Ubuntu12.04配置Hadoop1.1.2集群
Ubuntu12.04配置Hadoop1.1.2集群
-
背景
ThinkPad T420
Ubuntu 12.04
Vmware Workstation 9.0.0
-
目的
最终要配置一台master,一台secondary namenode,二台slaves的集群环境(暂时先配置二台,后边需要时可以再加的哦)。
对应的机器主机名为:master, backup, hadoop1,hadoop2
-
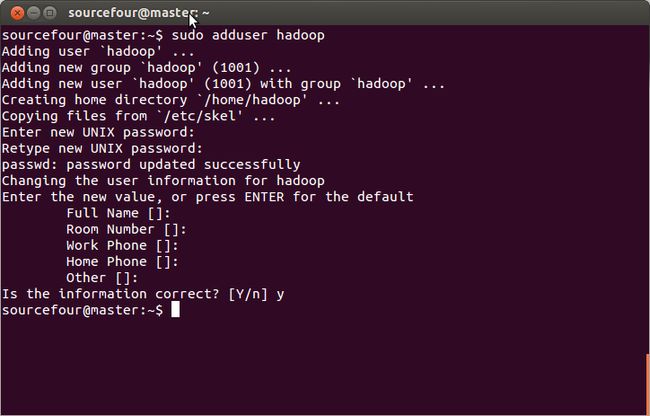
建立Hadoop用户
Hadoop最好运行在一个单独的用户下,且所有集群中的用户应该保持一致,即用户名相同。所以使用命令建立Hadoop用户(我使用的是hadoop,你可以更换哦)
-
解压hadoop1.1.2包
hadoop用户建好用户后,从http://apache.dataguru.cn/hadoop/common/hadoop-1.1.2/下载hadoop-1.1.2.tar.gz。当然,也可以先下载好,然后再传到hadoop用户目录下。我使用的是后者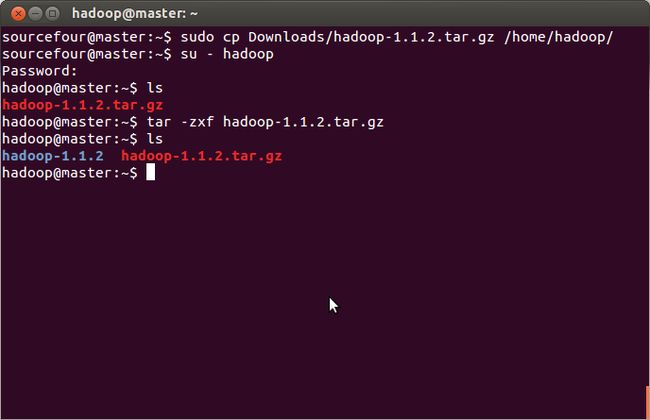
-
配置集群关键文件
我们要配置的集群关键文件有六个:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、masters、slaves
hadoop-env.sh:
修改第9行,注意:一定要修改为你的JAVA_HOME
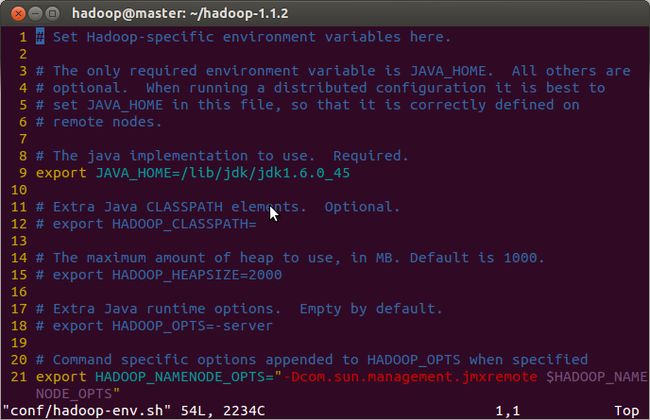
core-site.xml:
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.
hdfs-site.xml:
The actual number of replications can be specified when the file iscreated.
