windows下python3.6+pycharm+spark2.3+jdk1.8+hadoop2.7环境搭建
最近要做日志分析 所以想搭建spark环境 但是又觉得双系统有点麻烦 而且文件量不大 所以就用了windows系统。
在网上看了很多博客 有篇博客介绍说spark不支持python3.6 但是我发现搭建以后测试程序也成功运行了 所以写出来跟大家分享一下。
把错误写在前头:我一开始用的jdk1.7,在控制台输入pyspark的时候一直报版本不匹配的错误,后来我换成了jdk1.8就好了。
下载jdk1.8的时候,官网上一直下载不了,我就找到了一个百度网盘的资源下载了。
1.下载spark
网址:http://spark.apache.org/downloads.html
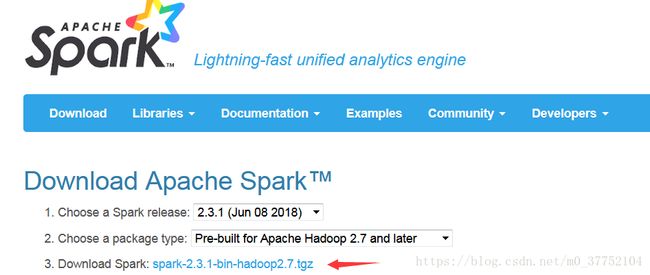
直接点击下载即可。Hadoop2.7就是需要的hadoop版本。
2.下载hadoop
网址:http://hadoop.apache.org/releases.html#Download
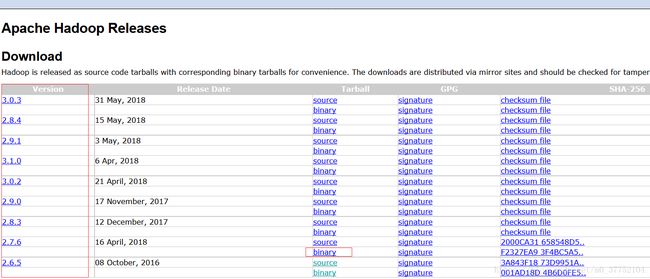
左侧是版本,选择2.7.6,点击对应的binary进入下载页面。

直接点击下载即可。
3.python与pycharm下载
这些都是我之前弄好的,所以就不赘述了。这一步请直接将python的环境变量配置好。不过有一点要注意的是:安装python的时候不可以自定义安装,会出错。
4.解压spark和hadoop
我下载的spark和hadoop都是免安装的,所以直接解压即可。
5.配置环境变量

在系统变量的path里,分别添加spark和hadoop bin目录的安装路径。

接着 在系统变量下新建一个HADOOP_HOME,添加变量值为hadoop bin目录的安装路径。
注意:HOME目录后面是没有分号的,PATH目录后面是有分号的。
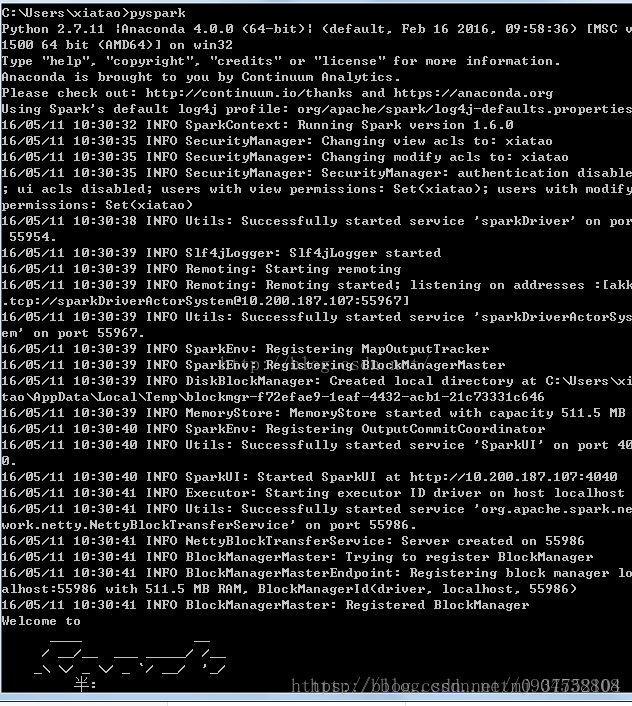
6.在cmd运行pyspark
以管理员身份打开cmd,输入pyspark
正常页面是(引用了别的博客的图片)
但是我的有点问题:

