使用python实现excel常用功能
日常办公excel是一大利器,但是如果数据量太大,基本就卡到爷爷奶奶都不认识了,谁也受不了表格天天崩。这时候python必须拥有姓名。
用python来实现excel功能,主要靠两个包:pandas和numpy,用pip安装完之后,来实现下以下常用供能:
-
字符串查找和处理
分列
列中是否包含某项内容
模糊查询
大小写转换 -
表的处理
排序
数据筛选
vlookup
删除重复项
数据透视表 -
数值计算
计算,加总,平均,最大最小值
条件计算
1.准备:数据导入,整理
将用两个表来做示例,一个是”物资采购情况“表,另一个
是”物资采购订单金额“。
首先是加载包,用xlwings把示例数据导入到python中
import pandas as pd
import numpy as np
import xlwings as xw #导入excel数据
app = xw.App(visible=False, add_book=False)
#获取”物资采购情况“
wb = app.books.open('本地地址*******.xlsx')
sht=wb.sheets['示例数据']
df=pd.DataFrame(sht.used_range.value)
#获取采购金额表
wb = app.books.open('本地地址*******.xlsx')
sht=wb.sheets['示例数据']
amount=pd.DataFrame(sht.used_range.value)
df(物资采购情况表)数据导入部分数据如下,列名和数据类型需要做下整理

#整理
df.columns=df.loc[0,:].values#第一行内容调整成列名
df=df.drop(index=0,axis=1)#删除原第0行
df.index=range(df.shape[0])#重排index
df['订单号']=df['订单号'].astype('int')#调整订单号的类型
整理后的结果,变成了比较典型的dataframe样子

同样处理amout表(订单金额)
#和表一同样方式的整理
amount.columns=amount.loc[0,:].values
amount=amount.drop(index=0,axis=1)
amount.index=range(amount.shape[0])
amount['订单号']=amount['订单号'].astype('int')
部分数据效果如下

2.字符串查找和处理
- 分列
举例:将供应商的城市提取出来,并将供应商字段名称更新为不包含城市名
df['供应商'].apply(lambda x:x.split('-'))
apply,将括号内方法应用于某列;
lambda,对该列中的每个元素执行操作;
元素x在此的类型属于str,就可以用str类下的split方法,来实现分割,分割依据”-“,效果如下:

df['城市']=df['供应商'].apply(lambda x:x.split('-')[1])
df['供应商']=df['供应商'].apply(lambda x:x.split('-')[0])
将分列后的内容应用到df中

- 列中是否包含某项内容
举例:“物资类别”中是否有“交流断路器”
df['物资类别'].isin(['交流断路器'])
结果返回布尔值
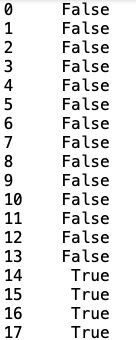
如果连用sum函数,可以得到一个该项目的统计个数
df[‘物资类别’].isin([‘交流断路器’]).sum()
- 模糊查询
举例 “物资类别”中是否有包含“断路器”字符的内容
df['物资类别'].str.contains('断路器')
结果返回布尔值,连用sum函数,可以得到一个该项目的统计个数
df[‘物资类别’].str.contains(‘断路器’).sum()
- 大小写转换
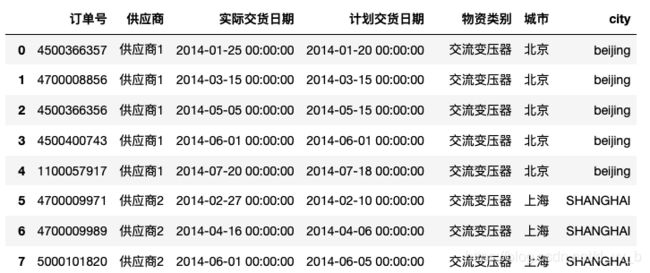
表格处理中常涉及到一些大小写的问题,新加一列”city“举例
df.loc[df[df['城市']=='北京'].index,'city']='beijing'
df.loc[df[df['城市']=='上海'].index,'city']='SHANGHAI'
df.loc[df[df['城市']=='杭州'].index,'city']='hANGZHOU'
增加”city”列内容如图
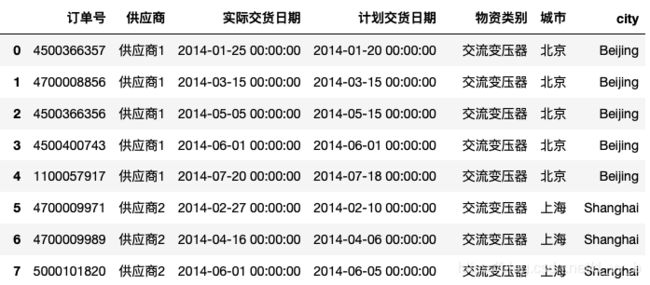
举例:针对列”city“,要转换成首字母大写形式
df['city']=df['city'].str.capitalize()
如果所有内容统一成小写,用str.lower(),全大写str.upper()
df['city'].str.lower()
df['city'].str.upper()
3.表的处理
- 排序
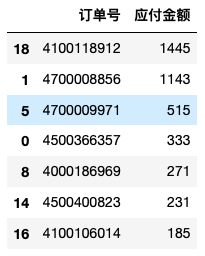
举例:对表amount按”应付金额“按照从大到小,降序排序
amount.sort_values('应付金额',ascending=False)#ascending 默认true升序排列,降序时需要复制false
- 数据筛选
举例:#筛选出应付金额大于300的订单
amount[amount['应付金额']>=300]

