ByteBuf和相关辅助类
1、ByteBuf功能说明
ByteBuffer的缺点
1)ByteBuffer长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的POJO对象大于ByteBuf的容量时,会发生索引越界异常
2)ByteBuffer只有一个标志位置的指针position,读写的时候需要手工平调用flip()和rewind()等,使用者必须小心谨慎地处理这些API,否则容易导致程序处理失败;
3)ByteBuffer的API功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
2、ByteBuf的工作原理
ByteBuf依然是一个Byte数组的缓冲区,它的基本功能应该与JDK的ByteBuffer一致,提供以下几类基本功能:
- 7种Java基本类型、byte数组、ByteBuffer等的读写;
- 缓冲区自身的copy和slice等;
- 设置网络字节序;
- 构造缓冲区实例;
- 操作位置指针等方法。
ByteBuf通过两个位置指针来协助缓冲区的读写操作,读操作使用readerIndex,写操作使用writerIndex。
readerIndex和writerIndex的取值一开始都是0,随着数据的写入,writerIndex会增加,读取数据会使readerIndex增加,但是它不会超过writerIndex。在读取之后0~readerIndex就被视为discard的,调用discardReadBytes方法,可以释放这部分空间,它的作用类似ByteBuffer的compact方法。readerIndex和writerIndex之间的数据是可读取的,等价于ByteBuffer positoion和limit之间的数据。writerIndex和capacity之间的空间是可写的,等价于ByteBuffer limit和capacity之间的可用空间。
由于写操作不修改readerIndex指针,读操作不修改writerIndex指针,因此读写之间不需要调整位置指针,这极大地简化勒缓冲区的读写操作,避免勒由于一类或者不熟悉flip()操作导致的功能异常。
下面继续分析ByteBuf是如何实现动态扩展的。通常情况下,当我们对ByteBuffer进行put操作的时候,如果缓冲区剩余可写空间不够,就会发生BufferOverflowException异常。为了避免发生这个问题,通常在进行put操作的时候会对剩余可用空间进行校验。如果剩余空间不足,需要重新创建一个新的ByteBuffer,并将之前的ByteBuffer复制到新创建的ByteBuffer中,最后释放老的ByteBuffer,
为了防止ByteBuffer溢出,每进行一次put操作,都需要对可用空间进行校验,这导致代码冗余,稍有不慎,就可能引入其他问题。为了解决这个问题,ByteBuf对write操作进行勒封装,由ButeBuf的write操作负责进行剩余可用该空间的校验。如果可用缓冲区不足,ByteBuf会自动进行动态扩展。

当进行write操作时,会对需要write的字节进行校验。如果可写的字节数小于需要写入的字节数,并且需要写入的字节数小于可写的最大字节数。就对缓冲区进行动态扩展。由于NIO的Channel读写的参数都是ByteBuffer,因此,Netty的ByteBuf接口必须提供API,以方便地将ByteBuf转换成ByteBuffer,或者将ByteBuffer包装成ByteBuf。考虑到性能,应该尽量避免缓冲区的复制,内部实现的时候可以考虑聚合一个ByteBuffer的私有指针用来代表ByteBuffer。

3、ByteBuf的功能介绍
1)顺序读操作(read)
2)顺序写操作(write)
3)readerIndex和writerIndex
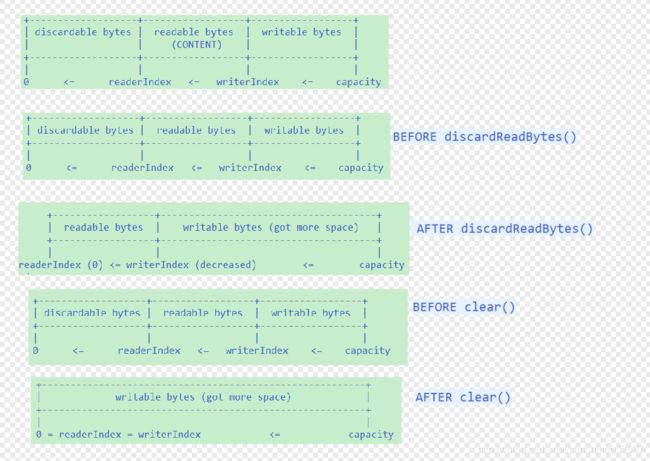
Netty提供勒两个指针变量用于支持顺序读取和写入操作:readerIndex用于读取标识读取索引,writerIndex用于标识写入索引。两个位置指针将ByteBuf缓冲区分割成三个区域。

