生物信息学入门 富集分析与蛋白质互作用网络(PPI)的可视化 Cystocape入门指南

网络图是生物信息学中常用的显示不同节点之间关联方向与关联程度的可视化方法。在富集分析中,网络图常被用于表示功能与估计到该功能的基因的联系。在蛋白质互作用网络中,网络图常用于表示编码基因之间的互作用类型与作用强度,基于这些信息,还可以通过某一节点与其他节点的连接数量来判断该节点在整个网络中的贡献度(degree)。绘制网络图常使用cystoscape软件,通过输入符合规范的数据,调整合适的参数,就可以得到一张包含多样化信息的网络。本文将从结果解读开始,先介绍网络图中常可以展示的信息类型,再介绍如何准备数据和调整参数。
1. 结果解读
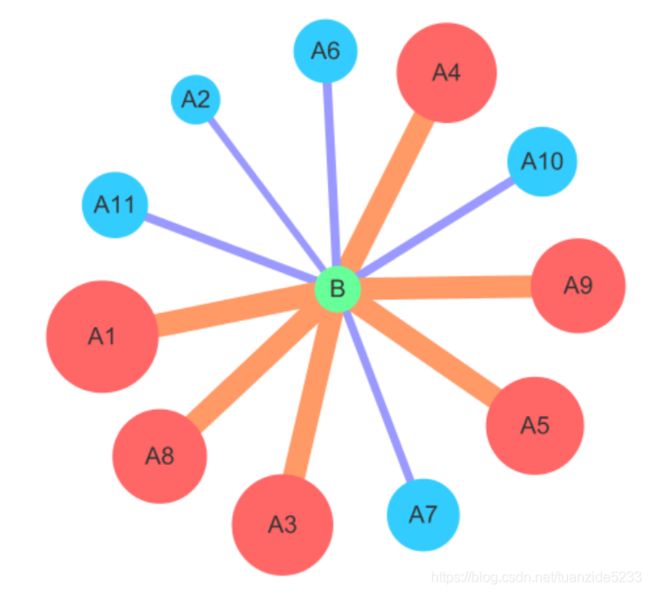
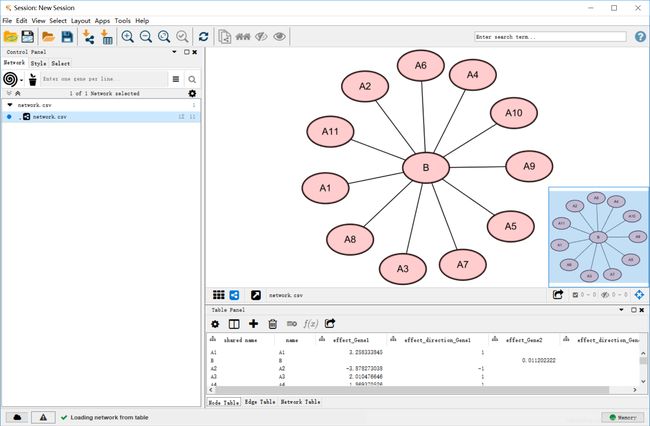
这张图中包含的信息有:
1. 12个节点的对应关系
2. 不同节点有不同的颜色,代表所属组别,是定性属性
3. 不同的节点有不同的大小,代表某种定量属性
4. 不同连接线有不同的颜色,代表对应的互作用关系的作用类型,是定性属性
5. 不同连接线有不同的宽度,代表对应的互作用关系的作用强度,是定量属性