如果想获取订单号的值,就用values属性
amount[amount['应付金额']>=300]['订单号'].values
![]()
- vlookup:excel中最常用的相对高级点儿的使用就是vlookup函数,在用pandas的merge功能可以实现
举例:将amount中的应付金额,匹配到表df中
df_amount=df.merge(amount,on='订单号')#pandas的merge功能默认连接方式为inner连接,on后面是连接的依据字段,也就是vlookup中的第一个参数

- 删除重复项
目前表里面没有完全重复项,为了举例先把表加一个重复行
查找重复行
df.loc[20,:]=df.loc[0,:]#添加一行重复内容
df[df.duplicated()]#查看是否有整行内容重复,返回布尔值,df匹配布尔值后,返回重复内容
df.duplicated(subset='订单号')#查看某列是否有元素重复,返回布尔值,subset传入列名

删除重复行
df.drop_duplicates(inplace=True)#删除重复的行,inplace默认false,设定为true后,将在原有df上直接做调整
- 数据透视表
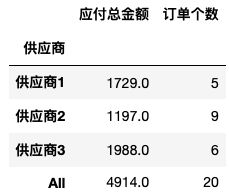
举例:统计每个供应商分别签署的订单数量、订单总金额,最后显示合计数
数据透视表,pandas里有两种方式可以实现,1.groupby,2.pivot_table(),这部分内容很多,之后单独整理下,先简单用pivot做个示例,
用前面合并好的df_amount,先转换下数据类型
df_amount['应付金额']=df_amount['应付金额'].astype('float')
df_amount['订单号']=df_amount['订单号'].astype('int')
用pivot_table()进行透视
total=df_amount.pivot_table(index=['供应商'],values=['订单号','应付金额'],aggfunc={
'订单号':len,'应付金额':np.sum},margins=True)
#aggfunc指得是计算方法,比如sum,mean,len等,里面可以传入一个具体的str,list,或者字典,如果是字典的话,就用{value1:计算1,value2:计算2}这样的方式传入,非常好用
#换个列名
total.columns=['应付总金额', '订单个数']
4.数值计算
- 计算,平均,最大最小值
应付总金额
df_amount['应付金额'].sum()
每单均价
df_amount['应付金额'].mean()
分别找出金额最小、最大的订单
min_order=df_amount['应付金额'].min()#先找出最小订单金额
bool_index=df_amount['应付金额']==min_order#返回应付金额等于最小值的布尔值
df_amount[bool_index]#将布尔值匹配给df_amount,找到金额最小订单

找到金额最大的订单,以上几步写在一条语句中
df_amount[df_amount['应付金额']==df_amount['应付金额'].max()]

- 条件计算
举例:实际在5月份前能交货的”交流变压器“的有多少(总金额)
df_amount['实际交货日期']=pd.to_datetime(df_amount['实际交货日期'])#实际交货日期的type目前还是object,转换成日期格式
a=df_amount['实际交货日期']<pd.datetime(2014,6,1)#条件1:实际交货日期在6月前
b=df_amount['物资类别']=='交流变压器'#条件2:交流变压器
df_amount[a&b]['应付金额'].sum()#条件求和
暂时想到这么多内容,之后想到的话继续补充~