- 什么是索引?
索引是为了加速对表中数据行的检索而创建的一种分散储存的数据结构。
工作原理:
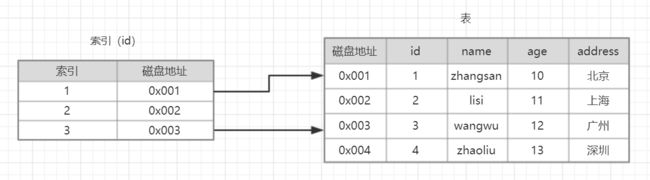
通过我们建立的索引,可以通过命中后的磁盘地址快速的找到我们需要的表数据,比起全表扫描去查询数据,可以大大的提升查找效率。
在关系型数据库中,索引是硬盘级索引。
- 常见的数据结构
1)二叉树
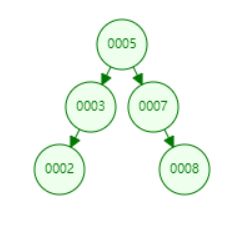
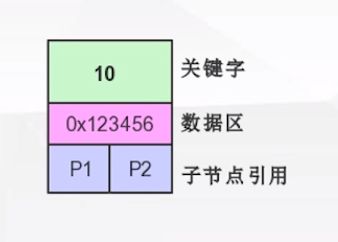
二叉树相信大家都非常熟悉,以一个节点为根节点,比该节点小的值走左边,大的值走右边。搜索数据时,只要通过它的数据链接就可找到相应的数据。右边为一个节点里的具体组成部分。
缺点:二叉树有个极其致命的缺点,当插入数据为顺序递增或顺序递减时,形成的二叉树就成了单边链条。
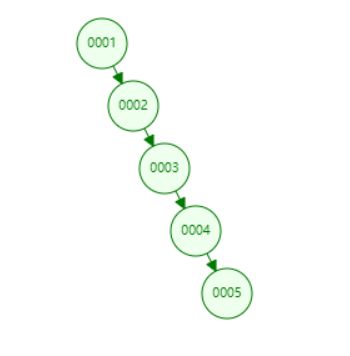
这样的话,查找也没有效率可言。
2)平衡二叉查找树
平衡二叉查找树作为二叉查找树的进阶版,改进了二叉查找树的缺点。
定义:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
即,当平衡二叉查找树数据插入时,如果发现形成的树结构违反了它的定义,那么此时树会发生形变,组成一颗相对平衡的查找树。
如果还是以上面的1-5顺序插入时,形成的树结构为
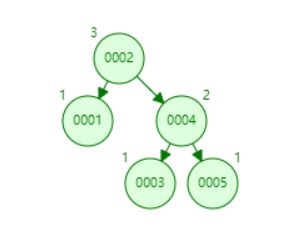
红黑树也是平衡二叉查找树的一种实现。
因此不建议对数据频繁变更的列建立索引,因为在这个过程中,索引的结构变更必然会带来IO流和CPU的损耗。
缺点:
1.搜索效率不足。
因为归根结底还是二叉树结构,因此在数据量大的时候,树的高度极高,也就意味着可能一次查找需要超多次数的IO。
2.节点数据内容太少。
每一个节点中保存的数据远远不够填满一次内存和磁盘交互的值。如果一次内存和磁盘的交互为4KB,那么一个节点中保存的数据其实就大大浪费了这个空间。
3)B tree(多路平衡查找树,绝对平衡)
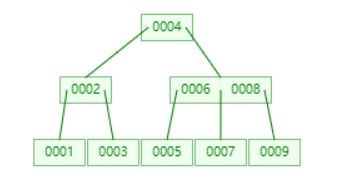
那么B树如何解决平衡二叉树的缺点呢?
