果发布到AppScan Enterprise。

图7. AppScan 标准版的扫描结果发布到企业版
回页首
案例分析
工作中遇到一个案例,使用AppScan 扫描扫描了3*24 小时,扫描的scan 文件已经达到9G;扫描还在持续进行中,总体进度完成了30%,可以想象扫描速度已经很缓慢,还需要多长时间才可以完成扫描?扫描完成以后如此大的结果文件是否可以成功打开和修改保存?
按照我的经验,如果扫描结果文件大于1G,那就很有必要立即停止扫描,进行配置分析。我们的分析过程如下:
和用户讨论,确认关心的安全问题,根据这些安全问题制定测试策略;讨论后确定选择“SQL 注入”和“跨站点脚本编制”两种类型的安全隐患。
确定网站范围,被扫描应用是典型运营商门户网站,重点要扫描门户网站自身和其上面提供的“网上营业厅”服务。
分析被测网站,使用AppScan 配置了网站主页面,然后选择“仅探索”运行20 分钟后,发现30,000 多个页面。停止探索,开始分析页面。
分析发现该网站同一个链接,存在http、https 访问的不同情况,而且两种访问方式访问到的页面内容相同,则过滤掉https 的请求,集中测试http 请求。
分析发现存在大量的“伪静态页面”,如:
http://www.Test.com//focus/satisfy/file5.html
http://www.Test.com//focus/satisfy/file6.html
在扫描配置- 排除路径和文件中:
排除所有该类型的页面;.*file\d+.html
增加“例外”,对该类型的页面只扫描file1.html 和file20.html
同时,发现了swf 文件,应该不准备扫描Flash,所以在“排除文件类型”中,设置根据后缀名排除swf 文件。
发现
http://www.Test.com/service
目录下存在大量如下类型的页面,都是menu 参数值不同,访问以后发现出现的是页面中有不同的超链接:
http://www.Test.com/service/Business.do?menu=Query
http://www.Test.com/service/Business.do?menu=Open
http://www.Test.com/service/Business.do?menu=Service
确认该页面是业务类型的“冗余路径”,应该全面扫描,则需要把“冗余路径设置”调整为比较大的参数,同时该频道是网上营业厅频道,也要求用户先登录。所以针对该目录建立一个单独的扫描任务,只扫描该目录和其下子目录。
分析发现index.jsp 在多个目录下出现,而且每次出现都有两种格式,即没有参数和有固定的三个参数,每次的参数值都相同。如:
http://www.Test.com//rdwd/jfmz/jifen/index.html
http://www.Test.com//rdwd/jfmz/jifen/index.html?queryType=common&applyArea=010
&kbKey= 请输入您要搜索的问题
http://www.Test.com//rdwd/txl/rdwdznyd/index.html
http://www.Test.com//rdwd/txl/rdwdznyd/index.html?queryType=common&applyArea=010
&kbKey= 请输入您要搜索的问题
访问上面的页面,发现内容相同,则说明是否带这三个参数不会影响探索发现更多的页面,则可以设置这三个参数每次是否出现,是否有不同值都可以认为是同一个页面。
设置方法:扫描配置中依次选择“参数和Cookie”来实现。然后增加queryType,applyArea,kbKey 三个参数,均设置为“是否有参数”、“参数是否变化”不影响测试的模式。
切换到“应用程序视图”,分析“中断链接”,发现一些页面存在“范围内容超过最大容量的”的情况,在IE 浏览器中直接访问,发现这些页面存在死循环,页面内容无限递增。则在扫描配置- 排除路径和文件中排除这些页面。
根据以上设置,建立了两个扫描任务,均扫描“SQL 注入”和“跨站点脚本编制”。重新探索后,页面总数减少到4000 多,测试用例数减少到接近50,000,两个扫描任务均在8 个小时内完成。
回页首
总结
AppScan 作为一种自动化的扫描设置工具,我们了解其工作原理后,需要根据被测系统的业务特点和网站结构特点,优化配置,从而可以快速的针对性扫描。
常用的设置是可以利用其“探索”功能,快速得到结构,然后分析是否存在“伪静态页面”,业务上的“冗余路径”页面,“参数重复”页面等,在扫描配置中对应设置。
同时,如果设置后网站规模还是比较大,则可以根据业务分解为多个扫描任务,从而分而攻之,快速扫描,并结合企业版等工具,综合汇总分析。