harris、sift、surf、fast、brief、orb等key points提取算法
网上关于这些著名key points提取和描述方法的讲解很多,但很多文章在关键步骤的理解方面语焉不详,甚至有误。这里给出本人对这几种方法的理解。这几种方法中,sift、surf两种方法既包含检测方法(detector)也包含描述方法(descriptor),而harris和fast仅为检测子,brief仅为描述子。
1、detector
harris的原理是:key points附近在x和y方向的灰度变化都应该较大,反过来讲,如果一个像素附近x和y方向的灰度变化较大,我们有理由认为该点是key points点。harris用一阶微分来描述灰度变化大小。
注意:harris推到过程中用到的判别矩阵
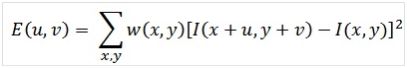
中,w(x,y)的作用是图像平滑,以减少噪声扰动。即,把指定窗口内的图像灰度变化进行平滑后作为窗口中心点的判别矩阵。网上许多文章对此理解有误。后面我们还将看到,对图像或图像变换进行平滑处理是key points检测的一个基本过程。
sift和surf具有尺度、旋转、照度不变性,是性能非常优异的detector。其中,后者可看作前者的改进,速度提升了约3倍。sift先建立gassian金子塔,继而建立dog金子塔。这样做的目的是把不同尺度的salient points突出出来。通过不同尺度的gassian滤波,得到图像不同尺度信息的同时,实现了图像的平滑滤波。而后通过空间域(同一尺度)及尺度域的比较把salient points中最saliency的points找出来作为候选key points。而后通过,位置搜索确定key points的准确位置。最后,通过hessian矩阵,筛掉边缘点。
注意:hessian矩阵的每个元素均为二阶导数,可由对应的laplassian算子计算得到。hessian矩阵的特征值表示灰度曲面((x,y,I(x,y))在当前像素位置的主曲率大小。优秀key points应在x和y方向都有较大的曲率。设候选key points的hessian矩阵H的特征值为a,b,且,a=rb,则tr(H)=a+b,det(H)=ab。因此,tr(H)^2/det(H)=(a+b)^2/ab=(r+1)^2/r=f(r)。r>=0时(此处恒成立,因为曲率恒大于等于0),函数f(r)在r=1时,取得最小值。而随着r的增大或者减小,f(r)的取值增大。边缘点处一个方向的曲率很大,另一个方向的曲率很小。故为了剔除候选key points中的边缘点,必须约束r的值在1附近(即两曲率大小相当),这可通过约束f(r) 为一较小值来实现。为什么不直接把hessian矩阵的特征值求解出来直接比较呢?因为计算稍微复杂一点,麻烦。
surf是直接通过近似hessian矩阵来检测key points的。为什么说是近似hessian 矩阵呢?因为hessian 矩阵的原始定义为

其中,L_xx,L_xy,L_yy,L_xy表示像素对应的二阶导数,本应通过laplassian算子与图像卷积直接计算得到。但是,我们之前讲过,对图像进行平滑处理以减弱噪声扰动是key points检测中的必要过程。 作者选择了gaussian二阶导数与原图像做卷积去近似上述四个二阶导数。如果把gaussian二阶导数绘制成图形(下图)可以看到,它与laplassian算子有相似的计算结构(laplassian的各模板元素分别对应gaussian二阶导数的各个峰值位置),可以看作是laplassian算子的平滑版。即后前者先在后者的模板各元素对应的图像位置处(以该位置为中心的窗口内)进行平滑滤波而后再执行前者的运算操作。(图片发不上去)