2. 数据准备
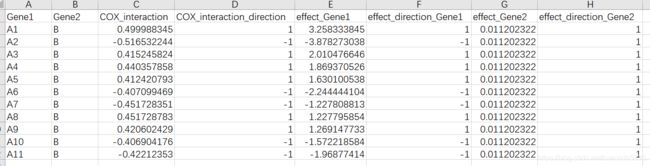
2.1 必需元素
如前所述,网络图是表示节点及其连接关系的图,因此,节点和对应关系是网络图的必需元素,也就是表格中的A列和B列。可以看到,有节点A1-A11均与节点B存在关联,反过来,节点B和节点A1-A11存在一对多的关系。
2.2 节点连接关系
既然节点之间存在连接关系,那么如何定义这种关系呢?在这里,我们使用了两个信息来描述,即C列的作用强度和D列的作用方向。作用强度通常可以由数据库给出,作用方向是使用-1表示负相关,1表示正相关。这样,我们就不仅知道两个节点有关联,还可以定量和定性的描述这种关联。
2.3 节点属性
在实际应用中,不同的节点具有不同的属性。比如用于描述miRNA-mRNA调节关系的网络中,每一个节点将会属于miRNA或者mRNA,那么我们就可以再添加一列信息用于描述这种属性。在本文中,我们假设A1-A11和B表示各不相同的12个基因,它们对于某一特定疾病具有不同的影响,如果增加患病风险,我们使用一个正值表示,数值越大,则表示增加的风险越多(risk factor),反之亦然。在表中,E列和G列分别定量地表示Gene1(A1-A11)与Gene2(B)对疾病的影响强度和方向。F和H则定性的表示这种方向。
