matlab安装gpu:matlabR2018b+cuda9.1+cudnn v4+matcovnet1.24踩坑实录
先说结论:本文一开始是用cuda9.1搭配cudnn7.1.3的,后来因为报错改成了cudnn v4
所以各个版本就如题中所述。
安装cuda9.1和下载cudnn本文略过,
在编译好mex之后,运行C++编译器,出现如下:


下面安装gpu
个人觉得方便,单独将下面的代码用一个文件夹compile_gpu.m存起来,cd到matcovnet的matlab目录下,运行compile_gpu.m
addpath('matlab');
vl_compilenn('enableGpu', true, ...
'cudaRoot', 'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.1',...%你的cuda安装绝对路径
'cudaMethod','nvcc','enableCudnn','true',...
'cudnnRoot','D:\Downloads\cuda9.1_and_cudnn7.1\cudnnv4');%你的cudnn绝对路径
%(这里是我踩坑后才安装v4版本的,所以下面的bug有的是因为我用了7.1.3版本的cudnn而出现的)
接下来是各种debug
**问题1:**C:/Users/liwang/Downloads/matconvnet_cpu/matlab/src/bits/impl/pooling_gpu.cu(163)
编译cuda源程序时出错 error: function “atomicAdd(double *, double)” has already been defined
即:在上述路径中的,163行发生错误。
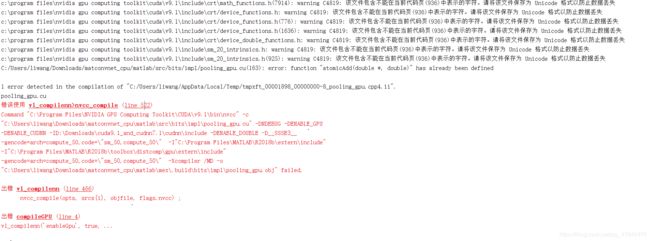
答:这是因为cuda提供了对atomicAdd的定义,但atomicAdd在之前的cuda toolkit中并未出现,因此一些程序自定义了atomicAdd函数。,在atomicAdd前添宏判断即可。
打开出错位置的c文件(上述),找到定义atomicAdd的位置,在atomicAdd前添加宏判断。
#if !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
__device__ double atomicAdd(double* a, double b)
{
return b;
}
#endif
重新运行compile_gpu.m,依然在这里报错

答:原因是复制过来的代码 空格问题
包括中间的空格,有部分空格字符属于汉字空格。这时只需要将所有空格替换成英文空格即可。这种问题比较隐蔽,继续修改,此问题结
问题2:
继续运行,下一个问题:
too few arguments in function call

在该博客中有解释:https://www.cnblogs.com/qq552048250/p/7857122.html
答:老版本的MatConvNet在编译对cuDNN支持的时候,cuDNN的版本是2或者4比较好,官网有明确的描述。
尝试:下载cudnn v4(将它复制到matcovnet的文件夹(前文中建的cudnn文件夹))
**问题3:
更改cuDNN为4.0版本后,编译nnbilinearsampler_cudnn.cu出现以下错误:
nnbilinearsampler_cudnn.cu(24) : fatal error C1021: 无效的预处理器命令“warning”
答:解决办法是直接注释掉第24行,即可
**问题4:**matlab\mex\vl_nnconv.mexw64’compiled with ‘-R2018a’ and linked with ‘-R2017b’.

我在github上面找到了该问题的讨论
(https://github.com/vlfeat/matconvnet/issues/1143)
%将vl_compilenn.m行426,434,440(或者附近行,因为可能会不在指定行)
%中的{-largeArrayDims} 改为 {-lmwblas}
%然后将代码开头的设置变成以下
opts.enableGpu = true;
opts.enableImreadJpeg = false;
opts.enableCudnn = true;
opts.enableDouble = true;
opts.imageLibrary = [] ;
opts.imageLibraryCompileFlags = {} ;
opts.imageLibraryLinkFlags = [] ;
opts.verbose = 0;
opts.debug = false;
opts.cudaMethod = ['nvcc'] ;
成功之后,可以再命令行窗口输入vl_testnn(‘gpu’,true)命令,测试以下GPU的性能。