PyTorch入门(五):数据加载和处理
数据加载和处理
PyTorch提供了许多工具加载数据,使代码更具有可读性。
- scikit-image:用于图像io和transform
- pandas:更容易解析csv
我们要处理一个面部姿态的数据集。每张图片有68个不同的标记点。如下图注释:

快速读取csv文件并且从一个(N,2)的数组得到标记,其中N是标记点的数量。
landmarks_frame = pd.read_csv('data/faces/face_landmarks.csv')
n = 65
#提取第n行第0列的值,即照片名
img_name = landmarks_frame.iloc[n,0]
#将第n行第1列以后所有的列以矩阵形式显示
landmarks = landmarks_frame.iloc[n,1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1, 2)
print('Image name:{}'.format(img_name))
print('Landmarks shape:{}'.format(landmarks.shape))
print('First 4 Landmarks:{}'.format(landmarks[:4]))
输出为

通过一下代码可以显示图像及标记,用它来显示样本。
def show_landmarks(image,landmarks):
plt.imshow(image)
plt.scatter(landmarks[:,0],landmarks[:,1],s=10,marker='.',c='r')
plt.pause(0.001)
plt.figure()
show_landmarks(io.imread(os.path.join('data/faces/',img_name)),landmarks)
plt.show()

DataSet class
torch.utils.data.DataSet是一个表示数据集的抽象类。自定义的数据集应该继承Dataset类并且重载一下方法:
- len:通过len(dataset)返回数据集的大小
- getitem:支持整数索引,范围从0到len(self),用法:通过dataset[i]得到索引为i的样本和标签
定制自己的DataSet。首先继承DataSet类,在__init__函数中实现csv数据读入,但读图是在__getitem__中实现,这是一种高效的方法,因为不是所有的数据都要在一开始读入内存中,可以在需要的时候再读取。
我们的数据集是字典形式{'image': image, 'landmarks':landmarks}。
class FaceLandmarksDataset(Dataset):
def __init__(self,csv_file,root_dir,transform=None):
"""
:param csv_file: 带注释的csv文件路径
:param root_dir: 所有图像目录
:param transform: 一个样本要应用的可选变换
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, item):
img_name = os.path.join(self.root_dir,self.landmarks_frame.iloc[item,0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[item,1:].as_matrix()
landmarks = landmarks.astype('float').reshape(-1,2)
sample = {'image':image,'landmarks':landmarks}
if self.transform:
sample = self.transform(sample)
return sample
将该类实例化,并且显示前4个样本及他们的标记点。
face_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',root_dir='data/faces/')
fig = plt.figure()
for i in range(len(face_dataset)):
sample = face_dataset[i]
print(i,sample['image'].shape,sample['landmarks'].shape)
ax = plt.subplot(1,4,i+1)
plt.tight_layout()
ax.set_title('Sample #{}'.format(i))
ax.axis('off')
show_landmarks(**sample)
if i==3:
plt.show()
break