3. 参数调整
3.1 输入准备好的表格
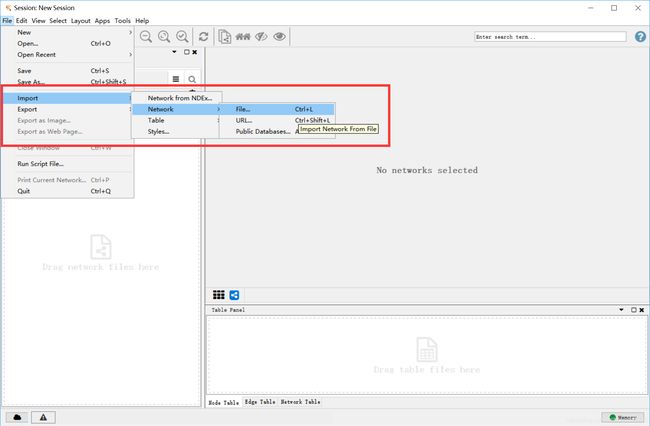
给不同的列定义作用类别
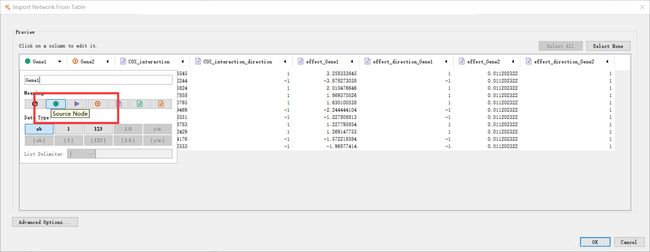
Gene1列定义为source node,表示作为一个出发点
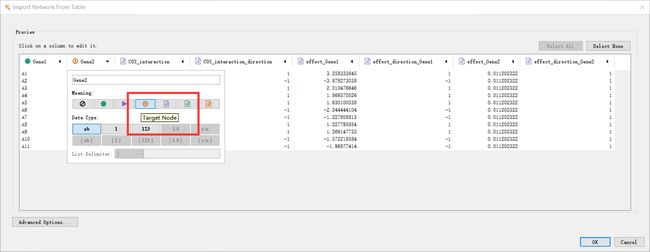
Gene2列定义为target node,表示作为一个目标终点
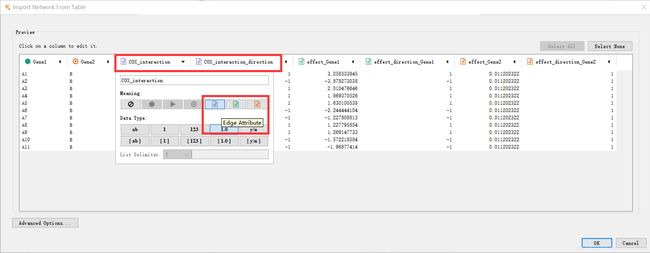
cystoscape中的连接使用edge描述,因此edge attribute表示连接属性。说明这一列的数据都是用来描述前面两个对应的节点的连接属性的,即包含了连接属性的定量或定性信息。
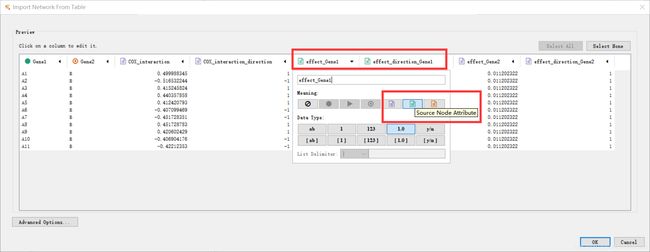
source node attribute表示出发点属性。说明这一列的数据都是用来描述source node列的节点的节点属性,即包含了节点本身性质的一些信息,比如对疾病影响强度与方向。
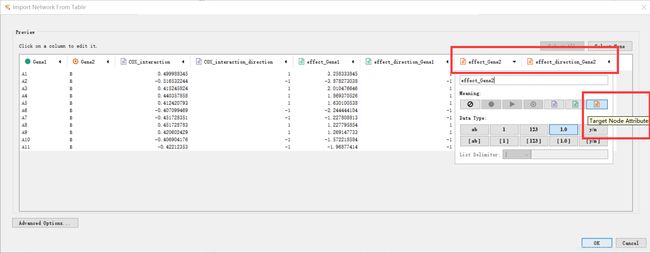