调用ByteBuf的read操作时,从readerIndex处开始读取。readerIndex到writerIndex之间的空间为可读的字节缓冲区;从writerIndex到capacity之间为可写的直接缓冲区;0到readerIndex之间是已经读取过的缓冲区,可以调用discardReadBytes操作来重用这部分空间,以节约内存,防止ByteBuf的动态扩展。这在私有协议消息解码的时候非常有用,因为TCP底层可能粘包,几百个整包消息被TCP粘包后作为一个整包发送。这样,通过discardReadBytes操作可以重用之前已经解码过的缓冲区,从而防止接受缓冲区因为容量不足导致的扩张。
4)Discardable bytes
缓冲区的分配和释放是个耗时的操作,因此我们需要尽量重用它们。由于缓冲区的动态扩张需要进行自己数组的赋值,他是个耗时的操作,因此为了最大程度提升性能,往往需要尽最大努力提醒缓冲区的重用率。
5)readable bytes 和writerable bytes
可读空间段是数据时间存储的区域,以read或者skip开头的任何操作都将会从readerIndex开始读取或者跳过指定的数据,操作完成之后readerIndex增加了读取或者跳过的字节数长度。如果读取的字节数长度大于实际可读的字节数,则抛出IndexOutOfBoundsException。当新分配、包装或者负责一个新的ByteBuf对象时,它的readerIndex为0。
可写空间段是尚未被使用可以填充的空闲空间,任何以write开头的操作都会从writerIndex开始向空闲空间写入字节,操作完成之后writerIndex增加了写入的字节数长度。如果写入的字节数大于可写的字节数,则会抛出IndexOutOfBoundsException异常。新分配一个ByteBuf对象时,它的readerIndex为0。通过包装或者复制的方式创建一个新的ByteBuf对象时,它的writerIndex是ByteBuf的容量。
6)clear操作
7)mark和rest
当对缓冲区进行读操作时,由于某种原因,可能需要对之前的操作进行回滚。读操作并不会改变缓冲区的内容,回滚操作主要就是重新设置索引信息。
对于JDK的ByteBuffer,调用mark操作会将当前的位置指针备份到mark变量中,当调用rest操作之后,重新将指正的当前位置恢复为备份在mark中的值,

调用reset操作之后。
Netty的ByteBuf也有类似的rest和mark接口,因为ByteBuf有读索引和写索引,因此,它总共有4个相关的方法,分别如下
- markReaderIndex:将当前的readerIndex备份到markedReaderIndex
- resetReaderIndex:将当前的readerIndex设置为markedReaderIndex
- markWriterIndex:将当前的writerIndex备份到markedWriterIndex
- resetWriterIndex:将当前的writerIndex设置为markedWriterIndex

8)查询操作
- indexOf(int fromIndex, int toIndex, byte value)
- bytesBefore(byte value)
- bytesBefore(int length, byte value)
- bytesBefore(int index, int length, byte value)
- forEachByte(ByteBufProcessor processor)
- forEachByte(int index, int length, ByteBufProcessor processor)
- forEachByteDesc(ByteBufProcessor processor)
- forEachByteDesc(int index, int length, ByteBufProcessor processor)
9)derived buffers
- copy:复制一个新的ByteBuf对象,它的内容和索引都是独立的,复制操作本身并不修改原ByteBuf的读写内容
- copy(int index, int length):
- slice:
- slice(int index, int length)
- duplicate:返回当前ByteBuf的复制对象,复制后返回的ByteBuf与操作的ByteBuf共享缓冲区内容,但是维护自己独立的读写索引。当修改赋值后的ByteBuf内容后,之前原ByteBuf内UFO那个也随之改变,防范持有的是同一个内容指针引用。
10)转换成标准的ByteBuffer
- ByteBuffer nioBuffer()
- ByteBuffer nioBuffer(int index, int length)
11)随机读写(set和get)

