mongodb数据库基础详解
文章目录
- MongoDB简介
- Mongodb搭建
-
- 推荐步骤
- mongodb数据库的基本操作
-
- 创建数据表
- 查看数据库和表信息
- 更改数据信息
- 删除集合和数据库
- 统计表的数据记录
- 导出导出操作
-
- 导出操作
- 导入操作
- 条件操作
- 备份恢复数据库
-
- 备份数据库
- 恢复数据库
- 创建管理用户(前提开启验证功能)
- 进程管理
MongoDB简介
MongoDB是用C++语言编写的非关系型数据库。特点是高性能、易部署、易使用,存储数据十分方便,主要特性有:
●面向集合存储,易于存储对象类型的数据
●模式自由
●支持动态查询
●支持完全索引,包含内部对象
●支持复制和故障恢复
●使用高效的二进制数据存储,包括大型对象
●文件存储格式为BSON(一种JSON的扩展)
2.MongoDB与关系型数据库对比

3.MongoDB基本概念
●文档(document)是MongoDB中数据的基本单元,非常类似于关系型数据库系统中的行(但是比行要复杂的多);
集合(collection)就是一组文档,如果说MongoDB中的文档类似于关系型数据库中的行,那么集合就如同表;
●MongoDB的单个实例可以容纳多个独立的数据库,每一个数据库都有自己的集合和权限。
●MongoDB自带简洁但功能强大的JavaScript shell,这个工具对于管理MongoDB实例和操作数据作用非常大;
●每一个文档都有一个特殊的键"_id",它在文档所处的集合中是唯一的,相当于关系数据库中的表的主键。
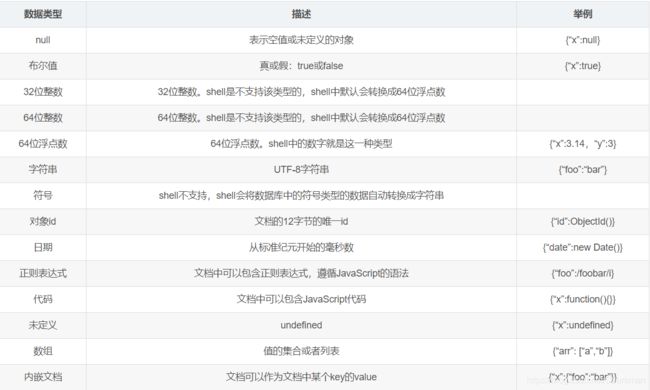
4.MongoDB数据类型
Mongodb搭建
推荐步骤
1.配置yum源仓库,安装mongo软件
[root@localhost ~]# cd /etc/yum.repos.d/
[root@localhost yum.repos.d]# vim mongodb-org.repo ##配置yum源
[mongodb-org]
name=MongoDB Repository ##名字随便取
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.6/x86_64/
gpgcheck=1 ##开启检查
enabled=1 ##开启
gpgkey=https://www.mongodb.org/static/pgp/server-3.6.asc
[root@localhost yum.repos.d]# yum list ##让其重新加载一下
[root@localhost yum.repos.d]# yum -y install mongodb-org ##安装mongodb工具包

[root@localhost yum.repos.d]# vim /etc/mongod.conf ##修改配置文件
port: 27017 ##mongodb的端口号为27017
bindIp: 0.0.0.0 # Listen to local interface only, comment to listen on all interfaces. ##将地址改为0.0.0.0;允许别人来访问
[root@localhost yum.repos.d]# systemctl start mongod.service ##开启服务
![]()
端口号为27017
[root@localhost yum.repos.d]# cd /etc/
[root@localhost etc]# cp -p mongod.conf mongod2.conf
[root@localhost etc]# vim mongod2.conf
systemLog:
destination: file
logAppend: true
path: /data/mongodb/mongod2.log ##日志文件地址修改做区分
.....
# Where and how to store data.
storage:
dbPath: /data/mongodb/mongo ##数据文件产生位置
......
# network interfaces
net:
port: 27018 ##修改端口号做区分
[root@localhost etc]# mkdir -p /data/mongodb ##创建目录
[root@localhost etc]# cd /data/mongodb/
[root@localhost mongodb]# mkdir mongo
[root@localhost mongodb]# touch mongod2.log ##创建日志文件
[root@localhost mongodb]# chmod 777 mongod2.log ##增加权限

