PyTorch入门(六):通过例子学习PyTorch
通过例子学习PyTorch
通过PyTorch的自带例子了解基本概念。
PyTorch有两个主要特征:
- 一个n维的张量,类似于numpy但可以在GPU上运行
- 创建和训练神经网络是可以自动微分
使用一个全连接RELU网络作为例子。该网络有一个单独隐藏层,使用梯度下降适应随机数据,最小化输出和标签的欧氏距离。
张量(Tensors)
引入PyTorch之前,首先用numpy实现网络。
Numpy提供一个n维数组,以及许多操作这些数组的函数。Numpy是一个用于科学计算的通用框架;它对计算图、深度学习或者梯度一无所知。然而,可以很容易地使用numpy适应双层网络,手动实现前向和反向操作。

import numpy as np
#N是batchsize,D_in是输入维度,H是隐藏层的维度,D_out是输出维度
N,D_in,H,D_out = 64,1000,100,10
#创建输入和输出
x = np.random.randn(N,D_in)
y = np.random.randn(N,D_out)
#随机初始权重
w1 = np.random.randn(D_in,H)
w2 = np.random.randn(H,D_out)
lr = 1e-6
for t in range(500):
#前向计算y
h = x.dot(w1)
h_relu = np.maximum(h,0)
y_pred = h_relu.dot(w2)
#计算并输出loss
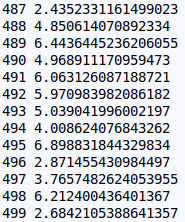
loss = np.square(y_pred-y).sum()
print(t,loss)
#反向计算w1和w2相对于loss的梯度
grad_y_pred = 2.0*(y_pred-y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
#更新权重w1和w2
w1 -= lr*grad_w1
w2 -= lr*grad_w2

