python基础、爬虫基础、数据分析及可视化基础学习
python基础、爬虫、数据分析学习笔记
- 一、Python基础
-
- I. 基本数据类型
-
- i. int、float、str、bool数据类型的定义
- ii. tuple(元组):
- iii. list(列表)
- iv. set(集合):
- v. dict(字典)
- II. 基本控制结构
-
- i. if-elif-else语句:
- ii. for语句:
- iii. while语句
- iv. in,and,or,break,contiue语句
- III. 函数定义:
- IV. 文件读取
- 二、Python爬虫
-
- I. 获取本地用户代理信息
- II. Requests库
-
- i. requests的安装
- ii. requests、Cookie免登陆、Session保持会话
- III. 正则表达式
- IV. 筛选网页信息
- 三、数据分析基础
-
- I. Jupyter Notebook 数据分析及可视化工具
-
- i. jupyter notebook的安装
- ii. 使用jupyter notebook进行数据可视化的基本配置
- II. Pandas、numpy、matplotlib库的安装:
- III. Pandas的基本使用
-
- i. Pandas读取文件
- ii. Pandas.Series的基本语法
- iii. pandas.Dataframe的基本语法
- IV. 数据处理
- 四、数据可视化基础
-
- I. 画布
-
- i. 在一个画布上绘制多个图表
- II. 条形图
-
- i. 在一个坐标轴上绘制两个条形图
- ii. 横向条形图
- III. 折线图
- IV. 饼图
一、Python基础
1. python中变量的定义不用在变量名前面声明变量类型,编译器会根据赋值的数值区分数据类型
2. 字符串用单引号('python')或者双引号("python")均可
3. python对代码书写格式做出了严格的要求,用缩进替换了传统"{}"表示语句作用范围的方式
I. 基本数据类型
| 数据类型 | 表达式 |
|---|---|
| int | 整形 |
| float | 浮点型 |
| str | 字符型 |
| bool | 布尔类型 |
| tuple | 元组 |
| list | l列表 |
| set | 集合 |
| dict | 字典 |
i. int、float、str、bool数据类型的定义
a = 1 # int
b = 1.1 # float
c = 'python' # str
d = True # bool
print('a:', type(a), 'b:', type(b), 'c:', type(c), 'd:', type(d), sep='\n')
#输出结果:
a:
<class 'int'>
b:
<class 'float'>
c:
<class 'str'>
d:
<class 'bool'>
ii. tuple(元组):
元组和列表相似,但一旦确定无法无法更改,即无法增加或者删除某个元素,只能删除整个元组
# 创建元组
tuple1 = () # 空元组
tuple2 = (1,) # 单个元素,","不能少
tuple3 = (1, 2, 3, "python", "java") # 多个元素
print(tuple1, tuple2, tuple3, sep='\n')
'''
输出结果:
()
(1,)
(1, 2, 3, 'python', 'java')
'''
# 访问元素
print(tuple3[1]) # 下标访问
print(tuple3[0:2:1]) # 切片访问
'''
输出结果:
2
(1, 2)
'''
# 删除元组
del tuple2
# 元素个数
print(len(tuple3))
'''
输出结果:
5
'''
# 元素遍历
for Member in tuple3:
print(Member)
for i in range(len(tuple3)):
print(tuple3[i])
'''
输出结果:
1
2
3
python
java
1
2
3
python
java
'''
iii. list(列表)
# 创建列表
List1 = [] # 空列表
List2 = [1, 2, "python", "java"] # 普通列表
List3 = [[1, 2], ["python", "java"]] # 复合列表
print(List1, List2, List3, sep='\n')
'''