Transforms
我们的样本有个问题是尺寸不一。大多数神经网络希望图片有相同的尺寸。因此,我们需要对图片进行预处理。
- Rescale:缩放图像
- RandomCrop:随机裁剪图片,用于数据增强
- ToTensor:将numpy图像转为torch图像(需要交换轴axes)
将这些转换编写为可调用类而不是简单的函数,这样每次调用时不需要传递变换的参数,我们需要实现__call__方法,如果有需要,还要实现__init__方法。可以通过如下代码使用转换:
tsfm = Transform(params)
transformed_sample = tsfm(sample)
class Rescale(object):
"""
缩放给定图像的尺寸
"""
def __init__(self,output_size):
"""
:param output_size: 所需输出大小,为元祖(tuple)或整形(int)。
如果为元祖,则输出与output_size匹配;如果为int,则较小图像边缘与output_size匹配,保持纵横比相同。
"""
assert isinstance(output_size,(int,tuple))
self.output_size = output_size
def __call__(self, sample):
image,landmarks = sample['image'],sample['landmarks']
h,w = image.shape[:2]
if isinstance(self.output_size,int):
if h>w:
new_h,new_w = self.output_size*h/w,self.output_size
else:
new_h, new_w = self.output_size , self.output_size* w/h
else:
new_h, new_w = self.output_size
new_h = int(new_h)
new_w = int(new_w)
img = transform.resize(image,(new_h,new_w))
landmarks = landmarks*[new_w/w,new_h/h]
return {'image':image,'landmarks':landmarks}
class RandomCrop(object):
"""
随机裁剪图像
"""
def __init__(self,output_size):
"""
:param output_size: 需要的输出大小,如果是int,进行正方形裁剪。
"""
assert isinstance(output_size,(int,tuple))
if isinstance(output_size,int):
self.output_size = (output_size,output_size)
else:
assert len(output_size)==2
self.output_size = output_size
def __call__(self,sample):
image, landmarks = sample['image'], sample['landmarks']
h, w = image.shape[:2]
new_h, new_w = self.output_size
top = np.random.randint(0,h-new_h)
left = np.random.randint(0,w-new_w)
image = image[top:top+new_h,left:left+new_w]
landmarks = landmarks-[left,top]
return {'image':image,'landmarks':landmarks}
class ToTensor(object):
"""
将样本中的ndarrays转为Tensors
需要交换颜色轴,因为:
numpy image: H x W x C
torch image: C X H X W
"""
def __call__(self, sample):
image, landmarks = sample['image'], sample['landmarks']
image = image.transpose((2,0,1))
return {'image':torch.from_numpy(image),
'landmarks':torch.from_numpy(landmarks)}
可以通过以下代码将转换应用与样本上。
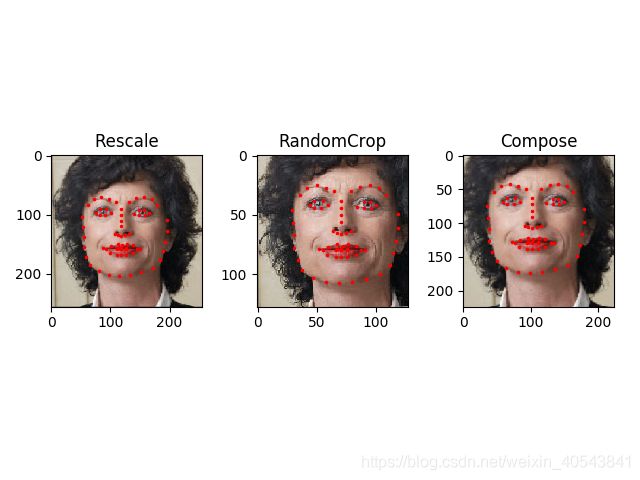
假设我们想将图像短一点的边缩短至256,且想从中随机裁剪一个大小为224的正方形图片,即我们想组合Rescale和RandomCrop变换。可以通过调用torchvision.transforms.Compose来实现。
scale = Rescale(256)
crop = RandomCrop(128)
composed = transforms.Compose([Rescale(256),RandomCrop(224)])
fig = plt.figure()
sample = face_dataset[65]
for i,tsfrm in enumerate([scale,crop,composed]):
transformed_sample = tsfrm(sample)
ax = plt.subplot(1,3,i+1)
plt.tight_layout()
ax.set_title((type(tsfrm).__name__))
show_landmarks(**transformed_sample)
plt.show()
迭代数据集
可以将这些变换放在一起,创建一个包含组合变换的数据集。在每次采样数据集时:
- 动态地文件夹读取数据
- 对读取到的数据应用变换
- 由于有一个变换是随机的,所以可以进行数据增强
可以通过for循环来迭代数据集:
transformed_dataset = FaceLandmarksDataset(csv_file='data/faces/face_landmarks.csv',root_dir='data/faces/',
transform=transforms.Compose([Rescale(256),RandomCrop(224),ToTensor()]))
for i in range(len(transformed_dataset)):
sample = transformed_dataset[i]
print(i,sample['image'].size(),sample['landmarks'].size())
if i==3:
break

但是简单的for循环迭代数据会错失很多功能。尤其是:
- 批量处理数据(Batching the data)
- 清洗数据(Shuffling the data)
- 使用多线程并行加载数据(Load the data in parallel using multiprocessing workers)
torch.utils.data.DataLoader是一个可以提供这些功能的迭代器。被使用的参数应该是清晰明了的。一个感兴趣的参数是collate_fn.可以使用collate_fn指定需要批处理样本的准确度。但对大多数任务,默认的collate可以正常工作。
dataloader = DataLoader(transformed_dataset,batch_size=4,shuffle=True,num_workers=4)
def show_landmarks_batch(sample_batched):
images_batch,landmarks_batch = sample_batched['image'],sample_batched['landmarks']
batch_size = len(images_batch)
im_size = images_batch.size(2)
grid = utils.make_grid(images_batch)
plt.imshow(grid.numpy().transpose((1,2,0)))
for i in range(batch_size):
#x为第i个图片的所有行的第1列,y为第i个图片的所有行的第2列
plt.scatter(landmarks_batch[i,:,0].numpy()+i*im_size,landmarks_batch[i,:,1].numpy(),s=10,marker='.',c='r')
plt.title('Batch from dataloader')
for i_batch,sample_batched in enumerate(dataloader):
print(i_batch,sample_batched['image'].size(),sample_batched['landmarks'].size())
if i_batch == 3:
plt.figure()
show_landmarks_batch(sample_batched)
plt.axis('off')
plt.ioff()
plt.show()
break