The default is used if replication is not specified in create time.
mapred-site.xml:
at. If "local", then jobs are run in-process as a singlemap
and reduce task.
masters:
backup
slaves:
hadoop1
hadoop2
当然,masters与slaves中的主机名要与/etc/hosts中映射的主机名一致,以下是我的映射
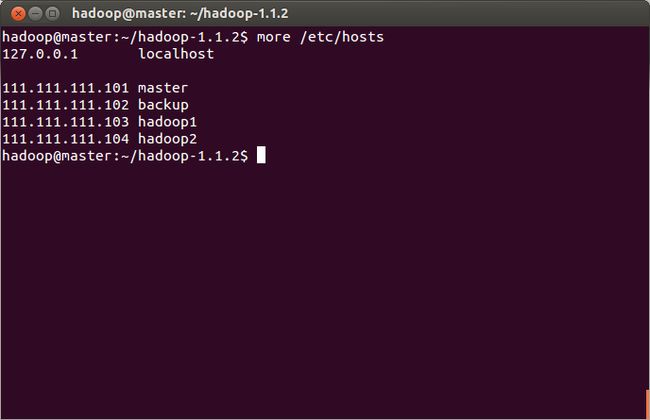
至此hadoop的环境已经配置好了,但是只是一台,接下来我们要安装虚拟机进行集群的后续配置
打通ssh通道
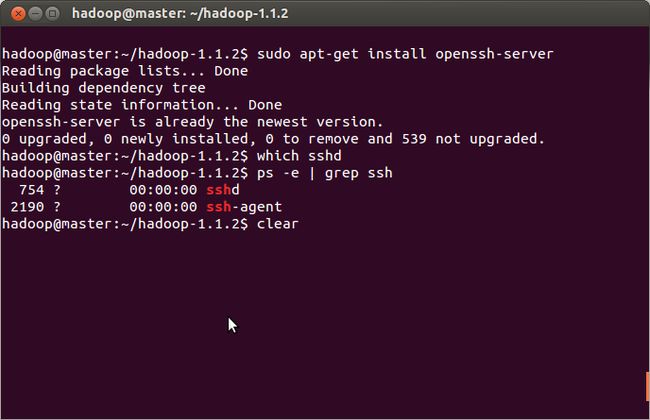
a. 检查ssh 是否已安装,如果没有安装则需要安装

在我这里sshd没有安装,则我需要安装sshd
b. 生成ssh密匙对
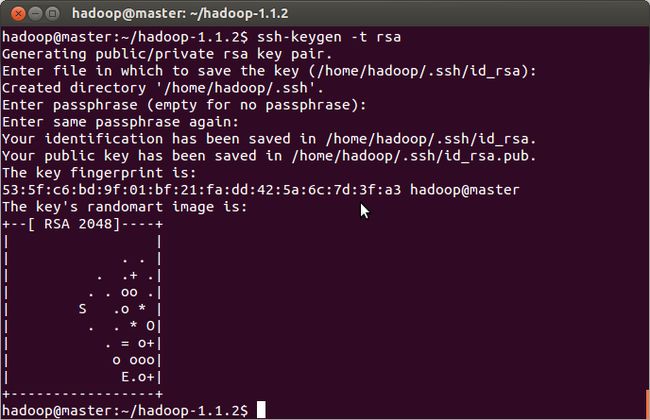
说明:如果每次不想输入passphrase,则一直按回车键即可,否则每次连接时会提示输入passphrase哦
c. 免密码登录
把生成的id_rsa.pub发送到集群中的每台机器上
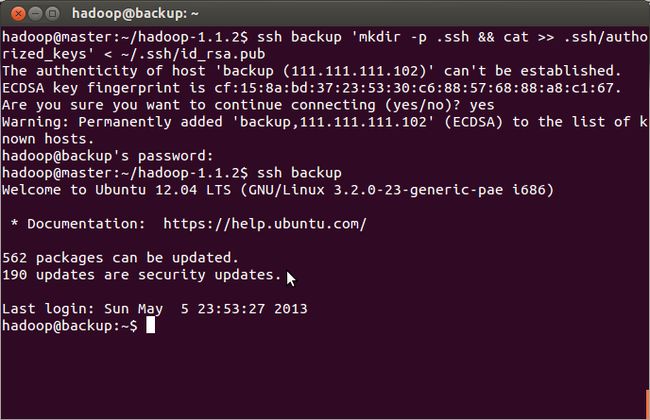
安装第一个虚拟机---backup