输出结果:
[]
[1, 2, 'python', 'java']
[[1, 2], ['python', 'java']]
'''
# 访问元素
print(List2[0]) # 输出第一个元素
print(List2[0:2:1]) # 输出从0每次增一到2-1位置的元素,输出结果一个列表
'''
输出结果:
1
[1, 2]
'''
# 插入元素
List2.append("c++") # 插入字符串'c++'
print(List2)
'''
输出结果:
[1, 2, 'python', 'java', 'c++']
'''
# 删除元素
List2.remove(1) # 删除第1个元素
print(List2)
del List2[1] # 删除下标为1的元素
print(List2)
List2.pop() # 删除末尾元素
print(List2)
List2.clear() # 清空列表元素,操作后为空列表
print(List2)
del List2 # 删除整个列表
'''
输出结果:
[2, 'python', 'java', 'c++']
[2, 'java', 'c++']
[2, 'java']
[]
'''
# 元素个数
print(len(List3))
'''
输出结果:
2
'''
# 元素反转
List3.reverse()
print(List3)
'''
输出结果:
[['python', 'java'], [1, 2]]
'''
# 元素遍历
for Member in List3:
print(Member)
for i in range(len(List3)):
print(List3[i])
'''
输出结果:
['python', 'java']
[1, 2]
['python', 'java']
[1, 2]
'''
iv. set(集合):
满足数学上对集合的定义,无序,互异,所以集合中不存在重复的元素,即有去重功能,也不能通过下标来访问某个元素,只能判断集合中是否存在某个元素
# 创建集合
set1 = set()
set2 = {
1, 2, 'python', 'java'}
set3 = {
(1, 2), 'python', 'java'}
print(set1, set2, set3, sep='\n')
'''
输出结果:
set()
{1, 2, 'java', 'python'}
{'java', 'python', (1, 2)}
'''
# 判断某个元素是否存在
print('python' in set2)
'''
输出结果:
True
'''
# 添加元素&去重
set2.add('c++') # 单个元素的添加
print(set2)
set2.update({
1, 3, 5, 'c#'}, [5, 4, 2]) # 多个元素的添加,加入的不是集合和列表,而是其中的元素,不会添加集合中已经存在的元素
print(set2)
'''
输出结果:
{1, 2, 'python', 'java', 'c++'}
{1, 2, 3, 4, 5, 'python', 'java', 'c++', 'c#'}
'''
# 删除元素
set2.remove(1) # 元素不存在会报错
print(set2)
set2.discard('j') # 元素存在则删除,且不存在时不会报错
print(set2)
set2.pop() # 随机删除一个元素
print(set2)
set2.clear() # 清空集合中的元素
print(set2)
del set2 # 删除集合
'''输出结果:
{2, 3, 4, 5, 'python', 'java', 'c++', 'c#'}
{2, 3, 4, 5, 'python', 'java', 'c++', 'c#'}
{3, 4, 5, 'python', 'java', 'c++', 'c#'}
set()
'''
# 集合中元素个数
print(len(set3))
'''输出结果:
3
'''
# 集合的运算
a = {
1, 2, 3, 4, 5}
b = {
4, 5, 6, 7, 8}
print(a & b) # 交集
print(a | b) # 并集
print(a ^ b) # 不同时存在于两个集合中的元素
print(a - b) # 存在于a不存于b中的元素
'''
输出结果:
{4, 5}
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 6, 7, 8}
{1, 2, 3}
'''
# 集合的遍历
for Member in set3:
print(Member)
'''
输出结果:
java
python
(1, 2)
'''
v. dict(字典)
# 创建字典
dic1 = {
}
dic2 = {
'python': 99, 'java': 99, 'c#': 99}
dic3 = {
'score': (99, 98, 97), 'id': [1, 2, 3], 'java': {
's': 99}}
print(dic1, dic2, dic3, sep='\n')
'''
输出结果:
{}
{'python': 99, 'java': 99, 'c#': 99}
{'id': (1, 2, 3), 'score': [99, 98, 97], 'java': {'popular': 99}}
'''
# 通过字典的键访问元素
print(dic2['python'])
'''
输出结果:
99
'''
# 添加&修改元素
dic2['c++'] = 99
print(dic2)
dic2['java'] = 99.9
print(dic2)
'''
输出结果:
{'python': 99, 'java': 99, 'c#': 99, 'c++': 99}
{'python': 99, 'java': 99.9, 'c#': 99, 'c++': 99}
'''
# 删除元素
del dic2['c#'] # 删除键为'c#'的元素
print(dic2)
dic2.clear() # 清空字典
print(dic2)
del dic2 # 删除字典
'''输出结果:
{'python': 99, 'java': 99.9, 'c++': 99}
{}
'''
# 字典中元素个数
print(len(dic3))
'''输出结果:
3
'''
# 字典的遍历
for item in dic3.items():
print(item)
for key, value in dic3.items():
print(key, value)
for key in dic3.keys():
print(key)
for value in dic3.values():
print(value)
'''
输出结果:
('score', (99, 98, 97))
('id', [1, 2, 3])
('java', {'s': 99})
score (99, 98, 97)
id [1, 2, 3]
java {'s': 99}
score
id
java
(99, 98, 97)
[1, 2, 3]
{'s': 99}
'''
II. 基本控制结构
i. if-elif-else语句:
条件不需要'()',条件后需要':'
if x < 1:
print('Hello')
elif x > 1:
print('World')
else:
print('Hello World')
ii. for语句:
for 循环参数 in 一个序列:
#输出100以内的偶数
for i in range(0, 100, 2):#range函数的参数说明:初始值,最终结果,差值,这里表示从0开始每次增加2,达到100结束,无法取得100,
print(i)
iii. while语句
while 条件:
print('Hello World')
iv. in,and,or,break,contiue语句
- in:用于判断包含关系,比如判断某个元素是否在某个列表中存在,存在返回True,否则False
- and :等价于&&
- or :等价于||
- break:结束当前循环
- continue:跳过此次循环
III. 函数定义:
def 函数名(参数)->返回值类型:
def add(x, y) -> int:
return x + y
# main函数的定义:
if __name__ == '__main__':
add(1, 1)
IV. 文件读取
推荐参考博客python 文件读写操作
二、Python爬虫
在使用爬虫时,我们需要使用本地代理作为请求头向服务器发送访问请求,这是爬虫使用的基本常识,很多网站一般都会有反爬虫措施,如果直接使用爬虫访问,一般会出现异常,无法访问,多次请求无效还可能会导致账号被锁定,无法使用,所以不要直接使用爬虫爬取网站数据,使用本地代理访问可以让服务器认为我们是通过本地浏览器在进行访问,安全有效
I. 获取本地用户代理信息
- 在网页中按F12键或者点击鼠标右键选中检查即可打开调试界面
- 选中Network栏,然后按F5再次刷新网页

- 选择All

- 随便选择Name栏下面的一个数据

- 选择Headers

