代码系列:Keras实现自定义contrastive loss及多输入多输出model
以contrastive loss为例,contrastive loss用于成对的数据(pair data),通常出现在孪生网络(siamese network)中,公式如下:

其中,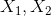 表示输入的pair data的特征向量;
表示输入的pair data的特征向量; 表示pair data的标签是否相同,取值为0(不同)或1(相同);
表示pair data的标签是否相同,取值为0(不同)或1(相同);![]() 表示之间的距离(一般为欧式距离),表达式如下:
表示之间的距离(一般为欧式距离),表达式如下:

因此整个contrastive loss的定义为:输入的pair data如果是同一类(标签相同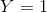 ),loss取第一项,则它们的特征向量之间的距离
),loss取第一项,则它们的特征向量之间的距离![]() 要尽量小;如果不是同一类(标签不同
要尽量小;如果不是同一类(标签不同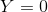 ),loss取第二项,则它们的特征向量之间的距离
),loss取第二项,则它们的特征向量之间的距离![]() 会尽量大于m。m即margin,可以看作设定的类间差。两项loss图示如下:
会尽量大于m。m即margin,可以看作设定的类间差。两项loss图示如下:
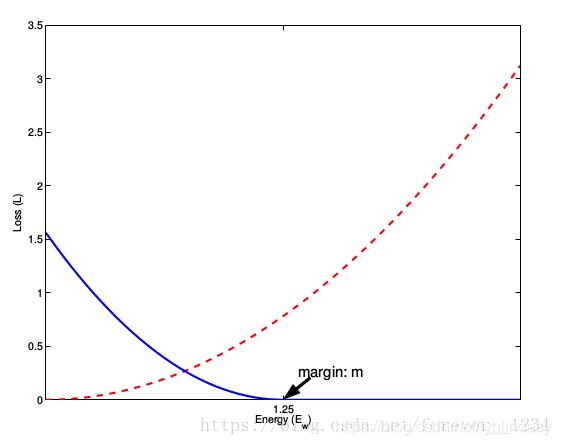
上图横坐标为pair data的特征向量间距离,即![]() 。红色虚线为时的loss即第一项,随着
。红色虚线为时的loss即第一项,随着![]() 的增加loss会增加,因此优化时会使得
的增加loss会增加,因此优化时会使得![]() 变小;蓝色实线为时的loss即第二项,在1.25之前随着
变小;蓝色实线为时的loss即第二项,在1.25之前随着![]() 的增加递减,大于1.25后恒为0,该1.25即为m的值,当
的增加递减,大于1.25后恒为0,该1.25即为m的值,当![]() 时,优化会使得
时,优化会使得![]() 向m靠近也就是两个特征向量的距离会变大,当
向m靠近也就是两个特征向量的距离会变大,当![]() 时,该项不再参与优化,可以看作
时,该项不再参与优化,可以看作![]() 已经满足了最小类间差。
已经满足了最小类间差。
接下来就是在keras中实现,先看以下keras中自带的loss定义,源码链接如下:
https://github.com/keras-team/keras/blob/master/keras/losses.py
首先是Loss类:子类会通过call()方法根据y_true和y_pred实现loss的计算,call()方法最后会调用backend中对应的函数计算。
class Loss(object):
"""Loss base class.
To be implemented by subclasses:
* `call()`: Contains the logic for loss calculation using `y_true`, `y_pred`.
因此,自定义loss就可以仿照源码,根据y_true和y_pred调用backend函数进行计算。那么如何获取y_pred并进行计算呢?正常的模型中只需在compile()函数中设定loss,再将x和y_true输入fit函数就可以得到最后的loss,y_pred并没有输出。因此自定义loss的思路是:把y_true当成一个输入,构成多输入模型,把自定义loss的计算写成一个层,作为最后的输出,搭建模型的时候,就只需要将模型的output定义为loss,而compile的时候,直接将loss设置为y_pred(因为模型的输出就是loss,所以y_pred就是loss),无视y_true,训练的时候,y_true随便扔一个符合形状的数组进去就行了。
(上段引用自:https://spaces.ac.cn/archives/4493,该文章写得很清楚也很细致)
具体过程如下例所示:
img_1 = Input((48, 48, 3))
img_2 = Input((48, 48, 3))
label_1 = Input((7,))
label_2 = Input((7,))
inputs = Input((48, 48, 3))
x = Conv2D(16, (3,3), padding='SAME', activation='relu')(inputs)
x = BatchNormalization()(x)
...