4、ByteBuf源码分析
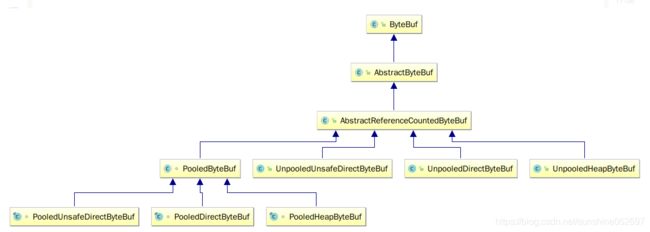
主要功能类库的继承关系图
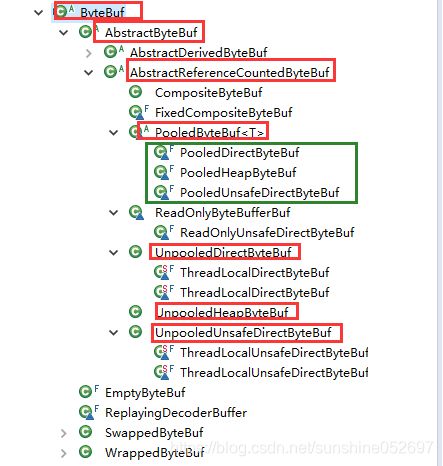
从该内存分配的角度看,ByteBuf可以分为两类。
- 堆内存(HeadByteBuf)字节缓冲区:特点是内存的分配和回收速度快,可以被JVM自动回收;缺点就是如果进行Socket的I/O读写,需要额外做一次内存复制,将堆内存对应的缓冲区复制到内核Channel中,性能会有一定程度的下降。
- 直接内存(DirectByteBuf)字节缓冲区:非堆内存,它在堆外进行内存分配,相比于堆内存,它的分配和回收速度会慢一些,但是将它写入或者从SocketChannel中读取时,由于少了一此内存复制,速度比堆内存快。
从内存回收角度看,ByteBuf也分为两类:基于对象池的ByteBuf和普通ByteBuf。两者的主要区别就是基于对象池的ByteBuf可以重用ByteBuf对象,它自己维护勒一个内存池,可以循环利用创建的ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。
AbstractByteBuf
- 主要成员变量
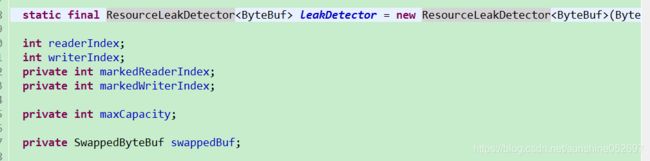
- 读操作簇

- 写操作

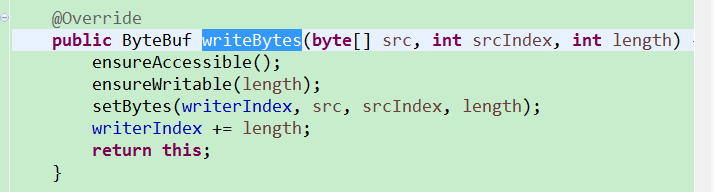
如果写入的字节数组长度小于0,则抛出IllegalReferenceCountException异常;如果写入的字节数组长度小于当前ByteBuf可写的字节数,说明可以写入成功,直接返回;如果写入的字节数组长度大于可以动态扩展的最大可写字节数,说明缓冲区无法写入超过其最大容量的字节数组,抛出IndexOutOfBoundsException异常。如果当前写入的字节数组长度虽然大于目前ByteBuf的可写字节数,但是通过自身的动态扩展可以满足新的写入请求,则进行动态扩展。

