Hadoop伪分布式安装和wordcount实例
Hadoop伪分布式安装
- 一、用rpm安装jdk
- 二、查询.ssh文件
- 三、设置免密
- 四、安装Hadoop
- 五、Hadoop配置文件信息
- 六、格式化HDFS
- 七、启动集群
- 八、在windows环境看Hadoop集群
- 九、关闭集群
- 十、wordcount实例
前期准备:一台虚拟机
首先将
Xshell和Xftp连接虚拟机,可根据点击这个链接学习https://blog.csdn.net/Dlychee/article/details/106756519
注:按“i”编辑文件,编辑完内容后,按“Esc”键,然后输入“:wq”为保存编辑内容并退出,输入“:q!”为不保存编辑内容并退出。
一、用rpm安装jdk
这里给一个jdk-7u67-linux-x64.rpm
网盘链接: https://pan.baidu.com/s/1cwuoJLPcclQEKwJSqaNMIQ
提取码:688f
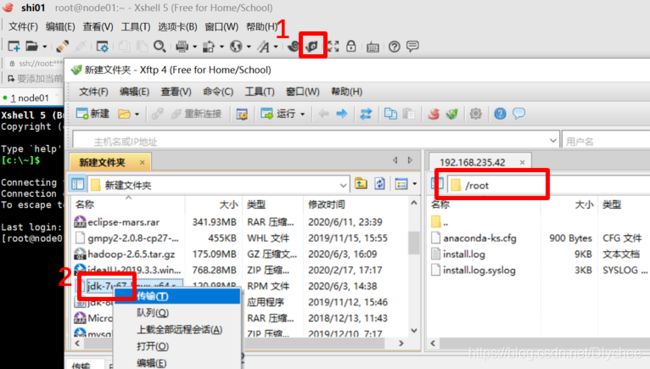
1.jdk.rpm文件传输 (rpm相当于Windows的exe文件)
(
右边部分为虚拟机中root目录下)
首先,单击“新建文件传输”。然后,在左边部分找到在Windows下jdk-7u67-linux-x64.rpm文件,右键,单击“传输”。
2.输入命令
rpm -i jdk-7u67-linux-x64.rpm

3.查询jdk安装路径
whereis java
![]()
4.配置全局环境变量
(1)进入profile中进行编辑的命令,“vi + 文件路径”表示打开文件,并将光标置于最后一行首 。
vi + /etc/profile
按“i”编辑文件,编辑完内容后,按“Esc”键,然后输入“:wq”为保存编辑内容并退出,输入“:q!”为不保存编辑内容并退出。(后面将不再重复此知识点。)
(2)在它最后插入:
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:$JAVA_HOME/bin
![]()
5.使环境变量生效(每次修改过/etc/profile文件后记得一定要source一下)
source /etc/profile
6.输入命令jps,如果出现-bash: jps: command not found
![]()
(1)此时更改环境变量,输入命令:
vi + /etc/profile
(2)更改刚刚前面输入的内容:
export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
(3)使环境变量生效
source /etc/profile
(4)再次输入命令jps,查看是否出现Jps