- 在Request Headers下找到user-agent,user-agent后就是本地代理信息
II. Requests库
i. requests的安装
- 方法一:在PyCharm安装第三方库,推荐文章:PyCharm中第三方库的安装
- 方法二:
- 找到python3安装位置中的Scripts文件夹或者从已创建的python项目中找到venv\Scripts文件夹或者Anaconda安装位置的Scripts文件
- 按住Shift+鼠标右键,点击在此处打开Powershell窗口。
- 接着输入:
pip install -i https://pypi.douban.com/simple requests指令,系统将自动下载安装requests库。 - 安装完成后,在pycharm中导入包:
import requests
ii. requests、Cookie免登陆、Session保持会话
# 一般请求
Headers = {
# 请求头信息
'User-Agent': '代理信息'
}
respond = requests.get(url="网址", headers=Headers) # 获取网页信息
print(respond.text) # 文本形式打印网页信息
# 登录请求:Headers->Name->Login->Form
data = {
'username': '账号',
'password': '密码'
}
respond = requests.post(url="网址", data=data, headers=Headers)
print(respond.text)
# Cookie免登录
Headers = {
'User-Agent': '代理信息',
'Cookie': 'Cookie信息'
}
respond = requests.get(url="网址", headers=Headers)
print(respond.text)
# 单独的requests语句之间没有联系
# 使用Session保持会话信息
session = requests.Session()
respond = session.post(url="网址", data=data) # 登录
respond1 = session.get(url="网址") # 获取登录后界面
print(respond1.text)
III. 正则表达式
有关正则表达式的使用方法,菜鸟教程中有对其的详细解释,可以自主参考菜鸟教程–正则表达式去学习。
IV. 筛选网页信息
import re #第三方库re
info = re.findall("正则表达式", 数据序列)
三、数据分析基础
I. Jupyter Notebook 数据分析及可视化工具
i. jupyter notebook的安装
推荐文章Anaconda—Jupyter Notebook 安装教程
ii. 使用jupyter notebook进行数据可视化的基本配置
%matplotlib inline #让jupyter notebook直接在单元格内显示生成的图形
plt.rcParams['font.sans-serif']='SimHei' #解决matplotlib在windows电脑上中文乱码的问题
plt.rcParams['axes.unicode_minus']=False #解决matplotlib符号无法显示的问题
%config InlineBackend.figure_format='svg' #让图片变成矢量形式,显示的更清晰
II. Pandas、numpy、matplotlib库的安装:
- 找到Anaconda安装位置中的Scripts文件夹
- 按住Shift+鼠标右键,点击在此处打开Powershell窗口。
- 接着输入:
pip install -i https://pypi.douban.com/simple numpy pandas matplotlib指令,系统将自动下载安装numpy、pandas、matplotlib库。
III. Pandas的基本使用
i. Pandas读取文件
# 修改当前工作路径,优点是读取文件可以直接使用文件名读取,不需要完整路径
import os # os库
os.getcwd() # 查看当前工作路径
os.chdir(r'想要修改的工作路径') # 修改当前工作路径
# 读取Excel文件.xlsx/.xls
result = pandas.read_excel(r'文件地址')
# 可添加参数:
sheet_name = "" # 读取第几页的文件
header = None # 取消列索引,默认header = 0,以第一行作为列索引