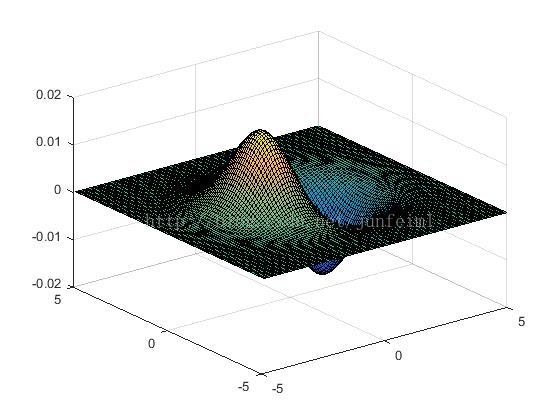
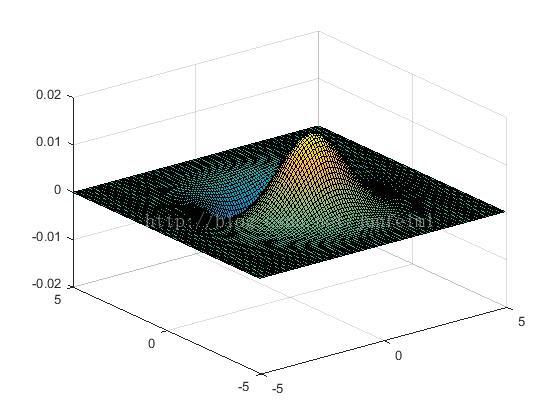
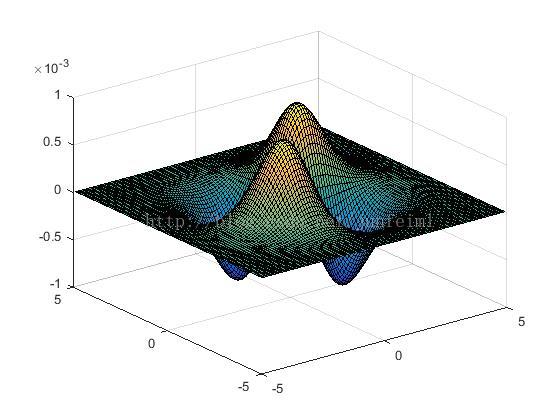
G^xx G^yy G^xy
为计算简单,作者并没有采用gaussian二阶导数算子直接去卷积图像,而是采用近似的boxfilter算子去做卷积。boxfilter 与图像的卷积结果可以通过对积分图像进行四次查表和三次加法运算快速获得,因此时耗很小。
surf检测key points的办法是在三维邻域内比较hessian矩阵行列式的大小。用box filter算子近似gaussian二阶导数算子会给hessian行列式的值带来误差。为了修正这一误差,surf采用了下式计算行列式
上式的推导过程可参见http://blog.csdn.net/cxp2205455256/article/details/41311013
(4)fast 是效率很高的检测子,速度大约是sift的100倍。删繁就简自然要损失很多性能,比如fast对尺度、旋转、光度变化都比较敏感。fast的思路很简单,就是当前像素和以其为中心的圆上的若干像素比较灰度大小。注意:这里的圆指圆周而非整个圆。为什么不与整个圆邻域内的像素比较大小?因为所需要的比较次数太多,fast要追求的是速度。这样粗糙比较检测出的keypoints候选点自然需要进一步筛选。筛选采用的是基于样本训练出的决策树。经过决策树筛选后再经过非极大值抑制(计算每个候选角点与其对应圆周上像素的绝对差,保留圆周上每10个连续像素的绝对差最小值,所有这些最小值中的最大值作为该角点非极大值抑制的参考值。如果参考值大于某一阈值,且大于候选角点邻域内的其他候选角点的参考值,则该候选角点确认为角点,其邻域内其他角点被剔除。
*决策数训练的过程为:把所有样本图像中所有像素及其对应的圆周提取出来。这些像素是否角点已被提前标记,对应圆周上像素的灰度与当前像素的灰度比较得出的状态(d,b,s)也已标记。然后采用ID3 方法,根据相应圆周上某位置的标记状态将像素依次分为三个子集(比如,用圆周上0位置的像素标记状态进行分类时,如果像素p对应的圆周0位置的像素标记为d,则p被分到d子集)。这种三叉树分类顺次进行下去,直到某一自己内的像素全为角点或者全部不是角点。
2、descriptor
sift描述子采用的是梯度方向直方图,suf采用的是harr小波变换的系数,而brief采用的是0、1字符串。这里值得注意的是brief描述子的生成过程。brief生成0、1字符串用的是keypoints邻域内的随机点对。随机点的x,y坐标服从以邻域尺寸为参数的独立同分布。随机点对在生成的时候的确是随机的,但是一旦生成就确定下来了,后续所有keypoints描述子的生成都用这组随机点对。如果要进行角点匹配,不同图像中keypoints的描述子的产生也要同用这一组随机点对。要不描述子就没有意义了。orb是基于brief提出的一种描述子,主要改进是增加了描述子的旋转不变性。文献采用fast提出keypoints,并计算其所在图像块矩中心坐标的反余切值(实际上就是x,y方向的一阶前向差分,右梯度?)作为主方向,而后将描述子旋转到其主方向坐标系内。显然,orb本身并无甚巨大创新,无非玩些类梯度方向作为主方向,旋转坐标系以实现旋转不变性的老把戏。brisk既是detector又是descriptor,检测用的是多尺度fast,描述用的是带方向的brief。