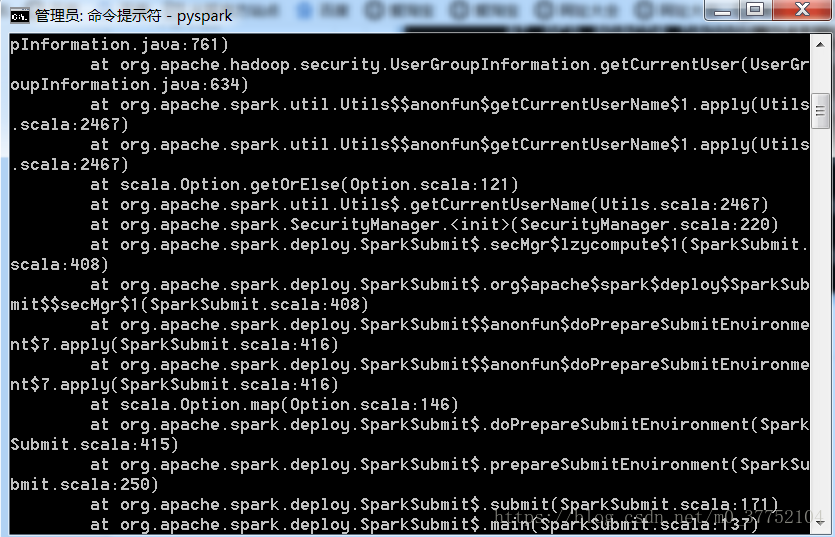

我试了网上说的改环境变量然后重启电脑,不管用。
但最后还是成功显示了python的>>>,所以我就没管。
7.配置pycharm

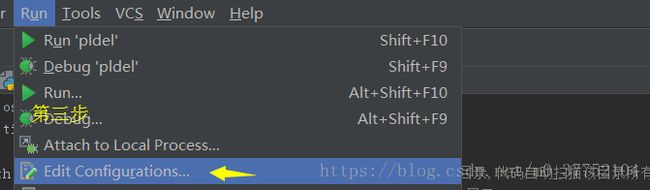

点击工程first->点击run->点击Edit Configurations->->点击Environment variables->点击+号->添加三个name为PYTHONPATH,SPARK_HOME,HADOOP_HOME->PYTHONPATH为spark和hadoop bin目录的安装路径->SPARK_HOME为spark bin目录下的安装路径->HADOOP_HOME为hadoop bin目录下的安装路径。
8.安装pyspark和py4j
我直接在控制台输入匹配 install pyspark和pip install py4j下载的。
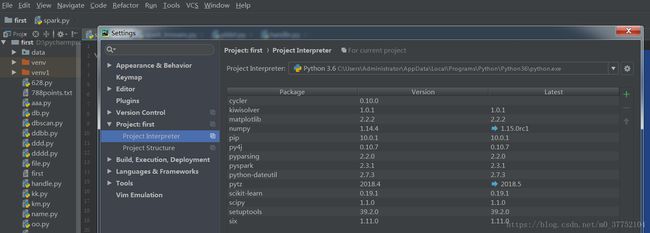
进入pycharm 点击file->settings->project:first(first是我的工程名)->project interpreter查看是否安装成功!
9.测试程序
from pyspark import SparkContext sc = SparkContext('local') doc = sc.parallelize([['a','b','c'],['b','d','d']]) words = doc.flatMap(lambda d:d).distinct().collect() word_dict = {w:i for w,i in zip(words,range(len(words)))} word_dict_b = sc.broadcast(word_dict) def wordCountPerDoc(d): dict={} wd = word_dict_b.value for w in d: #if dict.has_key(wd[w]): if wd[w] in dict: dict[wd[w]] +=1 else: dict[wd[w]] = 1 return dict print(doc.map(wordCountPerDoc).collect()) print("successful!")
运行结果:
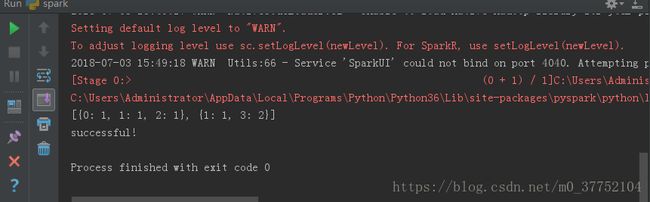
显示成功运行!
第一次配置spark,如果大家从这过程中看出了什么问题,希望及时告诉我哦!