index_col = 0 # 以第一列作为行索引,默认没有行索引
names = [] # 修改列名
nrows = n # 指定读取行数
skiprows = [行索引名] # 忽略指定行
usecols = [列索引名] # 读取指定列
#读取csv文件.csv
engine = "python" # csv文件的中文
sep = "" # 指定分隔符,默认是逗号
ii. Pandas.Series的基本语法
# 列表构建Series:
# 索引默认从0开始,以列表值作为数据
ser = pandas.Serise(列表序列)
# 字典构建Series:
# 以键 - 值作为索引 - 数据
ser = pandas.Serise(字典序列)
ser.index # 获取全部索引
ser.values # 获取全部数据
ser.index[:] # 切片获取索引
ser.values[:] # 切片获取数据
# 索引值的修改需要统一处理
ser.index = []
# 数据的修改可以通过index或者切片处理,不支持统一修改
ser['0'] = ''
ser[['0', '2']] = ["", ""]
ser[:] = []
iii. pandas.Dataframe的基本语法
Dataframe # 类似二维数组,行索引-列索引-数据
# 列表构建Dataframe:
# 传入单个列表时,产生行索引长度等于列表长度,列索引为0的数据结构,列表的每个元素作为每一行的数据
df = pandas.Dataframe(列表序列)
# 传入多个列表时,产生行索引长度等于列表个数,列索引长度等于所有列表长度中的最大值的数据结构,每个列表的元素作为每一行的数据
df = pandas.Dataframe(list0, list1, list2)
# 字典构建Dataframe
# 键作为列标签,值作为每列的元素,行索引默认从0开始
df = pandas.Dataframe(字典序列)
# 创建Dataframe时指定行列索引
df = pandas.Dataframe(index='行索引序列', columns='列索引序列')
df.index # 获取行索引
df.columns # 获取列索引
df.values # 获取数据
# 修改全部行列索引
df.index = []
df.columns = []
# 修改指定行列标签
df.rename(index=["原行索引名": "修改索引名"], columns = ["原列索引名": "修改索引名"], inplace = True) # inplace默认为False,为True时在原文修改
df.shape # 获取维度信息
df.T # 转置
df[列索引名] # 获取某列的数据
df[列索引名].value_counts() # 统计某列中各个元素的个数
df[列索引名].unique() # 获取不重复元素
df[列索引名].nunique() # 获取不重复元素的个数
df.nunique() # 获取每一列不重复元素的个数
df.describe() # 描述df的基本情况,针对数值类型的列生效
df.info() # 显示每列的数据类型
df.head(n) # 指定显示前n行的信息
df.tail(n) # 指定显示后n行的信息
IV. 数据处理
使用Pandas读取文件后得到的Dataframe的数据处理
# df为Dataframe化后的数据
df.isnull() # 查看每个数据的缺失值
df.isnull().sum() # 查看每列缺失值的总数
df.dropna() # 删除缺失值,inplace默认False,默认axis = 0删除行,axis = 1删除列,how = 'all'设置整行 / 列为空时才删除
na_values = "暂无" # 将指定值替换成空值
df.replace("暂无", numpy.nan, inplace=True) # 同上
df.apply(lambda x: 表达式) # 对数据使用函数处理
df.fillna() # 填充缺失值
df.drop_duplicates() # 清楚重复值
df.reset_index(drop=True) # 重新定义行索引
df.drop_duplicates(keep="last") # 默认保留第一条重复值,修改为last保留最后一条,False全部删除
df.drop_duplicates(subset=[]) # 设置指定列或多了重复作为重复判断依据
数据类型转换
df.astype(numpy.int) # 修改数据类型
