第二十九周:文献阅读笔记(ResMLP)+ pytorch学习(Resnet代码实现)
第二十九周:文献阅读笔记(ResMLP)
- 摘要
- Abstract
- 1. ResMLP
-
- 1.1 文献摘要
- 1.2 文献引言
- 1.3 ResMLP方法
-
- 1.3.1 整体流程
- 1.3.2 残差多感知机层
- 1.4 实验
-
- 1.4.1 数据集
- 1.4.2 超参数设置
- 1.4.3 主要结果
- 1.4.4 监督设置
- 1.4.5 自监督设置
- 1.4.5 知识蒸馏设置
- 1.5 ResMLP的创新点
- 2. pytorch学习(ResNet代码实现)
-
- 2.1 数据集
- 2.2 文件结构
- 2.3 下载并加载数据集
- 2.4 ResNet-18 网络架构
- 2.5 训练
- 2.6 训练结果
- 2.7 完整代码
- 总结
摘要
MLP是多层感知机是一种常用的神经网络模型。MLP可以用于分类、回归和聚类等任务,并且具有良好的泛化能力,MLP由多层感知器组成,感知器是一种线性分类器,可以学习并识别简单的模式,通过将多个感知器组合在一起,MLP可以学习并识别更复杂的模式。而本文介绍的ResMLP(Residual MLP)是一种对MLP的改进模型,主要针对MLP的缺点进行了优化,通过引入残差连接,使得模型在训练过程中更容易跳出局部最小值,提高了模型的收敛速度和稳定性。同时,ResMLP通过减少模型的层数和神经元数量,简化了模型的结构,使得模型的训练过程更加稳定,并且减少了计算资源和存储空间的消耗。本文将对 ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training 这篇文献作出详细的解析。
Abstract
MLP is Multilayer Perceptron is a commonly used neural network model.MLP can be used for tasks such as classification, regression and clustering and has good generalization ability.MLP consists of multilayer perceptron.Perceptron is a linear classifier that can learn and recognize simple patterns.By combining multiple perceptrons together,MLP can learn and recognize more complex patterns. And ResMLP (Residual MLP) introduced in this paper is an improved model of MLP, which is mainly optimized for the shortcomings of MLP, and by introducing residual connection, it makes the model easier to jump out of the local minima during the training process, and improves the convergence speed and stability of the model. Meanwhile, ResMLP simplifies the structure of the model by reducing the number of layers and neurons in the model, which makes the training process of the model more stable and reduces the consumption of computational resources and storage space. In this paper, we will give a detailed analysis of the paper ResMLP: Feedforward Networks for Image Classification With Data-Efficient Training.
1. ResMLP
文献:ResMLP: Feedforward Networks for Image
Classification With Data-Efficient Training
1.1 文献摘要
作者团队提出了 ResMLP,这是一种完全基于多层感知器来进行图像分类。它是一个简单的残差网络,交替使用以下功能:线性层其中的图像patch在不同通道间独立地相互作用,以及和两层前馈网络其中通道的每个图像patch独立互动。当使用大量数据增强和可选蒸馏的现代训练策略进行训练时,它在ImageNet上获得了令人惊讶的良好准确性/复杂性权衡。
1.2 文献引言
最近,Transformer架构在计算机视觉领域得到了广泛的应用,例如我们之前学习的VIT、Swin-Transformer等模型,在ImageNet数据集上均取得的十分优秀的成绩。在使用较少先验学习视觉特征方面又迈进了一步: 卷积神经网络(CNN)用灵活可训练的架构取代了手工设计的硬连线特征选择。