PyTorch:Tensors
Numpy框架很棒,但是不能利用GPU加速其数值计算。所以numpy对于深度学习来说不够。
一个PyToech的张量(Tensor)和numpy数组的概念相同:一个张量是一个n维数组,并且PyTorch提供了许多可以对这些张量进行操作的函数。除此之外,Tensors可以跟踪计算图和梯度,而且也可以作为科学计算的通用工具。
与numpy不同,PyTorch的张量可以利用GPUs加速数值计算。要在GPU上运行张量,需要将其转换成新的数据类型。
将上面numpy代码改写为PyTorch tensor版本:
# -*- coding: utf-8 -*-
import torch
dtype = torch.float
device = torch.device('cuda:0')
#N是batchsize,D_in是输入维度,H是隐藏层的维度,D_out是输出维度
N,D_in,H,D_out = 64,1000,100,10
#创建输入和输出
x = torch.randn(N,D_in,device=device,dtype=dtype)
y = torch.randn(N,D_out,device=device,dtype=dtype)
#随机初始权重
w1 = torch.randn(D_in,H,device=device,dtype=dtype)
w2 = torch.randn(H,D_out,device=device,dtype=dtype)
lr = 1e-6
for i in range(500):
h = x.mm(w1)
#torch.clamp(input,min,max,out=None) 将input中的元素限制在[min,max]范围内并返回一个Tensor
h_relu = h.clamp(min=0)
y_pred = h_relu.mm(w2)
#计算并输出loss,通过.item() 从张量中获得 python number
loss = (y_pred-y).pow(2).sum().item()
print(i,loss)
#反向计算w1和w2相对于loss的梯度
grad_y_pred = 2.0*(y_pred-y)
grad_w2 = h_relu.t().mm(grad_y_pred)
grad_h_relu = grad_y_pred.mm(w2.t())
grad_h = grad_h_relu.clone()
grad_h[h<0] = 0
grad_w1 = x.t().mm(grad_h)
# 更新权重w1和w2
w1 -= lr * grad_w1
w2 -= lr * grad_w2
Autograd
使用自动微分自动计算神经网络的反向传播,可以使用Autograd包实现此功能。使用Autograd时,网络的前向传播将定义计算图;图中的节点为张量,边则是从输入张量到产生输出张量的函数。通过此图计算反向传播。
#-*-coding:utf-8-*-
import torch
dtype = torch.float
device = torch.device('cuda:0')
#N是batchsize,D_in是输入维度,H是隐藏层的维度,D_out是输出维度
N, D_in, H, D_out = 64,1000,100,10
#创建随机张量保存输入与输出,利用requires_grad=False表示在反向传递过程中,不需要计算梯度
x = torch.randn(N,D_in,device=device,dtype=dtype)
y = torch.randn(N,D_out,device=device,dtype=dtype)
#随机初始权重,利用requires_grad=True表示在反向传递过程中,需要计算梯度
w1 = torch.randn(D_in,H,device=device,dtype=dtype,requires_grad=True)
w2 = torch.randn(H,D_out,device=device,dtype=dtype,requires_grad=True)
learning_rate = 1e-6
for t in range(500):
#前向传递:通过对Tensors操作计算预测的y,不需要保留对中间值的引用
#h = x.mm(w1)
#h_relu = h.clamp(min=0)
#y = h_relu.mm(w2)
y_pred = x.mm(w1).clamp(min=0).mm(w2)
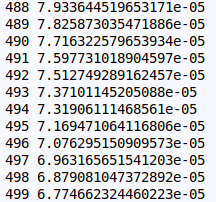
loss = (y_pred-y).pow(2).sum()
print(t,loss.item())
#使用Autograd自动求导
loss.backward()
#使用梯度下降进行权值更新,不需要跟踪求导过程,所以包装在torch.no_grad()
with torch.no_grad():
w1 -= learning_rate*w1.grad
w2 -= learning_rate*w2.grad
w1.grad.zero_()
w2.grad.zero_()
PyTorch:定义新的autograd函数
实际上,每个基本的autograd算子都是两个作用于张量的函数。正向函数从输入张量计算输出张量。后向函数接收输出张量相对于某个标量值的梯度,并计算输入张量相对于该标量值的梯度。
在PyTorch中可以通过定义torch.autograd.Function来定义自己的Autograd操作。
此例中,定义自己的Autograd执行Relu,并且实现自己的双层网络。
#-*-coding:utf-8-*-
import torch
class MyRelu(torch.autograd.Function):
@staticmethod
def forward(ctx, input):
"""
:param ctx:上下文对象,存储用于反向计算的信息,可缓存任意对象
:param input: 一个包含输入的张量
:return: 一个包含输出的张量
"""
ctx.save_for_backward(input)
return input.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
"""
:param ctx:一个上下文对象
:param grad_output:一个包含loss相对于输出的梯度
:return:loss相对于输入的梯度
"""
input = ctx.saved_tensors
grad_input = grad_output.clone()
grad_input[grad_input<0] = 0
return grad_input
dtype = torch.float
device = torch.device('cuda:0')
#N是batchsize,D_in是输入维度,H是隐藏层的维度,D_out是输出维度
N, D_in, H, D_out = 64,1000,100,10
#创建随机张量保存输入与输出,利用requires_grad=False表示在反向传递过程中,不需要计算梯度
x = torch.randn(N,D_in,device=device,dtype=dtype)
y = torch.randn(N,D_out,device=device,dtype=dtype)
#随机初始权重,利用requires_grad=True表示在反向传递过程中,需要计算梯度
w1 = torch.randn(D_in,H,device=device,dtype=dtype,requires_grad=True)
w2 = torch.randn(H,D_out,device=device,dtype=dtype,requires_grad=True)
learning_rate = 1e-6
for t in range(500):
relu = MyRelu.apply
y_pred = relu(x.mm(w1)).mm(w2)
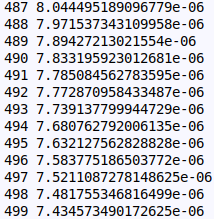
loss = (y_pred-y).pow(2).sum()
print(t,loss.item())
loss.backward()
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
w1.grad.zero_()
w2.grad.zero_()

TensorFlow:Static Graphs(静态图)
PyTorch的autograd与TensorFlow类似,都定义了一个计算图,并使用自动微分计算梯度。两者最大的区别为:TensorFlow的计算图为静态图,PyTorch则使用动态计算图。
在TensorFlow中,我们定义一次计算图,然后反复执行相同的图,可能向图提供不同的输入数据。在PyTorch中,每个前向传递都定义一个新的计算图。
静态图的优点在于可以预先优化图。例如:为了更高效,一个框架可能会融合一些图操作,或者将一种图分不到多个gpu或多台机器。静态图和动态图的不同在于控制流。
#-*-coding:utf8-*-
import tensorflow as tf
import numpy as np
N,D_in,H,D_out = 64,1000,100,10
x = tf.placeholder(dtype=tf.float32,shape=(None,D_in))
y = tf.placeholder(dtype=tf.float32,shape=(None,D_out))
w1 = tf.Variable(tf.random_normal((D_in, H)))
w2 = tf.Variable(tf.random_normal((H,D_out)))
h = tf.matmul(x,w1)
h_relu = tf.maximum(h,tf.zeros(1))
y_pred = tf.matmul(h_relu,w2)
loss = tf.reduce_sum((y_pred-y)**2.0)
w1_grad,w2_grad = tf.gradients(loss,[w1,w2])
lr = 1e-6
new_w1 = w1.assign(w1-lr*w1_grad)
new_w2 = w2.assign(w2-lr*w2_grad)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
x_value = np.random.randn(N,D_in)
y_value = np.random.randn(N,D_out)
for _ in range(500):
loss_value,_, _ = sess.run(fetches=[loss,new_w1,new_w2],feed_dict={x:x_value,y:y_value})
print(loss_value)