二、查询.ssh文件
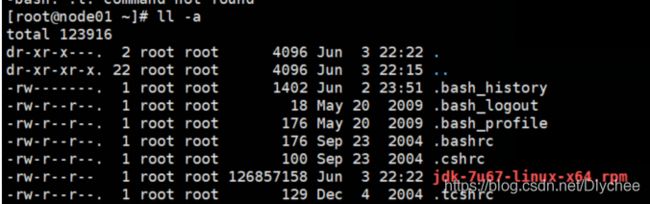
1.输入命令 ll -a ,看是否有 .ssh 文件
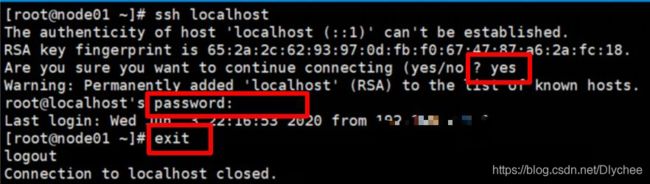
2.如果没有则输入命令 ssh localhost
遇到问(yes/no)输入 yes ,遇到password输入你的 密码 。登录完后记得最后要退出登录,输入命令 exit
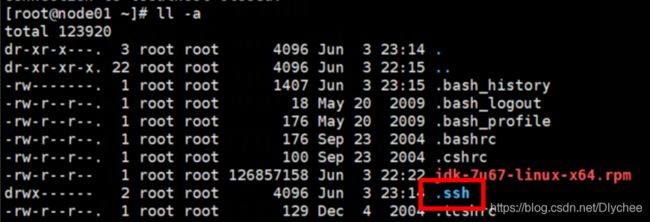
3.再次输入命令 ll -a,看 .ssh 文件是否出现。
三、设置免密
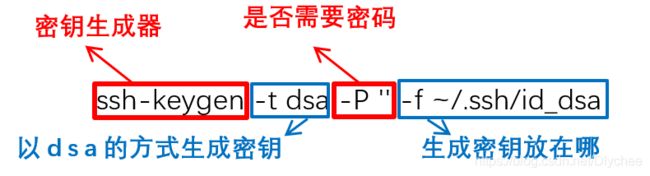
1.输入命令:(P为大写)
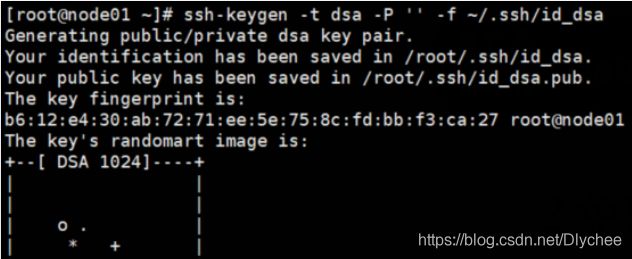
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
2.把id_dsa.pub追加到authorized_keys。
输入命令:
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
3.免密验证(此次ssh localhost不需要输入密码)
(1)输入命令 ssh localhost,记得要退出登录 exit
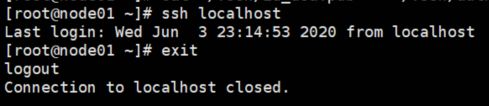
(2)输入命令 ssh node01,记得要退出登录 exit

四、安装Hadoop
提供一个绿色版本hadoop-2.6.5,解压就能用。
网盘链接: https://pan.baidu.com/s/1tPnm0hhr0w3yGFNX1nBJwg
提取码:zbqq
1.首先,我们要在虚拟机主目录下建立一个新的目录用来等下来存放hadoop的压缩包,这里我取的文件名是software
到主目录的命令为 cd ~
新建目录的命令为 mkdir 文件名

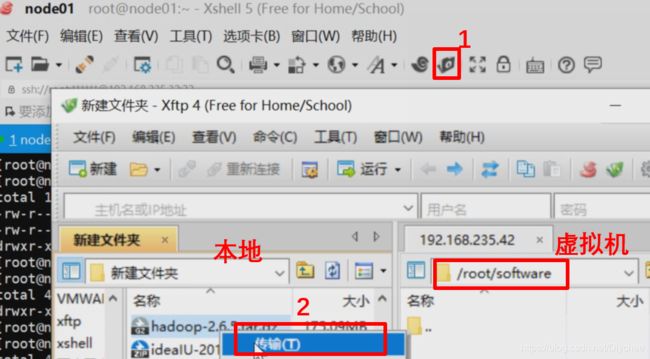
2.将Windows中hadoop压缩包传到虚拟机node01中。
单击“新建文件传输”图标,右边虚拟机进入刚刚创建的software目录中,在Windows(即本地)中找到存放hadoop-2.6.5的压缩包,右键,选择“传输”。
3.到opt目录下(该本身就存在,不需要我们创建),创建一个新的目录用来等下存放hadoop解压后的文件.这里我取的目录名为lychee,大家可以用自己的名字命名(例如:陈芊芊→cyy)
到opt目录下命令为 cd /opt
新建目录的命令为 mkdir 文件名

4.解压hadoop压缩包。
(1)首先到存放hadoop压缩包的目录(software)下。
cd /root/software
![]()
(2)将 hadoop压缩包 解压到 lychee 目录(刚刚以自己名字命名的目录)下。
(注:C为大写)
tar xf hadoop-2.6.5.tar.gz -C /opt/lychee
![]()
(3)这个时候我们在 lychee 目录下输入命令 ll 就能看到已经解压好的hadoop。