# 日期格式类型转换
pandas.to_datetime(df["日期"], format="%Y-%m-%d")
df["日期"].dt.year # 获取年份
parse_dates = [列索引名] # 在读取文件时将日期列转化为日期数据类型
df[列索引名].str.replace(原数据字符, 想要修改的数据字符)
df[列索引名].str[:] # 切片获取字符
df.set_index(列索引名) # 将某列设置为行索引,可能需要数据类型转换
# 数据选择
df[列索引名] # 单列选择
df[[列索引名1, 列索引名2]] # 多列选择
df.iloc[行索引切片, 列索引切片] # 多行多列选择
df.iloc[[], []] # 根据索引名选择行列
df.loc[] # 根据单个行标签选择
df.loc[[]] # 根据多个行标签选择
df.loc[[], []] # 根据多个行列标签选择
df.ix[行索引切片, [列索引名]]
df[条件选择] # 根据单个条件选择
df[(条件) & (条件)] # 根据多条件选择
df[(条件) | (条件)] # 根据多条件选择
df[列索引名].isin(条件) # 判断数据是否符合条件
df.replace(原值, 期望值) # 一对一数据替换
df.replace([], 期望值) # 多对一数据替换
df.replace({
原值: 期望值, 原值: 期望值})
# 第三方包
import warnings
warnings.filterwarnings("ignore") # 忽略警告提示
# 数据排序
df.sort_values(by=列名, ascending=False) # 根据某一列数值排序,ascending默认True从小到大排序
df.sort_values(by=[列名1, 列明2], ascending=[True, False]) # 根据多了数值进行排序
# 数值删除
df.dropna() # 删除空值
df.drop([列标签], axis=1) # 按列名删除,axis = 0
# 按行删除
df.drop(df.columns[[列的位置,列的位置]], axis = 1) # 按列的位置删除
df.drop(df.columns[[列的位置:列的位置]], axis = 1) # 按列的位置切片删除
df.drop([行标签,行标签])
df.drop(df.index[:]) # 切片删除行
# 插入新的列
df.insert(插入位置, 列名, 插入数据)
df[新列名] = [数据]
# 插入分组列
bins = [0, 100, 200, 300] # 分组区间
labels = ['100以下', '100 - 200', '200以上'] # 分组标签
df[新列名] = pandas.cut(df[列名], bins, labels=labels) # 根据某列添加分组列
df[列名].apply(lambda x: str(x) + "元") # 对某列数据操作
df.applymap() # 对所有数据操作
# 数据运算
df[列名] = df[列名] + df[列名]
df[].sum()
.count() # 个数
.mean() # 平均
.max()
.min()
.median() # 中位数
.mode() # 众数
.var() # 方差
.std() # 标准差
.quantile(q=) # 分位数
# 时间序列
import datetime # 库
datetime.now()
datetime.now().year
datetime.now().weekday() + 1 # 星期几
datetime.now().isocalendar() # 当前年份第几周星期几
datetime.now() + timedelta(days=1) # 加一天
date = datetime(2020, 5, 20, 13, 14) # 构造时间类型
import pandas.tseries.offsets
import Day, Hour, Minute
datetime.now() + Day(1) # 加一天
# 数据拼接
pandas.concat(['文件1','文件二'], ignore_index = True) # 默认axis = 0竖向拼接
# 数据分组统计
df.grouby(列名1,列名2) # 根据列1,列2进行分类
df.grouby(列名1,列名2)[] # 取根据列1,列2进行分类后的某一列
.count() # 计算每个值根据列名分类的数量
.sum() # 针对数值类型进行分类求和