x = MaxPooling2D((2,2))(x)
x = Flatten()(x)
x = Dense(256, activation='relu')(x)
...
x = Dropout(0.5)(x)
x = Dense(7, activation='softmax', name='softmax')(x)
model = Model(inputs=inputs, outputs=x)
out_1 = model(img_1)
out_2 = model(img_2)
eudist = Lambda(lambda x: KTF.cast(KTF.sum(KTF.square(x[0]-x[1]), -1, keepdims=True), np.float32))([out_1, out_2])
flag = Lambda(lambda x: KTF.cast(KTF.equal(KTF.ones_like(eudist)*7, KTF.sum(KTF.cast(KTF.equal(x[0], x[1]), np.float32), -1, keepdims=True)), np.float32))([label_1, label_2])
contrast_loss = Lambda(lambda x: KTF.mean(x[0]*x[1] + (1.-x[1])*KTF.square(KTF.maximum(0., 1.5-KTF.sqrt(x[0]))), 0, keepdims=True), name='contrast_loss')([eudist, flag])
model_3 = Model(inputs=[img_1, img_2, label_1, label_2], outputs=[out_1, out_2, contrast_loss], name='s_model')
model_3.compile(optimizer=Adam(0.001), loss=['categorical_crossentropy', 'categorical_crossentropy', lambda y_true, y_pred: y_pred], loss_weights=[0.3, 0.3, 0.4], metrics=['accuracy'])
model_1 = Model(inputs=img_1, outputs=out_1)
model_2 = Model(inputs=img_2, outputs=out_2)
model_1.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
model_2.compile(optimizer=Adam(0.001), loss='categorical_crossentropy', metrics=['accuracy'])
model_3.summary()
先定义一个model输入shape=(48, 48, 3),输出shape=(7,),由于contrastive loss是针对pair data的,两者共享model的参数,因此要再得到一个model,输入是shape相同的两个tensor,于是将img_1, img_2均输入model得到out_1, out_2,也就是上面提到的特征向量,然后通过Lambda层计算向量间距离得到输出eudist(该层输入为[ out_1, out_2 ]),然后根据label_1, label_2判断pair data的标签是否相同也就是要得到上文的Y,该过程也由Lambda实现得到输出flag(该层输入为[ label_1, label_2 ])。至此得到了contrastive loss计算中需要的所有变量,再次通过Lambda层实现得到输出contrast_loss(该层输入为[ eudist, flag ])。然后我们就可以得到最终的模型model_3,该模型输入有四个:[ img_1, img_2, label_1, label_2 ](注意这里把label_1, label_2都变成了输入);输出有三个:[ out_1, out_2, contrast_loss ](注意输出中不仅有预测结果out_1, out_2, 还有计算的contrast_loss,也就是把loss的计算通过几个Lambda层实现后当作网络的输出变量了)。因此model_3进行compile时,有
loss=['categorical_crossentropy', 'categorical_crossentropy', lambda y_true, y_pred: y_pred], loss_weights=[0.3, 0.3, 0.4]
表示该模型最后的loss有三项,前两项对应模型的输出out_1, out_2,计算预测结果的交叉熵,第三项对应模型的最后一个输出也就是contrastive loss,因为输出本身就是我们要得到的contrastive loss,不需要像前两项一样调用keras自带的loss函数进行计算,所以就利用了Lambda函数得到y_pred,y_pred就是model_3的输出中对应的contras_loss。这也就是前面思路中所说的:
把自定义loss的计算写成一个层,作为最后的输出,搭建模型的时候,就只需要将模型的output定义为loss,而compile的时候,直接将loss设置为y_pred,无视y_true。
最后又得到了model_1, model_2并对它们compile,这样是为了训练时能看到它们的accuracy metrics。
最后model进行fit时,要随便设定以下output中的第三项,也就是contrastive loss对应的那个y_true,因为其不参与计算,所以只要传入一个和contrastiv loss形状相同的ndarray即可:
randomv = np.ones((imgs.shape[1], 1))
randomu = np.ones((test_imgs.shape[1], 1))
model_3.fit([imgs[0], imgs[1], labels[0], labels[1]], [labels[0], labels[1], randomv], batch_size=2,
epochs=100, validation_data=([test_imgs[0], test_imgs[1], test_labels[0], test_labels[1]],
[test_labels[0], test_labels[1], randomu]),
verbose=1, shuffle=True, callbacks=callback_lists)以上过程中,我们自定义了loss函数,同时也实现了多输入多输出的模型。