最小容量:(writerIndex + minWritableBytes)
最大容量:maxCapacity
首先设置门限阈值为4MB,当需要的新容量正好等于门限值时,使用阈值作为新的缓冲区容量;
如果新申请的内存空间大于阈值,每次步进4MB的方式进行内存扩张。扩张的时候需要对扩张后的内存和最大内存进行比较,如果大于缓冲区的最大长度,则使用maxCapacity作为扩容后的缓冲区容量;如果扩容后的新容量小于阈值,则以64为计数进行倍增,直到倍增后的结果大于或等于需要的容量值。
采用倍增或者步进算法的原因:如果以minNewCapactity作为目标容量,则本次扩容后的可写字节数刚好够本次写入使用,写入完成后,它的可写字节数会变为0,下次做写入操作的时候,需要再次动态扩容。这样就会形成第一次动态扩张后,每次写入操作都会进行动态扩张,由于动态扩张需要进行内存复制,频繁的内存复制会导致性能下降。
采用先倍增后步进的原因:当内存比较小的情况下,倍增操作并不会带来太多的内存浪费。但是,当内存增长到一定阈值后,再进行倍增就可能会带来额外的内存浪费。由于每个客户端链接都可能维护自己独立的接受和发送缓冲区,这样随着客户端的线性增长,内存浪费也会成比例地增加,因此,达到每个阈值后就需要以步进的方式对内存进行平滑的扩张。
- 操作索引
- 重用缓冲区
![]()
- skipBytes:可以忽略指定长度的字节数组,读操作时直接跳过这些数据读取后面的可读缓冲区。
AbstractReferenceCountedByteBuf
- 成员变量
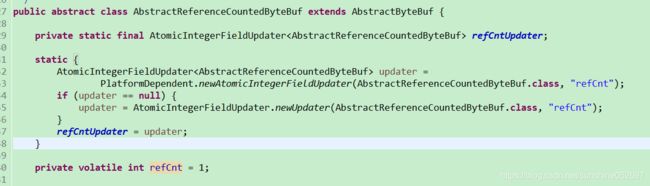
- 对象引用计数器:每调用一次retain方法,引用计数器就会加一,由于可能存在多线程并发调用的场景,以它的累加操作必须是线程安全的。
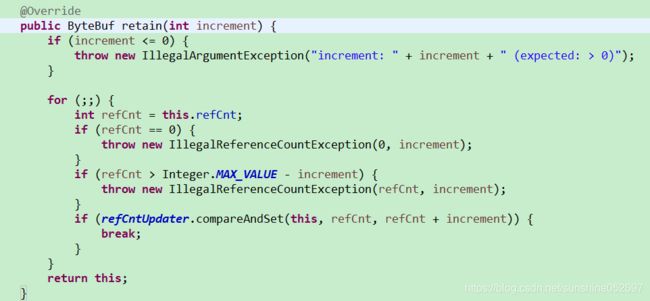
通过自旋对引用计数器进行加一操作,由于引用计数器的初始值为1,如果申请和释放操作能够保证正确使用,则它的最小值为1.当被释放和被申请的次数相等时,就调用回收方法回收当前的ByteBuf对象。如果为0,说明对象被意外、错误地引用,抛出IllegalReferenceCountException.如果引用计数器达到整型数的最大值,抛出引用越界的异常IllegalReferenceCountException。最后通过compareAndSet进行原子更新,它会使用自己获取的值跟期望值进行对比。如果其间已经被其他线程修改了,则比对失败,进行自旋,重新获取引用计数器的值再次比对;如果比对成功则对其加一。注意:compareAndSet是操作系统层面提供的原子操作,这类元祖操作被称为CAS。
释放引用计数器。与retain方法类似,它也是在一个自旋循环里面进行判断和更新的。需要注意的是:当refCnt==1时意味着申请和释放相等,说明对象引用已经不可达,该对象需要被释放和垃圾回收掉,则通过调用deallocate方法来释放ByteBuf对象。


UnpooledHeapByteBuf
基于堆内存进行内存分配的字节缓冲区,它没有基于对象池计数实现。这就意味着每次I/O的读写都会创建一个新的UnpooledHeapByteBuf,频繁进行大块内存的分配和回收对性能会造成一定影响,但是相比于堆外内存的申请和释放,它的成本还是会底一些。
相比于PooledHeapByteBuf,UnpooledHeapByteBuf的实现原理更加简单,也不容易出现内存管理方面的问题,因此在满足性能的情况先,推荐使用UnpooledHeapByteBuf。
- 成员变量

- 动态扩展缓冲区
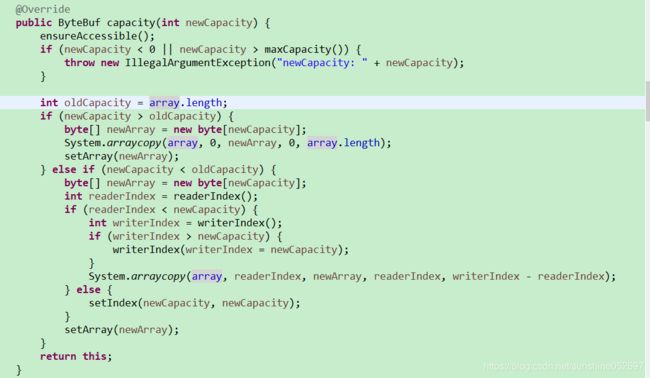
方法入口首先对新容量进行合法性校验,如果大于容量上限或者小于0,则抛出IllegalArgumentException异常。
判断新的容量值是否大于当前的缓冲区容量,如果大于则需要进行动态扩展,通过byte[] newArray = new byte[newCapacity]创建新的缓冲区字节数组,然后通过System.arraycopy(array, 0, newArray, 0, array.length)进行内存复制,将旧的字节数组复制到新创建的字节数组中,最后调用setArray替换旧的字节数组。
需要指出的是,当动态扩容完成后,需要将原来的视图tmpNioBuf设置为空。

如果新的容量小于当前的缓冲区容量,不需要动态扩展,但是需要截取当前缓冲区创建一个新的子缓冲区,具体的算法如下:首先判断下读索引是否小于新的容量值,如果小于进一步判断写索引是否大于新的容量值,如果大于则将写索引设置为新的容量值(防止越界)。更新完写索引之后通过内存复制System.arraycopy将当前可读的字节数组复制到新创建的子缓冲区中,

如果新的容量值小于读索引,说明没有可读的字节数组需要复制到新创建的缓冲区中,将读写索引设置为新的容量值即可。最后调用setArray方法替换原来的字节数组。
- 字节数组复制