5.想要在任意目录下启动Hadoop,我们需要在配置文件profile中做一些修改。
(1)进入profile中进行编辑的命令,“vi + 文件路径”表示打开文件,并将光标置于最后一行首 。
vi + /etc/profile
(2)对它进行配置,配置成功后保存并退出。配置内容如下:
export JAVA_HOME=/usr/java/bin
export HADOOP_HOME=/opt/自己的文件名/hadoop-2.6.5
export PATH=$PATH:usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
 (3)修改过/etc/profile文件后,不要忘了
(3)修改过/etc/profile文件后,不要忘了source一下
source /etc/profile
6.输入hd后,按Tab键可以出现hdfs 和 输入start-d后,按Tab键可以出现start-dfs. 就表示成功了。
五、Hadoop配置文件信息
配置文件信息要仔细!!!!要不然后续很容易出错!!
有时候在敲当前目录下文件名的时候可以按
Tab键,它会自动帮你补全文件名
1.首先到hadoop目录下:
cd /opt/lychee/hadoop-2.6.5/etc/hadoop
然后,我们 ll 一下,会看到很多配置文件。
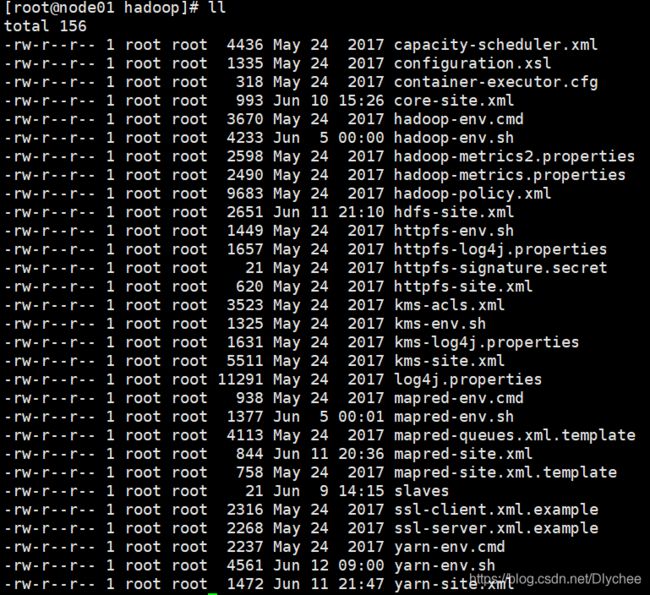
2.配置hadoop-env.sh文件
vi hadoop-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。

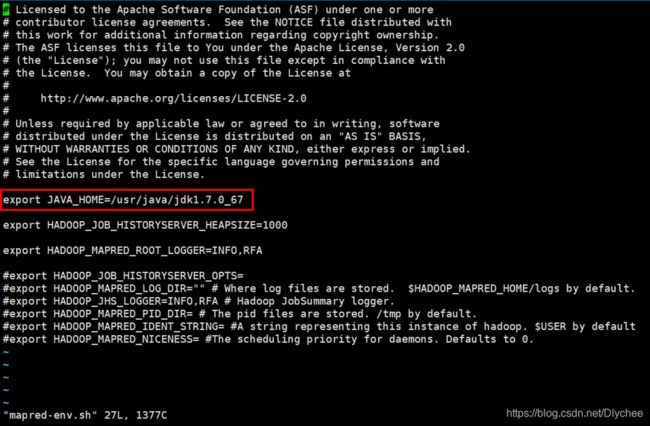
3.配置mapred-env.sh文件
vi mapred-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。(注:这里export JAVA_HOME这句开头有一个 注释号 #,我们需要把这个#删掉。)
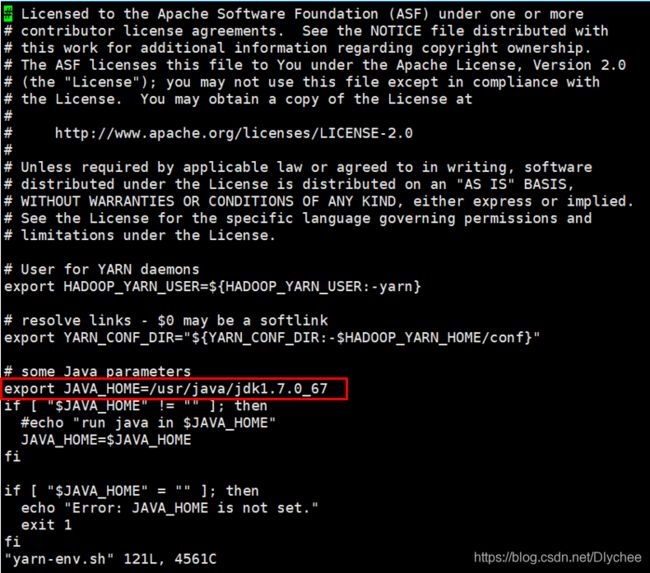
4.配置yarn-env.sh文件
vi yarn-env.sh
给它的JAVA_HOME更改成绝对路径/usr/java/jdk1.7.0_67,并且保存退出。(注:这里export JAVA_HOME这句开头也有一个 注释号 #,我们需要把这个#删掉。)
5.配置core-site.xml文件
vi core-site.xml
在
fs.defaultFS
hdfs://node01:9000
hadoop.tmp.dir
/var/lychee/hadoop/pseudo
NameNode的元数据信息和DateNode数据文件本来默认保存在一个临时tmp文件里,这样不安全,所以更改它的Hadoop的临时目录