视觉转换器进一步移除了卷积架构中的几个硬性决定,卷积架构中的几个硬性决定,即翻译不变性和局部连接性。
【注】手工设计的硬连线特征选择:手工设计的硬连线特征选择是指在机器学习领域中,通过人工选择特定的特征(features)来帮助模型进行预测或分类任务。通常情况下,特征选择是指从原始数据中选择最相关或最有代表性的特征,以便提高模型的性能和效率。硬连线特征选择指的是在特征选择过程中,人工明确地指定使用哪些特征,而非让模型通过学习数据来自行选择特征。这种方法可能包括领域知识的运用、经验法则或者专家意见,以便直接确定最重要的特征,从而精炼模型并提高其解释性。
在本文中,作者通过展示一种纯粹的基于多层感知器(MLP)的架构(称为残差多层感知器(ResMLP))来进一步推动这一趋势,在图像分类方面具有竞争力。它采用展平后的 N ∗ N N*N N∗N 个图像 pathc 作为输入,他们直接相互独立,通过线性层对其进行映射为 N 2 N^2 N2 的d维嵌入特征,然后采用两个残差操作对投影特征进行更新:(i)一个简单的线性 patch 交互层,独立用于所有通道;(ii)带有单一隐藏层的 MLP,独立用于所有 patch。在网络的末端,这些 patch 被平均池化,进而输入线性分类器。然后将输出的 N 2 N^2 N2 的d维嵌入特征进行平均得到d维图像表达,最后将图像表达送入线性分类层预测图像对应标签,训练使用交叉熵损失。
ResMLP架构受到 ViT 的强烈启发,但它在几个方面要简单得多:用线性层取代自注意力层,从而产生一个只有线性层和GELU非线性的架构。使用线性层的优点是,仍然可以可视化补丁嵌入之间的相互作用,揭示类似于较低层上的卷积的过滤器,以及最后一层中的更长范围。
由于 ResMLP 的线性特性,模型中的 patch 交互可以很容易地进行可视化、可解释。尽管第一层学习到的交互模式与小型卷积滤波器非常类似,研究者在更深层观察到 patch 间更微妙的交互作用,这些包括某些形式的轴向滤波器(axial filters)以及网络早期长期交互。
1.3 ResMLP方法
ResMLP 的具体架构如下图 1 所示,采用了路径展平(flattening)结构:

1.3.1 整体流程
作者提出的模型用 ResMLP 表示,采用 N ∗ N N*N N∗N 个不重叠patch的网格作为输入,其中 patch size 通常等于 16 ∗ 16 16*16 16∗16。然后,patch独立地通过线性层以形成一组 N 2 N^2 N2 的 d 维嵌入。所得的 N 2 N^2 N2 的嵌入集被输入到一系列残差多层感知器层,以生成一组 N 2 N^2 N2 的d 维输出嵌入。然后将这些输出嵌入进行平均(“平均池化”)作为 d 维向量来表示图像,该向量被馈送到线性分类器以预测与图像关联的标签,训练使用交叉熵损失剩余的多感知器层。
1.3.2 残差多感知机层
多感知器层:该网络是一系列具有相同结构的层:线性子层 + 前馈子层。与 Transformer 层类似,每个子层都与一个跳跃连接(skip-connection)并行。没有自注意力层使训练更加稳定,使我们能够用更简单的仿射变换替换层归一化,由此可见研究者在该层中并未使用层归一化,这是因为当使用下面的公式中的 Affine 转换时,即使没有层归一化,训练也是稳定的。 A f f α , β = D i a g ( α ) x + β Aff_{\alpha,\beta}=Diag(\alpha)x+\beta Affα,β=Diag(α)x+β其中 α \alpha α 和 β \beta β 是可学习的权重向量。此操作仅按元素重新缩放和移动输入。与其他归一化操作相比,此操作有几个优点:
- 与层归一化相反,它在推理时没有成本,因为它可以被吸收到相邻的线性层中。
Affine转换(如仿射变换)通常是 在网络的某个层中应用的线性变换操作,例如矩阵乘法和偏置相加。这些操作可以很高效地实现,因此在推理时的计算成本相对较低。
层归一化(Layer Normalization)是一种应用于每个层的归一化操作,旨在解决神经网络训练中的 内部协变量偏移问题。它涉及到对每个样本在特定维度上进行归一化操作,通常需要一定的计算量来计算均值和方差,并且需要一些额外的运算,如平方根和除法。因此,在推理阶段,层归一化会增加一些计算成本。
- 与 BatchNorm 和 Layer Normalization 不同,Aff 算子不依赖于批量统计数据。
- 与 Aff 更接近的算子是 Touvron 等人引入的 LayerScale。还有一个额外的偏差项。
在数学和计算机科学中,“Aff” 算子通常指的是仿射变换(Affine Transformation)。仿射变换是从一个向量空间到另一个向量空间的一种几何变换,它包括了平移、旋转、缩放和剪切等操作。在图像处理、计算机图形学和机器学习等领域,仿射变换被广泛应用于对图像和数据进行变换和处理。
为方便起见,作者采用 A f f ( X ) Aff(X) Aff(X) 表示独立应用于矩阵 X X X 的每一列的仿射运算(each column of the matrix)。
