前言
做RNA-seq基因表达数据分析挖掘,我们感兴趣的其实是“基因互作”,哪些基因影响了我们这个基因G,我们的基因G又会去影响哪些基因,从而得到基因调控的机制。
直觉确实是很明确的,但是细节处却有很多问题。
我们讨论的到底是基因表达的互作,还是基因产物的互作?
------------
对于蛋白编码基因,它翻译产生蛋白,如果此蛋白不参与转录过程,理论上不可能会影响另一个基因的表达,那也就不存在基因表达的互作的,它们的基因表达被很好的隔离起来了,相互独立,互不影响。
但现在鉴定出了很多调控基因或其他在基因组上的调控序列,比如miRNA、lncRNA等,它们也都需要从基因组上转录出来,然后转录产物会去影响其他基因的表达(影响转录)。这才是基因表达互作,虽然MiRNA、lncRNA不能被称作基因。
------------
基因产物的互作就普遍了,那就是蛋白互作,也就是STRING等数据库里收集的信息。
蛋白互作也容易直观理解些,复杂的多细胞生命体,几乎所有的功能都是靠蛋白来实现的,所以有很多蛋白要互相结合(空间上)在一起来行使自己的功能。
------------
还有一个就是遗传学领域的基因互作,这与生物学的基因互作完全不同,遗传学考虑的是宏观的基因互作,站在表型的基础上。 Novel phenotypes often result from the interactions of two genes。
遗传学的基因互作是生物学基因产物互作的结果。
Defining genetic interaction
GENE INTERACTIONS
STRING database的挖掘
这个数据库绝对是做实验人的宝藏,里面包含了各种蛋白互作关系,不用做实验就有一大堆证据。
IPA了解一下,收费的高端分析软件,大部分就是整合的这个数据库,很多大佬喜欢用IPA来找明星基因,再来讲故事,实例请看之前解读的CSC paper。
首先了解一下STRING里面有哪些文件可以下载:
https://string-db.org/cgi/download.pl?sessionId=yMNmD7s36wS8
选你的物种,减少文件大小,常用的就是互作数据:
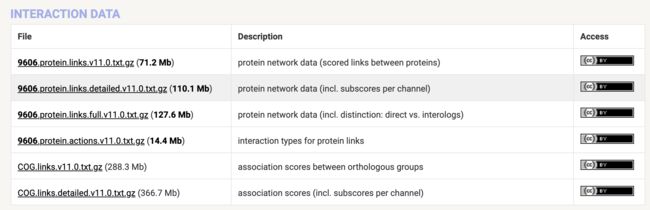
一般我们想知道某个蛋白会与哪些其他蛋白互作,以及互作的类型,然后做下游分析,信息都在这几个文件里了。
注:有哪些互作关系需要好好搞清楚,移步help,https://string-db.org/cgi/help.pl?sessionId=yMNmD7s36wS8
Docs » User documentation » Getting started » Evidence
Conserved Neighborhood
Co-occurrence
Fusion
Co-expression
Experiments
Databases
Text mining
每一个PPI关系的证据来源是不同的,选择你需要的证据。我觉得里面最可靠的就是Experiments, Databases和Text mining了。
当然,我们是高手,能用更简单的方法绝不用复杂的,那么STRING的API了解一下。
用任意脚本语言读以下格式化地址:
https://string-db.org/api/[output-format]/interaction_partners?identifiers=[your_identifiers]&[optional_parameters]
就能得到一个dataframe结果,不用下载,不用筛选,速度更快,随调随用。
实例,我想知道HDAC4的互作蛋白,可以这么抓:
老鼠:Mus%20musculus
url <- "https://string-db.org/api/tsv/interaction_partners?identifiers=HDAC4&species=Homo%20sapiens"
webDf <- read.table(url, header=T)
head(webDf)
stringId_A stringId_B preferredName_A preferredName_B ncbiTaxonId score
1 ENSP00000264606 ENSP00000080059 HDAC4 HDAC7 9606 0.934
2 ENSP00000264606 ENSP00000202967 HDAC4 SIRT4 9606 0.809
3 ENSP00000264606 ENSP00000209873 HDAC4 AAAS 9606 0.901
4 ENSP00000264606 ENSP00000209875 HDAC4 CBX5 9606 0.779
5 ENSP00000264606 ENSP00000212015 HDAC4 SIRT1 9606 0.988
6 ENSP00000264606 ENSP00000215832 HDAC4 MAPK1 9606 0.572
nscore fscore pscore ascore escore dscore tscore
1 0 0 0 0.061 0.320 0.90 0.061985
2 0 0 0 0.052 0.166 0.00 0.778000
3 0 0 0 0.058 0.000 0.90 0.000000
4 0 0 0 0.062 0.463 0.54 0.159000
5 0 0 0 0.052 0.415 0.90 0.812000
6 0 0 0 0.000 0.433 0.00 0.276000
结果解读:
Output fields (TSV and JSON formats):
| Field | Description |
|---|---|
| stringId_A | STRING identifier (protein A) |
| stringId_B | STRING identifier (protein B) |
| preferredName_A | common protein name (protein A) |
| preferredName_B | common protein name (protein B) |
| ncbiTaxonId | NCBI taxon identifier |
| score | combined score |
| nscore | gene neighborhood score |
| fscore | gene fusion score |
| pscore | phylogenetic profile score |
| ascore | coexpression score |
| escore | experimental score |
| dscore | database score |
| tscore | textmining score |
抓其他信息改下API就行了
还有很多工具是基于STRING做富集分析的,也可以了解一下,主要看自己需求。
待续~