至于vmware workstation及Ubuntu12.04在虚拟机里的安装这里就不多说了,但是稍后会说虚拟机的clone。
a. backup安装好后,为了方便我们配置成静态IP(因为在我这里启动虚拟机后IP地址会发生改变),我这里配置成了111.111.111.102。注意:需要将vmware中的Network Adapter设置为桥接(Bridged)方式
b. 安装ssh
具体参看6中的‘打通ssh通道‘
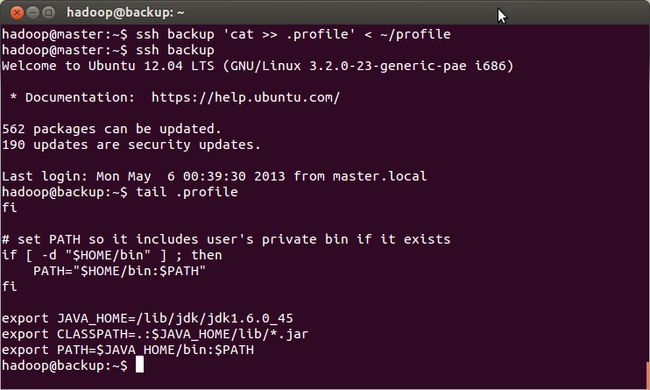
c. 把在master上配置好的jdk6拷贝到刚才安装的虚拟机中

拷贝JAVA_HOME的配置
d. 把在master上配置好的hadoop1.1.2拷贝到刚才安装的虚拟机中
这里就不再赘述了,和上边拷贝jdk 类似,嘎嘎……clone虚拟机
在backup上右键--->Manage--->clone(V_V没有找到一个在Linux下好点的截图软件(好像有个gsnapshort但是无法下载),无法截图,求推荐……),
有两种clone type,选择一种然后一路next即可(当然最后的名字可以修改一下,这样比较好吧。嘎嘎……个人习惯)
启动hadoop集群
在启动之前先format
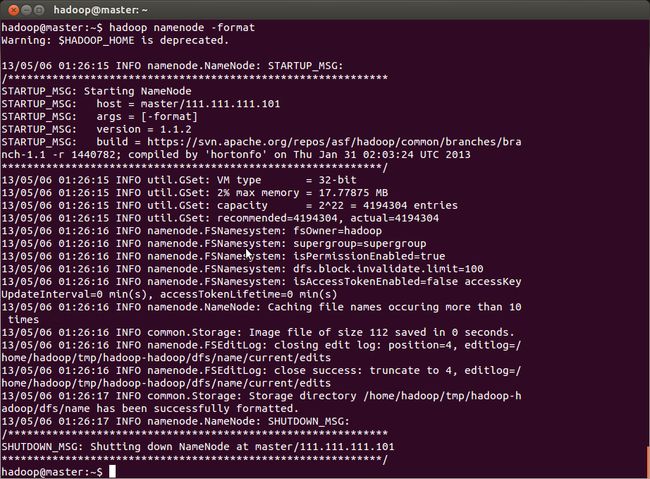
启动集群
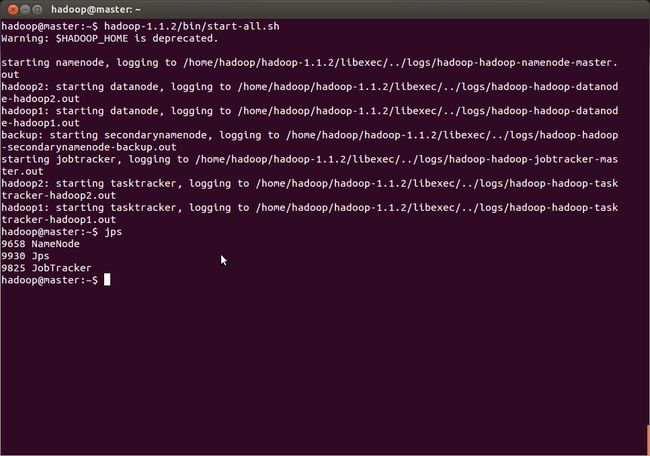
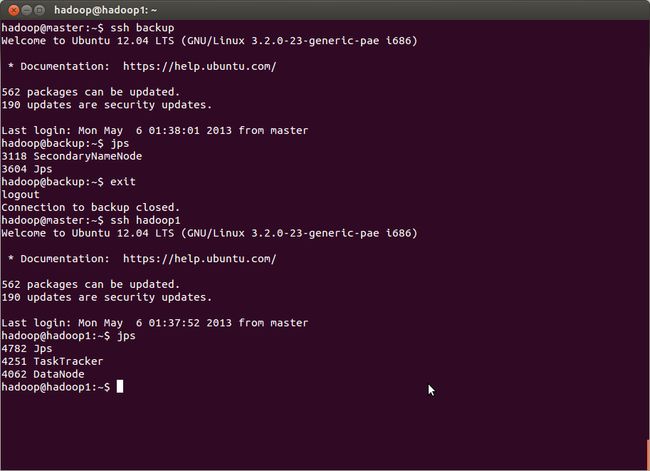
总结:hadoop集群已配置成功,开始咱的hadoop之旅吧。……