target node attribute表示目标节点点属性。说明这一列的数据都是用来描述target node列的节点的节点属性,即包含了节点本身性质的一些信息,比如对疾病影响强度与方向。
之后就得到了最原始的一张网络图
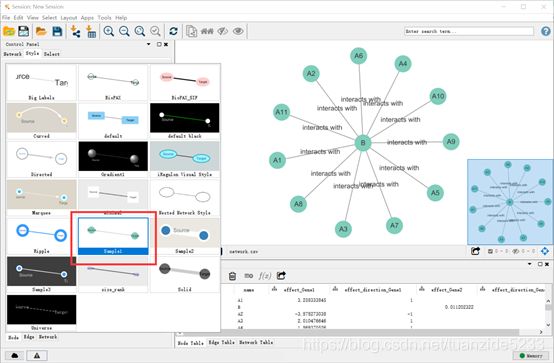
3.2 在网络图中添加输入的参数信息
可以非常明显的看到这种图除了比较丑之外,还丢失了很多信息。事实上,它支包含了节点之间的对应信息,而节点属性和连接属性均没有体现在图上。下面来演示一下如何添加对应的信息。
在左侧style列选择一个预设的风格
在左下角选择node,上方的界面就会显示node节点的参数列表
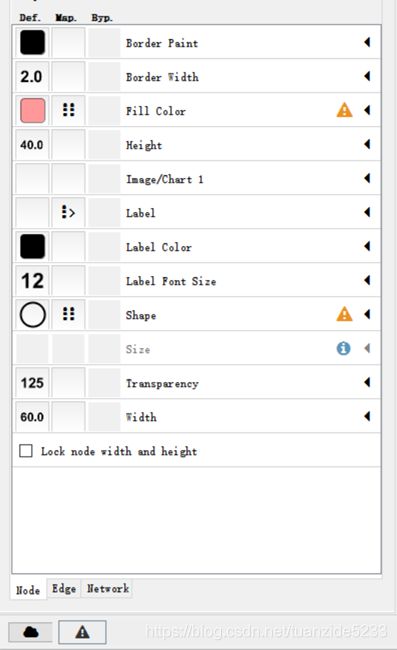
下面调整节点的颜色,将对疾病有正向影响的节点表示为红色,负影响的节点表示为蓝色,B节点表示为绿色
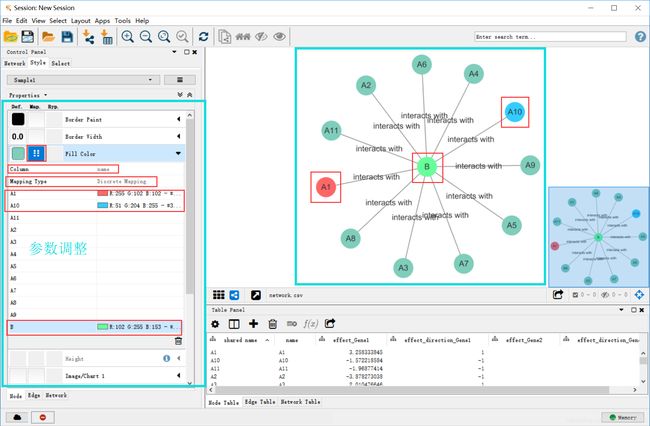
完成之后
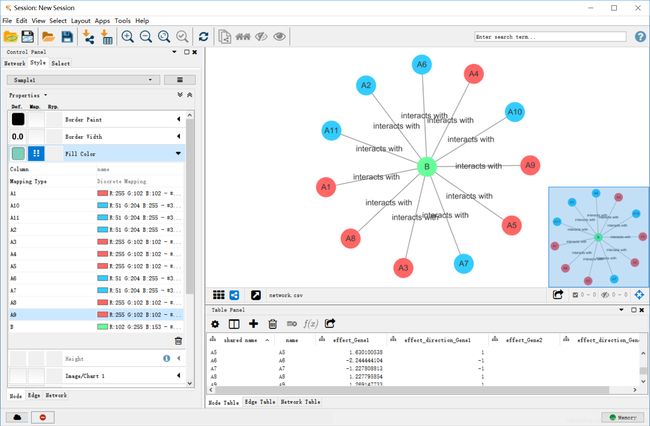
在左下角选择edge 如图所示,点击对应参数栏右下角的垃圾桶标记将连接线上的文字去掉