6.配置hdfs-site.xml文件
vi hdfs-site.xml
在
dfs.replication
1
dfs.namenode.secondary.http-address
node01:50090

7.配置slaves文件
vi slaves
在里面删除原有的 localhost ,添加当前虚拟机的主机名,我的是node01。然后保存并退出。这里我们配置的是(DateNode节点)

六、格式化HDFS
1.首先我们到刚刚配置core-site.xml文件中指定的Hadoop临时目录
cd /var/lychee/hadoop/pseudo
看是否显示这个文件不存在
-bash: /var/lychee/hadoop/pseudo: pp: No such file or directory
2.这个文件不存在,所以我们现在要格式化一下HDFS。搭一次集群最好只格式化一次,多次格式化会使集群号会改变。
hdfs namenode -format
如果显示如下就证明你格式化成功了,出现has been successfully formatted。
 3.这个时候我们再输入命令
3.这个时候我们再输入命令 cd /var/lychee/hadoop/pseudo 检查一下它是否存在。
七、启动集群
1.首先到根目录下(cd ~或cd),然后输入命令
start-dfs.sh
2.再输入命令jps,看是否出现了:NameNode , SecondaryNameNode , DateNode,出现了则证明成功了。
jps

3.如果NameNode , SecondaryNameNode , DateNode其中有一个没成功,我们可以在logs中查找错误。
cd /opt/lychee/hadoop-2.6.5/logs
然后ll一下,找到其中没有成功的Node的.log文件,查看错误出在哪。
例如:datenode没有出现,就输入一下命令 tail查询hadoop-root-datanode-node01.log文件的最后100行。
tail -100 hadoop-root-datanode-node01.log

八、在windows环境看Hadoop集群
在集群启动的情况下,我们在浏览器(不要用360浏览器,这里我用火狐)中搜索 你的主机名:50070,这里我搜的是node01:50070
如果红框内显示active则成功,如果显示找不到该网页等消息,点此链接查看Windows和虚拟机之间的访问步骤中Windows内的hosts是否配置成功。

九、关闭集群
在虚拟机中输入
stop-dfs.sh

十、wordcount实例
wordcount是数一篇文章里每个单词出现的次数。
做这个实例的时候我们要在虚拟机里启动集群start-dfs.sh
1.这里首先我们在Windows内准备一个有内容的.txt文件夹,这里我给它命名为500miles。
(1)利用Xshell和Xftp将它传输给虚拟机内你要存放的路径中,这里我存放在根目录root下。

(2)我们可以到存放的目录下,ll一下,会发现你存的500miles.txt。

2.在HDFS中创建输入目录和输出目录。
(1)创建输入目录命令(就是把我们要wordcount那个文件里的东西放入其中)
hdfs dfs -mkdir -p /data/input
![]()
(2)创建输出目录命令(就是把wordcount的结果放入其中)
hdfs dfs -mkdir -p /data/output
![]()
(3)在Windows环境下,用浏览器搜node01:50070。按照下图步骤来,如果出现input和output目录则证明创建成功。

3.将要统计数据的文件上传到输入目录并查看
(1)将要统计数据的文件上传到输入目录
hdfs dfs -put 要统计数据的文件名 /data/input
例如:
hdfs dfs -put 500miles.txt /data/input
![]()
(2)在浏览器中刷新并查看500miles文件是否存在。

也可以在虚拟机用命令查看
hdfs dfs -ls /data/input

4.进入MapReduce目录(对大数据进行计算)
cd /opt/lychee/hadoop-2.6.5/share/hadoop/mapreduce
 然后我们
然后我们 ll一下,可以看到其中有一个样例jar包hadoop-mapreduce-examples-2.6.5.jar。

5.运行wordcount。
输入命令:
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/input /data/output/result

6.查看运行结果
(1)查看result目录下生成的文件。
hdfs dfs -ls /data/output/result
SUCCESS放的是成功与否的信息。

(2)查看part-r-00000里面的信息。
-cat查看文件的命令
ls查看目录的命令
hdfs dfs -cat /data/output/result/part-r-00000
我们就可以看见每个单词出现的次数。

7.最后关闭集群
stop-dfs.sh