我们在每个残差块的开始(“pre-normalization”)和结束(“post-normalization”)应用 Aff 算子。作为前归一化(pre-normalization),Aff 替换了 LayerNorm 而不使用通道统计。在这里,初始化 α = 1 \alpha = 1 α=1 和 β = 0 \beta = 0 β=0。作为后归一化(post-normalization),Aff 类似于 LayerScale。
简单概括就是,LayerScale 通过缩放输入张量来归一化层之间的输出。顾名思义,这个模块主要是起一个缩放作用,通过缩放输入张量来归一化层之间的输出。在 ViT 模型中,每个注意力层 (Attention Layer) 后面都连接了一个全连接层(MLP Layer),而这两层的输出可能差异很大。因此为了避免深度学习网络中出现梯度消失或爆炸的情况,需要对这两层的输出进行标准化。CaiT中 LayerScale 在每个残差块的输出上添加一个可学习的对角矩阵,该矩阵被初始化为接近0。在每个残差块之后添加这个简单的层可以提高训练的动态性,能够训练更深层次的大容量,它在训练时向网络添加了数千个参数

总体而言,作者提出的多层感知器将一组 N 2 N^{2} N2 个 d 维嵌入特征堆叠在一个 d ∗ N 2 d*N^2 d∗N2 矩阵 X X X 中,并输入一组 N 2 N^2 N2 个 d 维输出特征,堆叠在一个矩阵 Y Y Y 中,其中包含以下集合转换:

其中 A , B A,B A,B 和 C C C 是该层的主要可学习权重矩阵。等式 Y = Z + A f f ( C ∗ G E L U ( B ∗ A f f ( Z ) ) ) Y=Z+Aff(C*GELU(B*Aff(Z))) Y=Z+Aff(C∗GELU(B∗Aff(Z))) 与 Transformer 的前馈子层相同,其中 ReLU 非线性被 GELU 函数取代。参数矩阵 A A A 的维度为 N 2 ∗ N 2 N^2*N^2 N2∗N2,即这个“跨补丁”子层在补丁之间交换信息,而“跨通道”前馈子层针对每个位置工作。与 Transformer 类似,中间激活矩阵 Z 与输入和输出矩阵 X 和 Y 具有相同的维度。最后,权重矩阵 B 和 C 具有与 Transformer 层中相同的维度,分别为 4 d ∗ d 4d*d 4d∗d 和 d ∗ 4 d d*4d d∗4d 。
与 Vision Transformer 架构的差异。作者所提出的架构与 ViT 模型 密切相关。然而,ResMLP 与 ViT 不同,做了一些简化:
- 没有self-attention blocks:它被一个没有非线性的线性层取代
- 没有位置嵌入:线性层隐含地编码关于patch位置的信息
- 没有额外的“类”标记:只是在patch上使用平均池化嵌入
- 没有基于批量统计的归一化:使用可学习的仿射算子
Class-MLP 作为平均池化的替代方案。作者建议对 CaiT 中引入的类注意力标记(class-attention token)进行改编。在 CaiT 中,这由两层组成,它们具有与 Transformer 相同的结构,但其中仅基于冻结的补丁嵌入(frozen patch embeddings)更新类标记。我们将这种方法应用到我们的架构中,除了在用线性层聚合补丁之后,我们用简单的线性层替换类和补丁嵌入之间基于注意力的交互,仍然保持补丁嵌入冻结。这会提高性能,但会增加一些参数和计算成本。我们将这种池化变体称为“class-MLP”,因为这几层的目的是取代平均池化。
序列到序列 ResMLP:与 Transformer 类似,ResMLP 架构可以应用于序列到序列的任务。首先,我们遵循的通用编码器-解码器架构,用残差多感知器层替换了自注意力子层。在解码器中,我们保留了关注编码器输出的交叉注意力子层。在解码器中,我们通过将矩阵 A 约束为三角形来使线性子层适应语言建模的任务,以防止给定的标记表示将来访问标记。最后,在序列到序列模型中使用线性子层的主要技术困难是处理可变序列长度。然而,我们观察到,简单地用零填充并提取对应于批处理中最长序列的子矩阵 A,在实践中效果很好。
1.4 实验
1.4.1 数据集
我们在 ImageNet-1k 数据集上训练我们的模型,该数据集包含均匀分布在 1,000 个对象类别上的 120 万张图像。在此基准没有可用的测试集的情况下,我们通过报告验证集的性能来遵循社区的标准做法。这并不理想,因为验证集最初是为选择超参数而设计的。在这组上比较方法可能不够确定,因为性能的提高可能不是由更好的建模引起的,而是由更好的超参数选择引起的。为了降低这种风险,作者在该文献中报告了迁移学习和两个替代版本的 ImageNet 的额外结果,这些版本具有不同的验证和测试集,即 ImageNet-real 和 ImageNet-v2 数据集。在 ImageNet-21k 上训练时,还报告了一些数据点。
1.4.2 超参数设置
在监督学习的情况下,我们使用 Lamb 优化器 训练网络,学习率为 5 × 1 0 − 3 5×10^{−3} 5×10−3,权重衰减为 0.2。作者按照 CaiT 将 LayerScale 参数初始化为深度的函数。其余的超参数遵循 DeiT 中使用的默认设置。对于知识蒸馏范式,我们使用与 DeiT 中相同的 RegNety-16GF 和相同的训练计划。我们的大多数模型需要两天时间才能在 8 个 V100-32GB GPU 上进行训练。
1.4.3 主要结果
作者将 ResMLP 与基于卷积或自注意力的架构进行比较,在 ImageNet 上具有可比的大小和吞吐量。