[root@localhost mongodb]# mongod -f /etc/mongod2.conf ##指定mongo2的文件去登录
[root@localhost mongodb]# mongo --port 27018 ##登录指明端口号,不然登录的是第一个数据库

mongodb数据库的基本操作
创建数据表
> db.createCollection('info') ##创建一个info集合
{
"ok" : 1 }
> show dbs ##查看库等同于show databases;
admin 0.000GB
config 0.000GB
local 0.000GB
shcool 0.000GB ##在库里创了表的话,库不需要创建就会自动存在
> show collections ##显示库中的表等同于show tables;

查看数据库和表信息
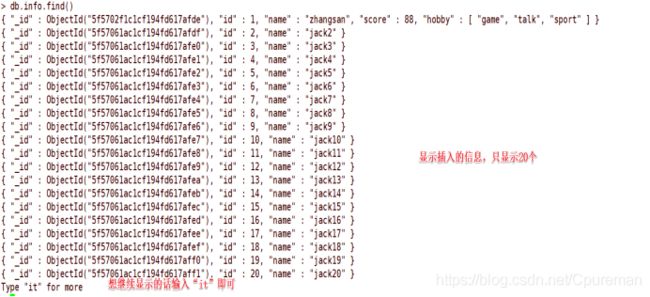
> db.info.find() ##显示info表中内容;等同于select * from table
> db.info.insert ({
"id":1,"name":"zhangsan","score":88,"hobby":["game","talk","sport"]})
WriteResult({
"nInserted" : 1 }) ##往表中写入信息;写入内容:id为1 姓名为:zhangsan 分数:88 hobby:兴趣爱好很多 等同于insert into table

> for (var i=2;i<=100;i++)db.info.insert({
"id":i,"name":"jack"+i}) ##用循环的方式插入数据
WriteResult({
"nInserted" : 1 })
显示插入的内容
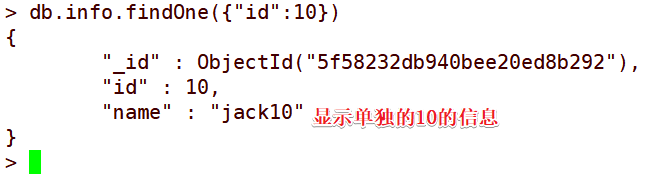
> db.info.findOne({
"id":10}) ##可以单独查找id为10的信息
查找第5条信息,并且定义别名为a
> a=db.info.findOne({
"id":5})
{
"_id" : ObjectId("5f58232db940bee20ed8b28d"), "id" : 5, "name" : "jack5" }
查看数据类型 typeof
> typeof(a.id)
number ##id为数值类型
> typeof(a.name)
string ##name为字符串类型
更改数据信息
> db.info.update({
"id":5},{
$set:{
"name":"tom"}}) ##将id为5的姓名改为tom(原本的姓名都为jack)
WriteResult({
"nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> a=db.info.findOne({
"id":5})
{
"_id" : ObjectId("5f58232db940bee20ed8b28d"), "id" : 5, "name" : "tom" } ##这时姓名jack改为了tom
删除集合和数据库
> db.createCollection('test') ##先创建一个test集合
{
"ok" : 1 }
> show tables ##也可以使用show tables显示集合
info
test
> db.test.drop() ##将test集合删除
true
> show tables
info ##再次查看发现test集合被删除,只有info集合
删除数据库
> use test ##1.先进入数据库
switched to db test
> db.dropDatabase() ##2.删除数据库
{
"dropped" : "test", "ok" : 1 }
> show dbs ##显示库,发现test库被删除了
admin 0.000GB
config 0.000GB
local 0.000GB
school 0.000GB
shcool 0.000GB
>
统计表的数据记录
> db.info.count()
99 ##表中有99条记录
导出导出操作
导出操作
Mongoexport -d 库名 -c 表名 -o 保存路径
[root@localhost opt]# mongoexport -d shcool -c info -o /opt/shcool.json ##将shcool库中的info表信息导入到/opt目录下的shcool.json
[root@localhost opt]# vim shcool.json
{
"_id":{
"$oid":"5f5833ddad90ec3b19fec388"},"id":1.0,"name":"zhangsan","score":88.0,"hobby":["game","talk","sport"]} ##存入了库中的信息
导入操作
Mongoimport -d 库名 -c 表名 --file 路径
[root@localhost opt]# mongoimport -d shcool -c test --file /opt/shcool.json ##将数据导入到shcool库中生产一个新的test表
2020-09-09T09:50:11.217+0800 connected to: localhost
2020-09-09T09:50:11.225+0800 imported 1 document
> use shcool
switched to db shcool
> show tables ##显示了两张表
info
test
> db.test.find()
{
"_id" : ObjectId("5f5833ddad90ec3b19fec388"), "id" : 1, "name" : "zhangsan", "score" : 88, "hobby" : [ "game", "talk", "sport" ] }
条件操作
将shcool库中的info表中的id为1的信息备份到/opt/top1.json文件中
[root@localhost opt]# mongoexport -d shcool -c info -q '{"id":{"$eq":1}}' -o /opt/top1.json
[root@localhost opt]# vim top1.json
{
"_id":{
"$oid":"5f5833ddad90ec3b19fec388"},"id":1.0,"name":"zhangsan","score":88.0,"hobby":["game","talk","sport"]} ##信息保存了
备份恢复数据库
备份数据库
[root@localhost opt]# mkdir /backup ##先创建一个备份目录
[root@localhost opt]# mongodump -d shcool -o /backup/ ##将shcool库保存到backup目录下
2020-09-09T10:07:05.334+0800 writing shcool.test to
2020-09-09T10:07:05.334+0800 writing shcool.info to
2020-09-09T10:07:05.335+0800 done dumping shcool.test (1 document)
2020-09-09T10:07:05.335+0800 done dumping shcool.info (1 document)