PyTorch:nn
对于大型神经网络,原始Autograd过于低级。构建神经网络时,可以考虑将计算安排到层中,其中的一些层具有可学习的参数,这些参数在学习期间优化。
在TensorfFlow中,例如keras,TensorFlow-Slim和TFLearn这样的软件包提供了对构建神经网络有用的原始计算图形的更高级别的抽象。
在PyTorch中,nn包有相同的作用。nn包定义了一些模块,类似与神经网络层,模块接受输入张量,计算输出张量,但也可以保持内部状态,例如包含可学习参数的张量。 nn包还定义了一组在训练神经网络时常用的损失函数。
#-*-coding:utf-8-*-
import torch
import torch.nn as nn
N,D_in,H,D_out = 64,1000,100,10
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out),)
loss_fn = nn.MSELoss(reduction='sum')
lr = 1e-4
for i in range(500):
y_pred = model(x)
loss = loss_fn(y_pred,y)
print(i,loss.item())
model.zero_grad()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param -= lr*param.grad
PyTorch: optim
PyTorch中的optim包提取了优化算法的思想,并且实现了常用的优化算法。
#-*-coding:utf-8-*-
import torch
import torch.nn as nn
import torch.optim as optim
N,D_in,H,D_out = 64,1000,100,10
x = torch.randn(N,D_in)
y = torch.randn(N,D_out)
model = nn.Sequential(
nn.Linear(D_in,H),
nn.ReLU(),
nn.Linear(H,D_out),)
loss_fn = nn.MSELoss(reduction='sum')
lr = 1e-4
optimizer = optim.Adam(model.parameters(), lr=lr)
for i in range(500):
y_pred = model(x)
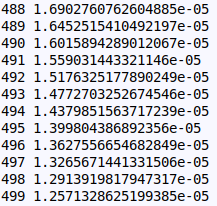
loss = loss_fn(y_pred,y)
print(i,loss.item())
model.zero_grad()
loss.backward()
optimizer.step()
PyTorch: Custom nn Modules
通过继承torch.nn,利用其他模块或者对张量进行autograd操作接受输入张量并且产生输出张量进行前向传递,定义自己自己的模块。
#-*-coding:utf-8-*-
import torch
import torch.nn as nn
import torch.optim as optim
class Net(nn.Module):
def __init__(self, D_in, H, D_out):
super(Net,self).__init__()
self.linear1 = nn.Linear(D_in,H)
self.linear2 = nn.Linear(H,D_out)
def forward(self, x):
h_relu = self.linear1(x).clamp(min=0)
y_pred = self.linear2(h_relu)
return y_pred
N, D_in, H, D_out = 64,1000,100,10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = Net(D_in,H,D_out)
criterion = nn.MSELoss(reduction='sum')
optimizer = optim.SGD(model.parameters(),lr=1e-4)
for i in range(500):
y_pred = model(x)
loss = criterion(y_pred,y)
print(i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()

PyTorch: Control Flow + Weight Sharing
作为动态图和权值共享的例子,实现了一个奇怪的模型:一个全连接的Relu网络,在每个前向传递上选择1到4的随机数并使用这么多的隐藏层,重复使用相同的权值多次,计算最里面的隐藏层。
对于这个模型,我们可以使用普通的Python流控制来实现循环,并且我们可以通过在定义正向传递时多次重复使用相同的模块来实现最内层之间的权重共享。
#-*-coding:utf-8-*-
import torch
import torch.nn as nn
import torch.optim as optim
import random
class DynamicNet(nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_Linear = nn.Linear(D_in,H)
self.middle_Linear = nn.Linear(H,H)
self.output_Linear = nn.Linear(H,D_out)
def forward(self, x):
h_relu = self.input_Linear(x).clamp(min=0)
for i in range(random.randint(0,3)):
h_relu = self.middle_Linear(h_relu).clamp(min=0)
y_pred = self.output_Linear(h_relu)
return y_pred
N, D_in, H, D_out = 64,1000,100,10
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = DynamicNet(D_in,H,D_out)
criterion = nn.MSELoss(reduction='sum')
optimizer = optim.SGD(model.parameters(),lr=1e-4)
for i in range(500):
y_pred = model(x)
loss = criterion(y_pred,y)
print(i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()