上图是一个三路平衡查找树,因为Btree是多路平衡查找树的原因,它可以是三路,四路,五路六路,路越多,就意味着树的高度越低,那么一次搜索的最大IO次数也就越少。
也因为它的多路特性,一次IO交互的磁盘块中可能保存着巨大数量的节点数据。我们以id为int为例,一次IO交互假设为4KB,那么一次IO交互最多能保存1024个关键字!(当然一个节点中有数据区和子节点引用,粗略计算)。
因此我们在设置数据库的字段类型和字段长度的时候,控制字段类型合理,字段长度合理,就能保证每次索引磁盘块的加载能包含更多数据,从而提升我们的查找效率。
4)B+tree(加强版多路绝对平衡查找树)
我们还是以三路查找树为例
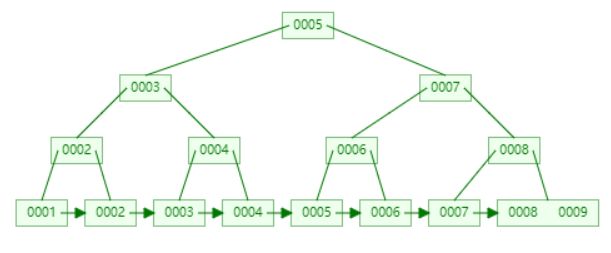
B+树的特点:
- 非叶节点不保存数据相关信息,只保存关键字和子节点的引用。
- 所有的数据都保存的叶子节点中。
- 采用左闭合区间。
- 叶子节点中的数据顺序排列,并且相邻节点具有顺序引用的关系。
B+树相比B树的优点:
- 扫库、扫表能力更强
- 磁盘读写能力更强(因为少保存了个数据区)
- 排序能力更强
- 查找效率更加稳定(B树可能一次命中,也可能多次命中,而B+树因为没有保存数据区的缘故,树的高度相对更低,但每次都要查找到最多次数)
- mysql中B+tree的具体落地形式
- myisam
myisam存储引擎的表会有三个文件
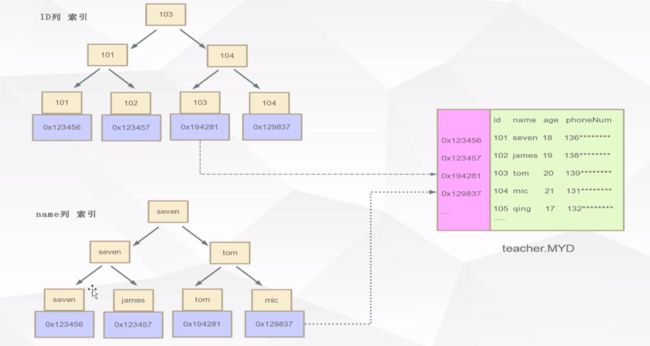
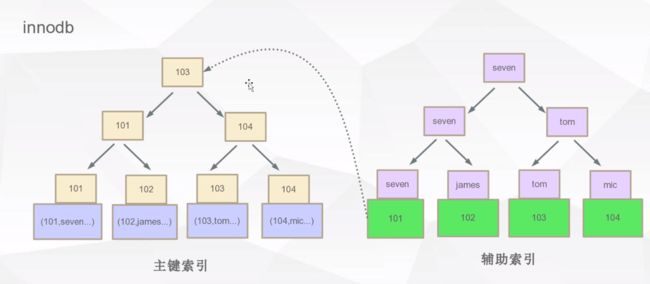
- innodb
innodb存储引擎的表有两个文件
.frm文件储存表定义;
.ibd储存索引和数据。
innodb是一个以主键为索引来组织数据的存储引擎,主键索引形成数据结构,具体的数据值保存在叶子节点,而辅助索引中的叶子节点保存了指向主文件的主键关键字。如果没有指定主键,innodb会生成隐藏的6位自增列rowid。
- 索引的几大原则
- 最左匹配原则
对索引中关键字进行计算和比对,一定是从左往右一次执行,且不可跳过。
- 高离散度原则
列中的数据重复率越低,离散度越好。
- 最少空间原则
索引的创建原则为 最左匹配 > 高离散度 > 最少空间。
- 联合索引和覆盖索引
- 联合索引
单列索引是特殊的联合索引,如果建立的联合索引中包含了单列索引及小于该范围的联合索引,要注意索引的冗余。(例如:index[id,name]>index[name])
-
- 覆盖索引
如果查询的列,通过索引项的信息可以直接返回,则该索引为覆盖索引。
例:table(teacher)index(id)
sql:select id from teacher where id = ?