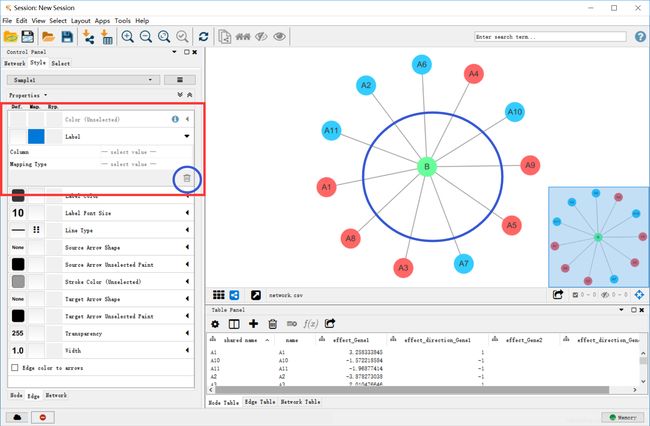
在最下面的width栏调节线的宽度,在这里我们用宽度表示互作用强度,设置如下

但是连接线太宽了,可以通过双击左下角的图表设置
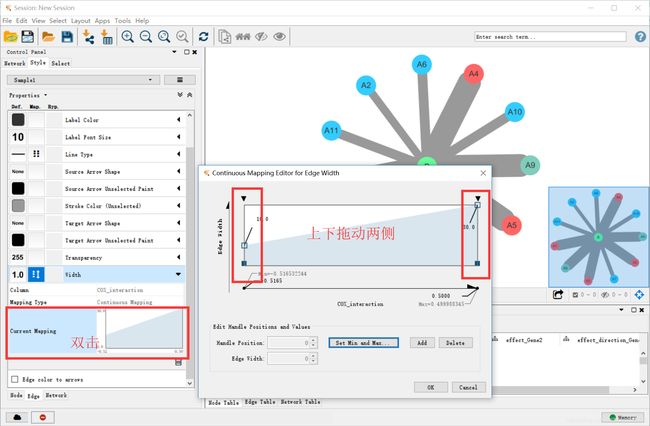
这样线条的宽度就比较合适了
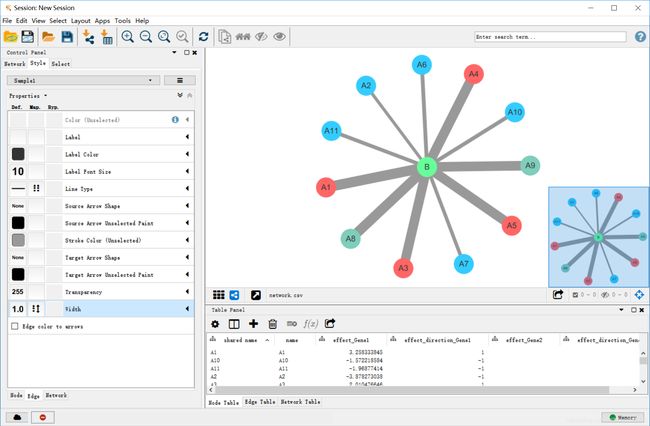
下面我们来调节线条的颜色,用橙色表示正相关,紫色表示负相关。这里我们用到了定性的参数,分贝对1和-1的连接线定义颜色,就可以快速的进行调整。
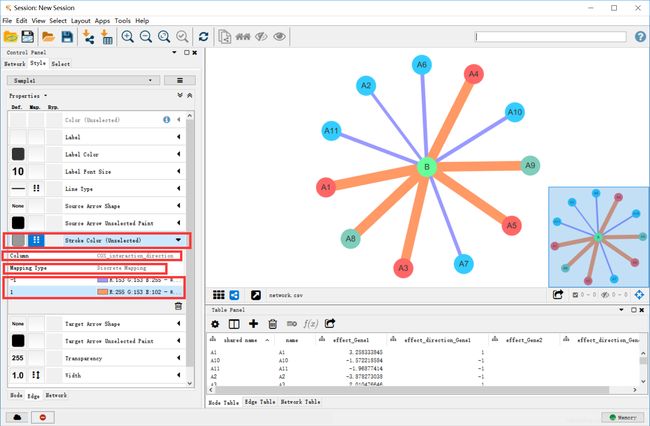
现在节点的对疾病的影响强度还没有显示,我们可以通过和调节线条宽度类似的操作来实现,先将进入node的参数列表
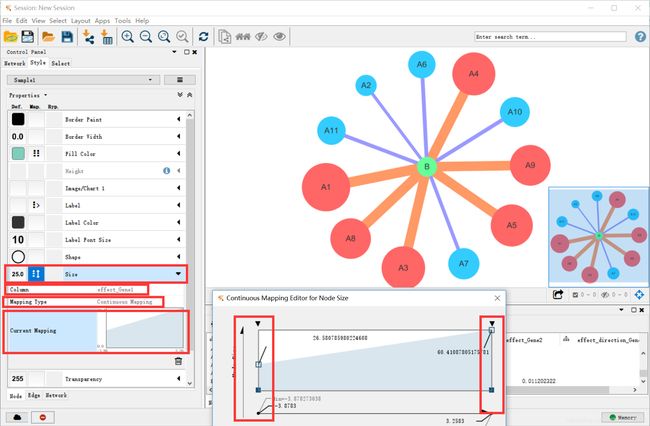
再调整一下字体大小,一张好看的网络图就完成了
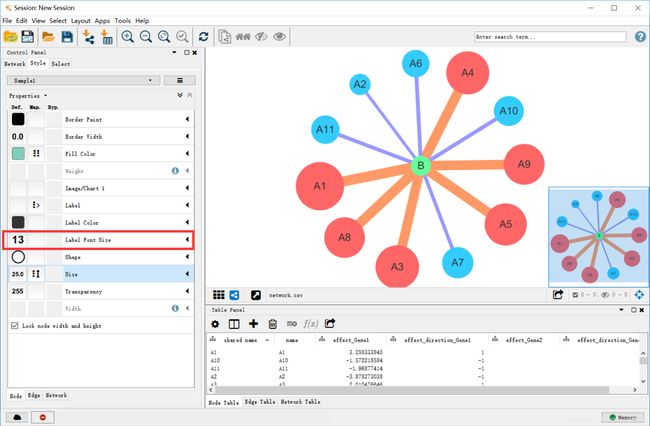
Cystoscape是一款功能非常强大的软件,这里仅展示了一小部分功能。应结合 数据类型-参数设置方法-显示结果 的对应关系,灵活使用!