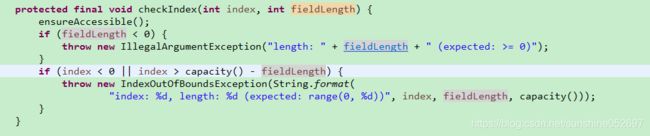
首先校验合法性。校验index和length的值,如果它们小于0,则抛出IllegalArgumentException,然后对两者之和进行判断;如果大于缓冲区的容量,则抛出IndexOutOfBoundsException。srcIndex和srcCapacity的校验与index类似。校验通过之后,调用System.arraycopy(src, srcIndex, array, index, length)方法进行字节数组的复制。
需要指出的是,ByteBuf以set和get开头读写缓冲区的方法并不会修改读写索引。
- 转换成JDK ByteBuffer
NIO的ByteBuf提供wrap方法,可以将byte数组转换成ByteBuffer对象,相关实现如下:
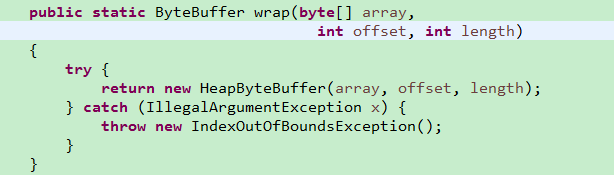
UnpooledHeapByteBuf将ByteBuf转换成ByteBuffer对象的实现。
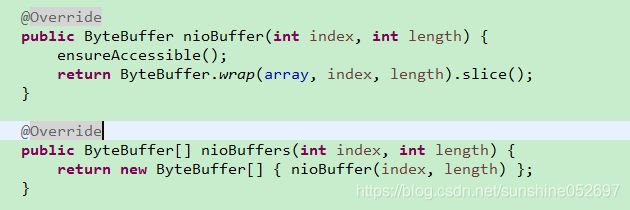
此处调用slice方法。由于每次调用nioBuffer都会创建一个新的ByteBuffer,因此此处的slice方法起不到重用缓冲区内容的效果,只能保证读写索引的独立性。
- 子类实现相关方法
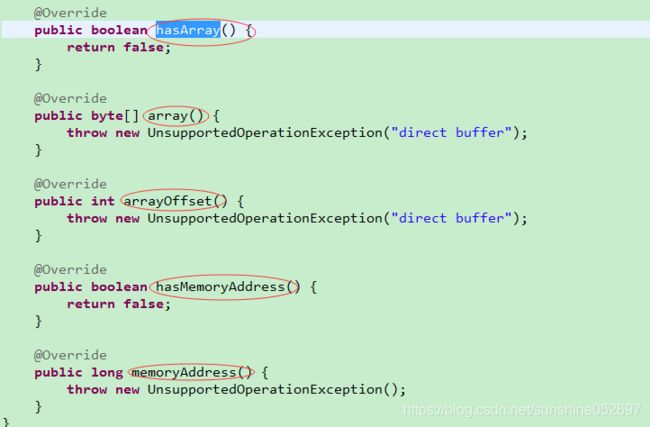
1)isDirect():如果是基于堆内存实现的ByteBuf,它返回false;
2)hasArray():由于UnpooledHeapByteBuf基于字节数组实现,所以返回true;
3)array():由于UnpooledHeapByteBuf基于字节数组实现,返回值是呢呗自己数组成员变量
4)arrayOffset()、hasMemoryAddress()、memoryAddress()
内存地址相关的接口主要由UnsafeByteBuf使用。
UnpooledDirectByteBuf内部缓冲区由java.nio.DirectByteBuffer实现。
PooledByteBuf内存池原理分析
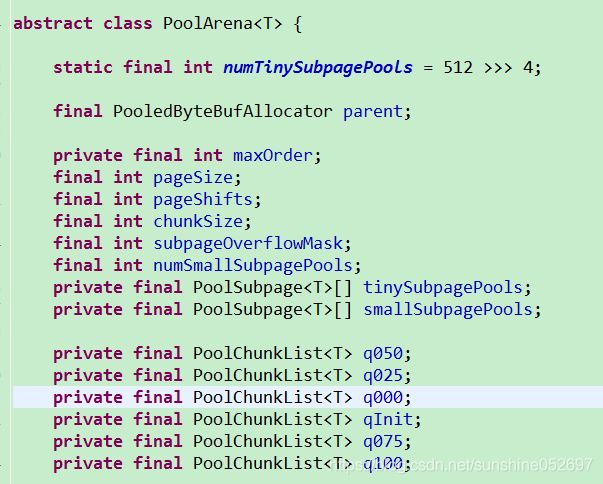
- PoolArena
PoolArena是Netty的内存池实现类。
为了集中管理内存的分配和释放,同时提高分配和释放内存时候的性能,预先申请一大块儿内存,然后通过提供相应的分配和释放接口来使用内存。这样一来,对内存的管理就被集中到几个类或者函数中,由于不再频繁使用系统调用来申请和释放内存,引用或者系统的性能也会大大提高。这种预先申请的那一大块内存就被称为 Memory Arena。
不同的框架,Memory Arena的实现不同,Netty的PoolArena是由多个Chunk组成的大块内存区域,而每个Chunk则由一个或者多个Page组成,因此,对内存的组织和管理也就主要集中在如何管理和组织Chunk和Page勒。
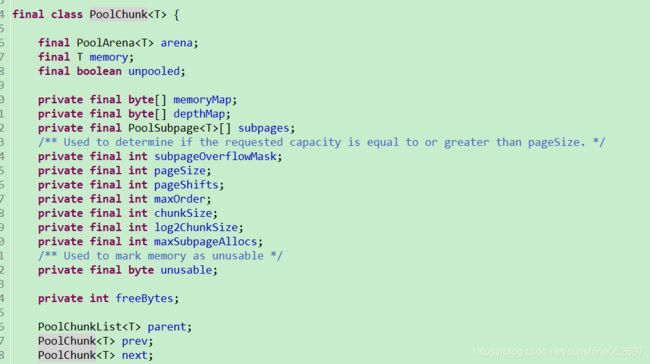
- PoolChunk
Chunk主要用来组织和管理多个Page的内存分配和释放,在Netty中,Chunk中的Page被构建成一棵二叉树。假设一个Chunk由16个Page组成,那么这个Page将会被按照下图的形式组织起来