恢复数据库
[root@localhost shcool]# mongorestore -d abc --dir=/backup/shcool ##将备份的数据恢复到abc的库中(这个库当有表的情况下,会自己创建)
> show dbs
abc 0.000GB ##有新创建的abc的库
admin 0.000GB
config 0.000GB
local 0.000GB
shcool 0.000GB
> use abc ##进入abc库
switched to db abc
> show tables ##显示库中的键
info
test
复制数据库
> for (var i=1;i<=100;i++)db.test.insert({
"id":i,"name":"jack"+i}) 先创建一个循环集合
WriteResult({
"nInserted" : 1 })
> show tables ##查看集合
info ##创建成功
Test ##原本就存在的集合
> db.copyDatabase("shcool","beifen") ##2.将shcool库拷贝一份为beifen库
{
"ok" : 1 }
> show dbs
admin 0.000GB
beifen 0.000GB ##复制成功
config 0.000GB
local 0.000GB
shcool 0.000GB
> use beifen
switched to db beifen
> show tables; ##连同集合都复制过来
info
test
克隆集合
1.先创建多实例
之前创建过2的实例,所以暂时不用创建了
[root@localhost logs]# mongo --port 27018 ##进入27018的实例
> db.runCommand({
"cloneCollection":"beifen.info","from":"192.168.148.135:27017"})
##将148.135地址的beifen库中的info表克隆到实例2中
> show dbs
admin 0.000GB
beifen 0.000GB ##beifen库克隆过来了
config 0.000GB
local 0.000GB
test 0.000GB
> use beifen
switched to db beifen
> show tables
Info ##info表也克隆过来
创建管理用户(前提开启验证功能)
> db.createUser({
"user":"root","pwd":"123","roles":["root"]})
> db.auth("root","123")
进程管理
> db.currentOp() ##显示进程信息
......
"opid" : 14716, ##进程号
> db.killOp(14716) ##将进程号删除不代表数据库不能用,相当于释放下内存,之后会在开启的
{
"info" : "attempting to kill op", "ok" : 1 }