df.grouby(列名1)[列名].aggregate(["count"], ["mean"]) # 对分类数据进行多次操作
四、数据可视化基础
I. 画布
在未自定义画布的情况下直接创建坐标系,画布大小默认一个坐标系,当需要同时创建多个坐标系时,需要自己创建画布以及坐标轴生成位置
- 自定义画布大小
fig = plt.figure(figsize=(8, 6)) #创建一个8*6的画布
plt.plot() #以整个画布为范围创建坐标系
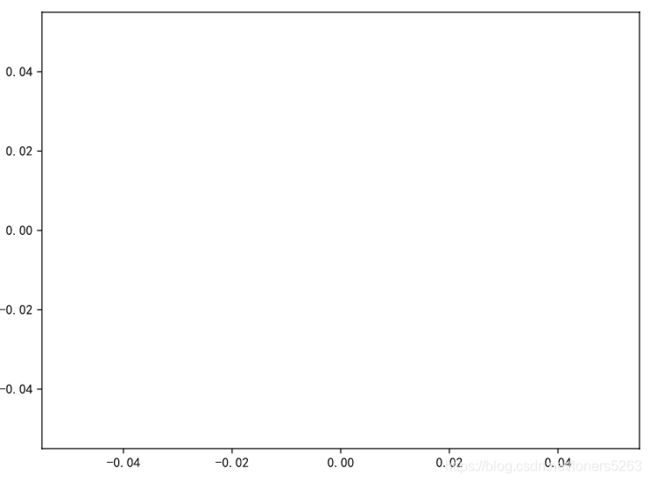
- 自定义画布大小并在指定位置创建坐标系
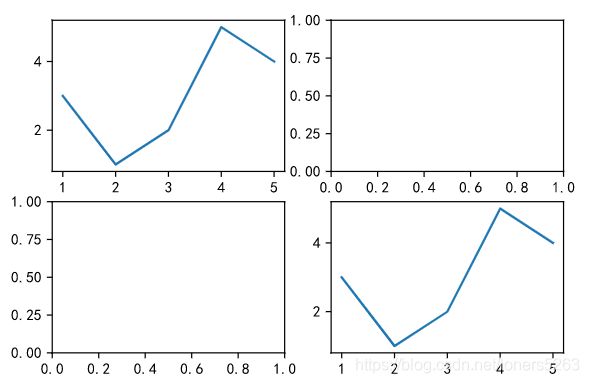
i. 在一个画布上绘制多个图表
- 方法一(需要先创建画布才能添加坐标轴)
fig = plt.figure(figsize=(8, 6))
x = [1, 2, 3, 4, 5]
y = [3, 1, 2, 5, 4]
ax1 = fig.add_subplot(4, 2, 6) #在4行、2列、坐标轴编号为6位置增加一个坐标系
ax2 = fig.add_subplot(4, 2, 1) #在4行、2列、坐标轴编号为1位置增加一个坐标系
ax1.plot(x, y)
ax2.plot(x, y)
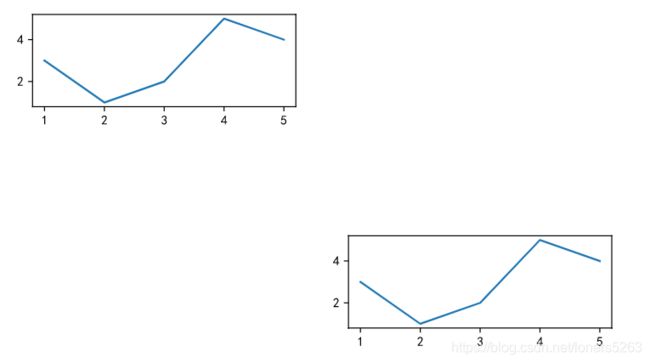
- 方法二
x = [1, 2, 3, 4, 5]
y = [3, 1, 2, 5, 4]
ax1 = plt.subplot(3, 3, 3) #在3行、3列、编号为3位置建立坐标系
ax2 = plt.subplot(3, 3, 4) #在3行、3列、编号为4位置建立坐标系
ax1.plot(x, y)
ax2.plot(x, y)
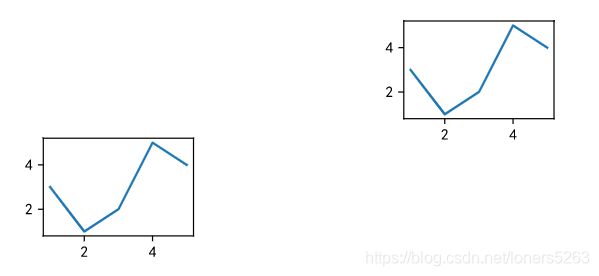
- 方法三
x = [1, 2, 3, 4, 5]
y = [3, 1, 2, 5, 4]
fig,axes = plt.subplots(2, 2) #创建大小2*2的画布
axes[0, 1].plot(x, y) #在0行1列创建坐标系
axes[1, 0].plot(x, y) #在1行0列创建坐标系

- 方法四
x = [1, 2, 3, 4, 5]
y = [3, 1, 2, 5, 4]
ax1 = plt.subplot2grid((2, 2), (0, 0)) #在0行0列创建坐标系
ax2 = plt.subplot2grid((2, 2), (0, 1))
ax3 = plt.subplot2grid((2, 2), (1, 0))
ax4 = plt.subplot2grid((2, 2), (1, 1))
ax1.plot(x, y)
ax4.plot(x, y)
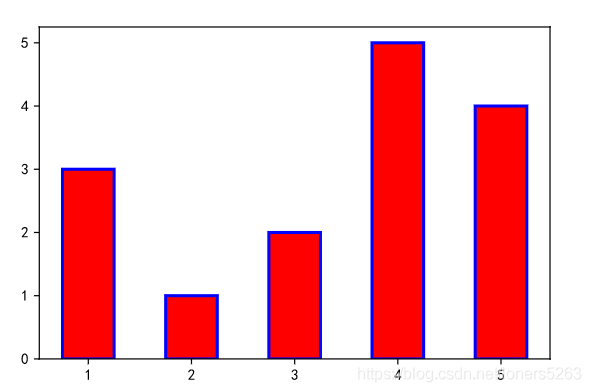
II. 条形图
x = [1, 2, 3, 4, 5] #x轴参数列表
y = [3, 1, 2, 5, 4] #Y轴数值列表
plt.bar(x, #x轴位置参数
y, #Y轴数据参数
label='注册人数统计表', #图像标签,搭配legend使用
align='center', #含两个参数'center'/'edge',条形图显示的位置,
width=0.5, #条形宽度
color='red', #条形颜色
edgecolor='blue', #条形边框颜色
linewidth='2', #条形边框宽度
bottom=None, #图像的基准位置,当需要两个对比图像时,以另一个Y轴数值列表作为bottom
alpha=1) #透明度,值越小越透明
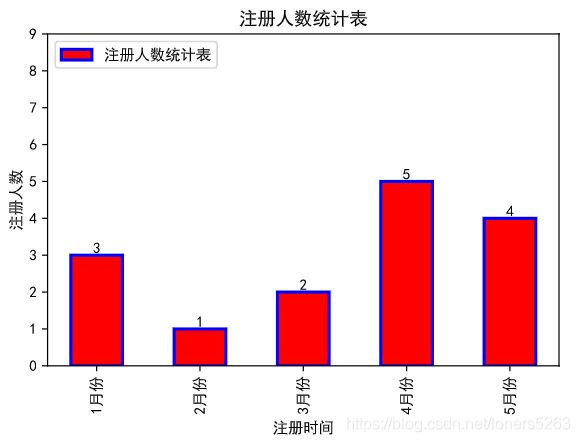
for a,b in zip(x,y): #在条形顶部加标签,一般用于显示数值
plt.text(a,
b,
b,
ha='center', #标签显示部位
va='bottom',
fontsize=10) #标签字体大小
plt.xticks(x,
[str(i)+'月' for i in x], #给x轴参数添加'月'字
fontsize=10, #调整x轴参数的字体大小
rotation=90) #调整x轴参数的旋转角度
plt.yticks(np.arange(0, 10, 1)) #调整y轴数值间隔,此处np为numpy