Page的大小是4字节,Chunk的大小是64的字节(4*16)。整棵树有5层,第一层用来分配所有的Page内存,第4层用来分配2个Page的内存。。。每个节点都记录勒自己在整个Memory Arena中的偏移地址,当一个节点代表的内存区域被分配出去之后,这个节点就会被标记为已分配,自这个节点以下的所有节点在后面的内存分配请求中都会被忽略。
举例来说,当我们请求一个16字节的存储区域时,上面这个树中的第三层中的4个节点中的一个就会被标记为已分配,这就表示整个MemoryArena中有16个字节被分配出去勒,新的分配请求只能从剩下的3个节点及其子树中寻找合适的节点。
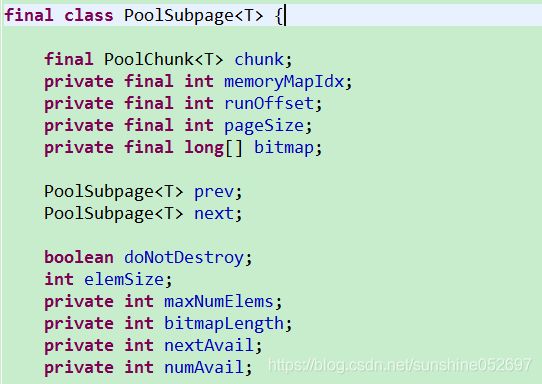
- PoolSubpage
对于小于一个Page的内存,Netty在Page中完成分配。每个Page会被切分成大小相等的多个存储块,存储块的大小由第一次申请的内存块大小决定。假如一个Page是8个字节,如果第一次申请的块大小是4个字节,那么这个Page就包含2个存储块;如果第一次申请的是8个字节,那个这个Page就被分成一个存储块。
一个Pgae只能用于分配与第一申请时大小相同的内存,比如,一个4字节的Page,如果第一次分类勒1字节的内存,那么后面这个Page只能继续分配1字节的内存,如果有一个申请2字节内存的请求,就需要在一个新的Page中进行分配。
Page中存储区域的使用状态通过一个long数组来维护,数组中每个long的每一位表示一个块存储区域的占有情况,0表示未占有,1表示已占有。对于一个4字节的Page来说,如果这个Page用来分配1个字节的存储区域,那么long数组中就只有一个long类型的元素,这个数值的低4位用来指示各个存储区域的占有情况。对于一个128字节的Page来说,如果这个Page也是用来分配1个字节的存储区域,那么long数组就会包含2个元素,总共128位,每一位代表一个区域的占用情况。
- 内存回收策略
无论是Chunk还是Page,都通过状态位来标识内存是否可用,不同之处是Chunk通过在二叉树上对节点进行标识,Page是通过维护块的使用状态来标识来实现。
PooledDirectByteBuf源码分析
PooledDirectByteBuf基于内存池实现,与UnPooledDirectByteBuf的唯一不同个就是缓冲区的分配式销毁策略不同,其他功能都是等同的,即两者唯一的不同就是内存分配策略不同。
- 创建字节缓冲区实例