附:
| Gene1 | Gene2 | COX_interaction | COX_interaction_direction | effect_Gene1 | effect_direction_Gene1 | effect_Gene2 | effect_direction_Gene2 |
| A1 | B | 0.499988345 | 1 | 3.258333845 | 1 | 0.011202322 | 1 |
| A2 | B | -0.516532244 | -1 | -3.878273038 | -1 | 0.011202322 | 1 |
| A3 | B | 0.415245824 | 1 | 2.010476646 | 1 | 0.011202322 | 1 |
| A4 | B | 0.440357858 | 1 | 1.869370526 | 1 | 0.011202322 | 1 |
| A5 | B | 0.412420793 | 1 | 1.630100538 | 1 | 0.011202322 | 1 |
| A6 | B | -0.407099469 | -1 | -2.244444104 | -1 | 0.011202322 | 1 |
| A7 | B | -0.451728351 | -1 | -1.227808813 | -1 | 0.011202322 | 1 |
| A8 | B | 0.451728783 | 1 | 1.227795854 | 1 | 0.011202322 | 1 |
| A9 | B | 0.420602429 | 1 | 1.269147733 | 1 | 0.011202322 | 1 |
| A10 | B | -0.406904176 | -1 | -1.572218584 | -1 | 0.011202322 | 1 |
| A11 | B | -0.42212353 | -1 | -1.96877414 | -1 | 0.011202322 | 1 |
GEO芯片数据差异表达分析时需要log2处理的原因
https://blog.csdn.net/tuanzide5233/article/details/88542805
GEO芯片数据差异表达分析时是否需要log2以及标准化的问题
https://blog.csdn.net/tuanzide5233/article/details/88542558
差异表达矩阵制作教程
https://blog.csdn.net/tuanzide5233/article/details/83659768
差异表达的热图绘制详见
https://blog.csdn.net/tuanzide5233/article/details/83659501
使用edgeR对RNAseq数据进行差异表达分析教程
https://blog.csdn.net/tuanzide5233/article/details/88785486
差异表达分析(DEG)时 row.names'里不能有重复的名字 的解决方案
https://blog.csdn.net/tuanzide5233/article/details/86568155
生存分析系列教程(一)使用生信人工具盒进行生存分析
https://blog.csdn.net/tuanzide5233/article/details/83685403
富集分析与蛋白质互作用网络(PPI)的可视化 Cystocape入门指南
https://blog.csdn.net/tuanzide5233/article/details/88048439
进阶版Venn plot:Upset plot入门实战代码详解——UpSetR包介绍
https://blog.csdn.net/tuanzide5233/article/details/83109527
使用R语言ggplot2包绘制pathway富集分析气泡图(Bubble图):数据结构及代码
https://blog.csdn.net/tuanzide5233/article/details/82141817