plt.legend(loc = 'upper left') #显示图例,默认best自适应显示位置,此外还有'upper right'、'upper left'、'lower left'、'lower right'、'right'、'center left'、'center right'、'lower center'、'upper center'、'center'
plt.xlabel('注册时间') #x轴数据标签
plt.ylabel('注册人数') #y轴数据标签
plt.title('注册人数统计表') #图表标题
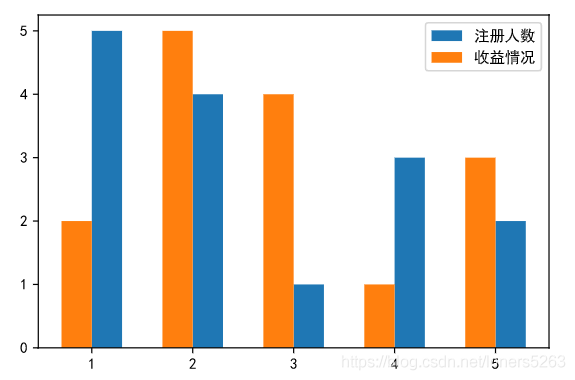
i. 在一个坐标轴上绘制两个条形图
x = np.array([1, 2, 3, 4, 5])
y = [5, 4, 1, 3, 2]
y1 = [2, 5, 4, 1, 3]
plt.bar(x+0.15, y, label='注册人数', width=0.3)
plt.bar(x-0.15, y1, label='收益情况', width=0.3)
plt.legend()
ii. 横向条形图
x = [1, 2, 3, 4, 5]
y = [5, 4, 1, 3, 2]
plt.barh(x,
height=0.5,
width=y,
align='center',
label='注册量')
plt.xticks(np.arange(0,10,1))
for a,b in zip(x,y):
plt.text(b,
a,
b,
ha='left',
va='bottom',
fontsize=10)
plt.legend()
III. 折线图
x = [1, 2, 3, 4, 5]
y = [3, 1, 2, 5, 4]
y1 = [5, 1, 4, 2, 3]
plt.plot(x, #x轴参数
y, #y轴参数
label='注册人数', #图像标签,搭配legend使用
color='red', #折线颜色
linestyle='--', #折线虚线显示
linewidth=2, #折线粗细程度
marker='o', #结点形状
markersize=4) #结点大小
plt.plot(x,
y1,
label='注册人数', #图像标签,搭配legend使用
color='blue',
linestyle='-', #折线实线显示
linewidth=2,
marker='o',
markersize=4)
for a,b in zip(x, y): #添加顶点标签
plt.text(a,
b,
b,
ha='center',
va='bottom',
fontsize=12)
for a,b in zip(x, y1):
plt.text(a,
b,
b,
ha='center',
va='bottom',
fontsize=12)
plt.xlabel('注册时间', #x轴标签名称
labelpad=10, #标签和坐标轴距离
fontsize='large', #字体大小
color='red', #字体颜色
fontweight='bold') #字体加粗
plt.ylabel('注册人数', #y轴标签名称
labelpad=10,
fontsize='large',
color='red',
fontweight='bold')
plt.xticks(x,
[(str(i)+'月') for i in x]) #给x轴每个参数加上'月'字
plt.yticks(y,
[(str(i)+'K人次') for i in y]) #给y轴每个参数加上'k人次'字
plt.title('前半年注册人数统计表', #表格的标题,loc='center'显示在中央
loc='center')
plt.grid(True,
axis='both') #True表示添加网格,axis=x只显示x轴网格
plt.legend(loc='best') #显示图例

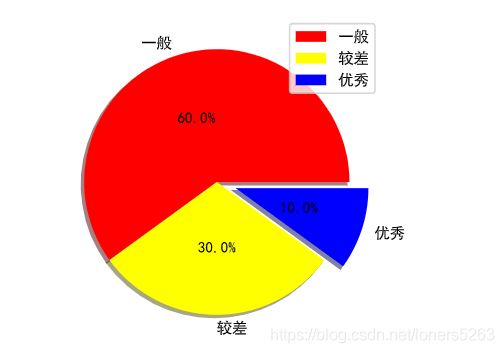
IV. 饼图
labels = ['一般', '较差', '优秀']
sizes = [60, 30, 10]
colors = ['red', 'yellow','blue']
explode=[0, 0, 0.15]
plt.pie(sizes, #每一部分的大小
labels=labels, #每一部分的标签名称
colors=colors, #每一部分的颜色
explode=explode, #突出显示
labeldistance=1.1, #标签名称到图的距离
autopct='%3.1f%%', #百分比显示
shadow=True, #显示阴影
pctdistance=0.5) #百分比显示到图的距离
plt.legend()