由于采用内存池实现,所以新创建PooledDirectByteBuf对象时不能直接new一个实例,而是从内存池中获取,然后设置引用计数器的值。
直接从内存池Recycler
- 复制新的字节缓冲区实例
如果使用者确实需要复制一个新的实例,与原来的PooledDirectByteBuf独立,则调用它的copy(int index,int length)可以达到上述目标
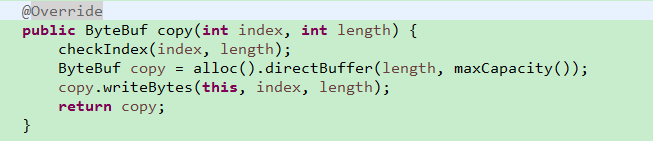
首先对索引和长度进行合法性校验,通过之后调用PooledByteBufAllocator分配一个新的ByteBuf,由于AbstractByteBufAllocator没有实现directBuffer方法,所以最终调用到AbstractByteBufAllocator的directBuffer方法

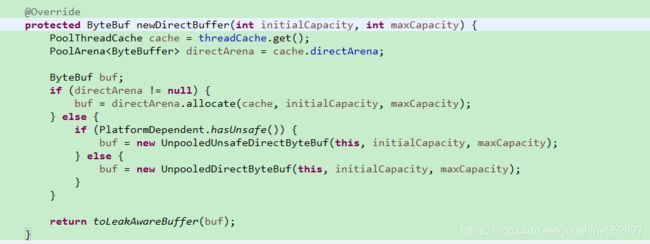
newDirectBuffer 方法对不同的子类有不同的实现策略,如果是基于内存池的分配器,它会从内存池中获取可用的ByteBuf,如果是非池,则直接创建新的ByteBuf

- 子类实现相关方法
5、ByteBuf相关的辅助类功能介绍
-
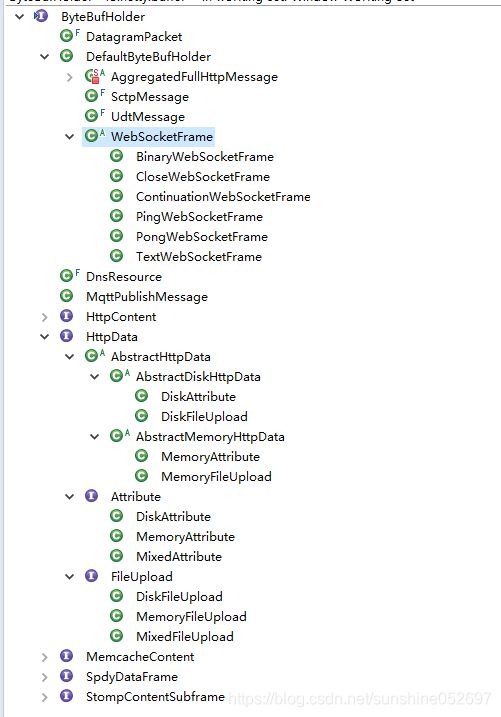
ByteBufHolder
是ByteBuf的容器。如http协议的请求消息和应答消息都可由携带消息体,这个消息体在NIO ByteBuffer中就是个ByteBuffer对象,在Netty中就是ByteBuf对象。由于不同的协议消息体可以包含不同的协议字段和功能,因此,需要对ByteBuf进行包装和抽象,不同的子类可以有不同的实现。
为了满足这些定制化的需求,netty抽象出了ByteBufHolder对象,它包含勒一个ByteBuf,另外还提供勒一些其他使用的方法,使用者继承ByteBufHolder接口后可以按需封装自己的实现。
-
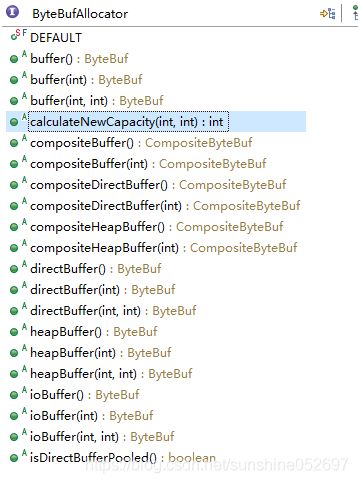
ByteBufAllocator
ByteBufAllocator是字节缓冲区分配器,按照Netty的缓冲区实现不同,共有两种不同的分配器:基于内存池的字节缓冲区分配器和普通的字节缓冲区分配器。

