python sklearn学习笔记大全(常见代码速查)
skleran是python中常见的机器学习包,整理下笔记。方便查询。
官方文档链接:sklearn官方英文文档
常见模型
from sklearn.linear_model import LinearRegression#线性回归
lr=LinearRegression(normalize=True)
#SVC,SVR
from sklearn.svm import SVC,SVR
svc=SVC(kernel='linear')
#贝叶斯
from sklearn.naive_bayes import GaussianNB
gnb=GaussianNB()
#KNN
from sklearn.neighbors import KNeighborsClassifier
knn=KNeighborsClassifier(n_neighbors=2)
#无监督模型
from sklearn.decomposition import PCA
pca=PCA(n_components=0.95)
from sklearn.cluster import KMeans
k_means=KMeans(n_clusters=6,random_state=1)
模型训练
lr.fit(x,y)
k_means.fit(x,y)
pca.fit_transform(x,y)
模型预测
y_pred=lr.predict(x_test)
y_pred=knn.predict_proba(x_test)
评价函数
分类
准确率
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
0.5
accuracy_score(y_true, y_pred, normalize=False)
2
混淆矩阵
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)
array([[2, 0, 0],
[0, 0, 1],
[1, 0, 2]])
分类报告
classification_report函数构建了一个文本报告,用于展示主要的分类metrics。 下例给出了一个小示例,它使用定制的target_names和对应的label:
>>> from sklearn.metrics import classification_report
>>> y_true = [0, 1, 2, 2, 0]
>>> y_pred = [0, 0, 2, 2, 0]
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class 2 1.00 1.00 1.00 2
avg / total 0.67 0.80 0.72 5
回归
from sklearn.metrics import mean_squared_error#简称MSE,即均方误差
from sklearn.metrics import median_absolute_error#abs(y_pred-y_test)
from sklearn.metrics import mean_squared_log_error
from sklearn.metrics import mean_absolute_error#(MAE)
from sklearn.metrics import r2_score
聚类
- 轮廓系数(Silhouette Coefficient)
函数:
def silhouette_score(X, labels, metric=‘euclidean’, sample_size=None,
random_state=None, **kwds):
函数值说明:
所有样本的s i 的均值称为聚类结果的轮廓系数,定义为S,是该聚类是否合理、有效的度量。聚类结果的轮廓系数的取值在【-1,1】之间,值越大,说明同类样本相距约近,不同样本相距越远,则聚类效果越好。
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.silhouette_score(X, labels, metric='euclidean')
...
0.55...
- CH分数(Calinski Harabasz Score )
函数:
def calinski_harabasz_score(X, labels):
函数值说明:
类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。 总结起来一句话:CH index的数值越大越好。
>>> import numpy as np
>>> from sklearn.cluster import KMeans
>>> kmeans_model = KMeans(n_clusters=3, random_state=1).fit(X)
>>> labels = kmeans_model.labels_
>>> metrics.calinski_harabaz_score(X, labels)
560.39...
交叉验证
将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。K一般大于等于2,实际操作时一般从3开始取,只有在原始数据集合数据量小的时候才会尝试取2。K-CV可以有效的避免过学习以及欠学习状态的发生,最后得到的结果也比较具有说服性。
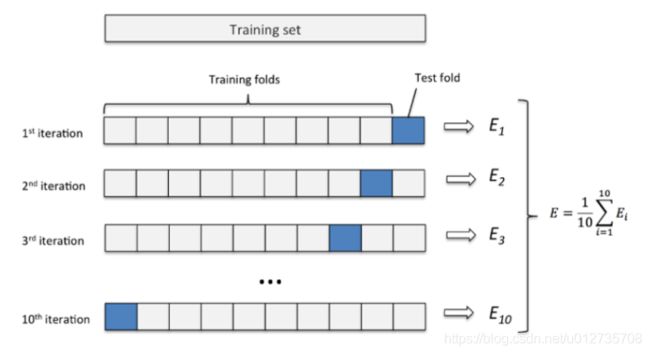
from sklearn.model_selection import cross_val_score
from sklearn import datasets
data=datasets.load_iris()
X=data.data
y=data.target
knn = KNeighborsClassifier(n_neighbors=5)
score = cross_val_score(knn,X,y,cv=5,scoring='accuracy')
print(score)
print(score.mean())
网格搜索
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。
grid.fit():运行网格搜索
best_params_:描述了已取得最佳结果的参数的组合
best_score_:成员提供优化过程期间观察到的最好的评分
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
iris = load_iris()
X = iris.data
y = iris.target
k_range = range(1,31)
weights = ['uniform', 'distance']
#
param_gird = dict(n_neighbors=k_range,weights=weights)
knn = KNeighborsClassifier(n_neighbors=5)#现在是一个参数进行网格搜索
grid = GridSearchCV(knn,param_gird,cv=10,scoring='accuracy')
grid.fit(X,y)
print(grid.best_score_)
print(grid.best_params_)

归一化和标准化
归一化
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
data = mm.fit_transform(shuju )
print(data)
mm.transform(X_test)
mm.inverse_transform()#还原
标准化
from sklearn.preprocessing import StandardScaler
std = StandardScaler()
方法同归一化
标签编码
第一步:先对离散的数字、离散的文本、离散的类别进行编号,使用 LabelEncoder,LabelEncoder会根据取值的种类进行标注。
import sklearn.preprocessing as pre_processing
import numpy as np
label=pre_processing.LabelEncoder()
labels=label.fit_transform(['中国','美国','法国','德国'])
print(labels)
labels的结果为:[0,3,2,1]
第二步:然后进行独热编码,使用OneHotEncoder
labels=np.array(labels).reshape(len(labels),1) #先将X组织成(sample,feature)的格式
onehot=pre_processing.OneHotEncoder()
onehot_label=onehot.fit_transform(labels)
print(onehot_label.toarray()) #这里一定要进行toarray()
结果为:
[[1. 0. 0. 0.]
[0. 0. 0. 1.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]]
注意,上面的第二步也可以使用LabelBinarizer进行替代
onehot_label=pre_processing.LabelBinarizer().fit_transform(labels)
这里的参数labels就是【0,3,2,1】,不需要组织成(samples,features)的形式。
多项式特征
from sklearn.preprocessing import PolynomialFeatures
# include polynomials up to x ** 10:
poly = PolynomialFeatures(degree=10)
poly.fit(X)
X_poly = poly.transform(X)
![]()
电气专业的计算机萌新:余登武。写博文不容易。如果你觉得本文对你有用,请点个赞支持下,谢谢。
![]()