-
CompositeByteBuf
CompositeByteBuf允许将多个ByteBuf的实例组装到一起,形成一个统一的视图。CompositeByteBuf在一些场景下非常有用,例如某个协议POJO对象包含两部分:消息头和消息体,他们都是ByteBuf对象。当需要对消息进行编码的时候需要进行整合,如果使用JDK默认能力,有以下两种方式
1)将某个ByteBuf复制到另一个ByteBuffer中,或者创建一个新的ByteBuffer,将两者复制到新建的ByteBuffer中
2)通过List或数组等容器,将消息头和消息体放到容器中进行统一维护和处理
缓冲区有多个,但是需要统一展示和处理,必须有存放它们的统一容器,为了解决这个问题,Netty提供勒CompositeByteBuf

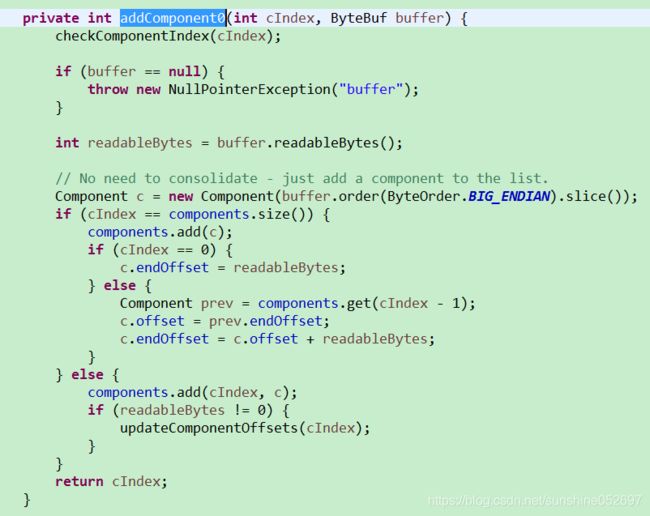
CompositeByteBuf中新增一个ByteBuf的代码

删除增加的ByteBuf

-
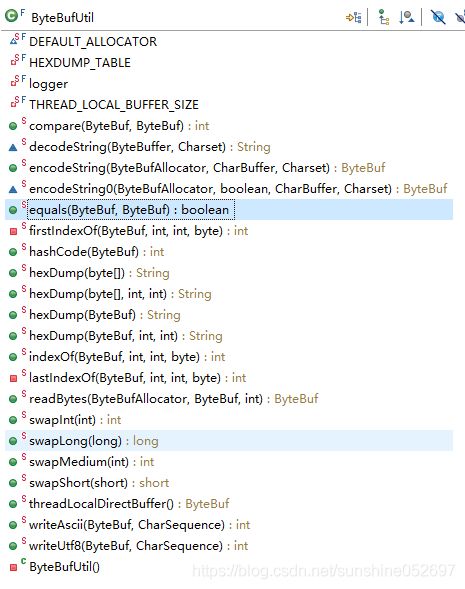
ByteBufUtil
提供一类静态方法用于操作ByteBuf对象。
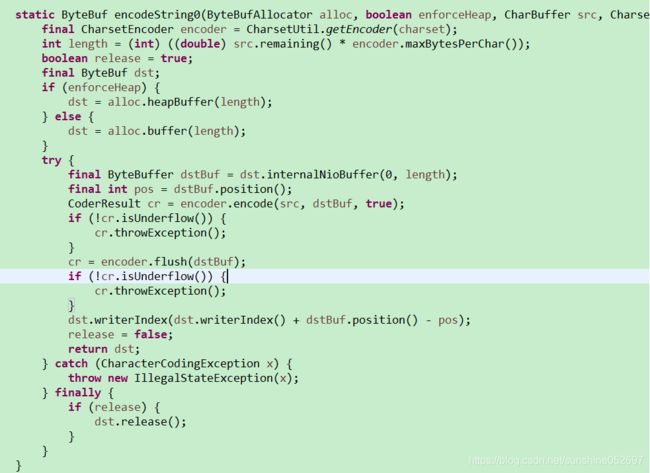
- encodeString(ByteBufAllocator alloc, CharBuffer src, Charset charset):对需要编码的字符串src按照指定的字符集charset进行编码,利用制动的ByteBufAllocator生成一个新的ByteBuf

- decodeString(ByteBuffer src, Charset charset):使用指定的ByteBuffer和charset进行对ByteBuffer进行解码,获取解码后的字符串。
- hexDump(ByteBuf buffer):将参数ByteBuf的内容以十六进制字符串的方式打印出来,用于输出日志或者打印码流,方便问题定位,提升系统的可维护性。