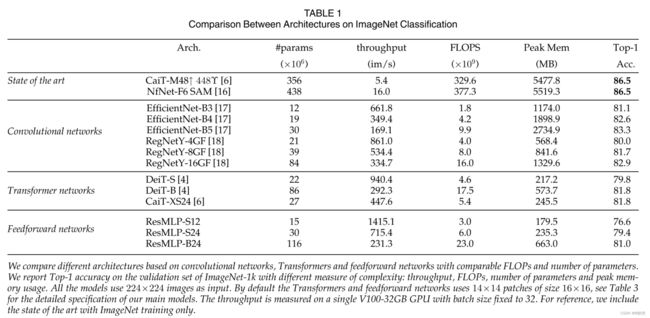
1.4.4 监督设置
在表 1 中,我们将 ResMLP 与不同的卷积和 Transformer 架构进行了比较。为了完整起见,我们还报告了仅在 ImageNet 上训练的模型获得的最佳发布数字。虽然 ResMLP 的准确度、FLOP 和吞吐量之间的权衡不如卷积网络或 Transformer,但它们的高准确度仍然表明层设计施加的结构约束对性能没有太大影响,尤其是在训练时有足够的数据和最近的训练计划。

1.4.5 自监督设置
我们在 300 个 epoch 期间使用称为 DINO [7] 的自我监督方法对 ResMLP-S12 进行了预训练。我们在表 2 中报告了我们的结果。趋势类似于监督设置:使用 ResMLP 获得的准确度低于 ViT。然而,对于纯 MLP 架构,性能出奇地高,并且在 k-NN 评估中与 Convnet 具有竞争力。此外,我们还使用真实标签在 ImageNet 上通过自监督对网络进行了微调。与仅使用标签训练的 ResMLP-S24 相比,预训练显着提高了性能,在 ImageNet-val 上实现了 79.9% 的 top-1 准确率(+0.5%)。

1.4.5 知识蒸馏设置
我们在使用 [56] 的知识蒸馏方法进行训练时研究我们的模型。在他们的工作中,作者展示了通过从 RegNet 中提取 ViT 模型来训练它的影响。在这个实验中,我们探索 ResMLP 是否也从这个过程中受益,并将我们的结果总结在表 3 中(块“基线模型”和“训练”)。我们观察到,与 DeiT 模型类似,ResMLP 极大地受益于从卷积网络中提取。这一结果与 [14] 的观察结果一致,他使用卷积网络来初始化前馈网络。尽管我们的设置在规模上与他们的设置不同,但 ImageNet 上仍然存在前馈网络的过拟合问题。从蒸馏中获得的额外正则化是这种改进的可能解释。
1.5 ResMLP的创新点
ResNet 引入了残差连接,通过将输入直接添加到网络中间层的输出,从而允许网络学习残差(即实际输出与期望输出的差异),这样可以避免梯度消失和梯度爆炸的问题,使得训练更加稳定。作者在该文献中提出了残差学习的概念,即网络的目标是学习使得输入可以直接映射到期望输出的残差(即期望输出与实际输出之间的差异),而不是直接学习整个映射关系,这种设计使得网络更容易学习。同时这种设计允许了更深层次的特征表示,提高了网络的表达能力。这些创新点使得 ResNet 在图像识别等任务上取得了非常好的效果,成为了当今深度学习领域的经典模型之一。
2. pytorch学习(ResNet代码实现)
2.1 数据集
本次实验数据集采用CIFAR-10,CIFAR-10是由Hinton的学生Alex Krizhevsky和Ilya Sutskever整理的一个用于识别普适物体的小型数据集。这个数据集包含10个类别的RGB彩色图片,包括飞机、汽车、鸟类、猫、鹿、狗、蛙类、马、船和卡车。图片的尺寸为32×32,数据集中一共有50000张训练图片和10000张测试图片。
2.2 文件结构
2.3 下载并加载数据集
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./train_data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./test_data", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
2.4 ResNet-18 网络架构
import torch
import torch.nn as nn
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(nn.Conv2d(in_channels,out_channels,stride=stride,kernel_size=1, bias=False), nn.BatchNorm2d(out_channels))
def forward(self, x):
idenity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(idenity)
return out
class ResNet18(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=True)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 2, stride=1)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
layer = []
layer.append(ResidualBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
layer.append(ResidualBlock(out_channels, out_channels))
return nn.Sequential(*layer)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
model = ResNet18()
print(model)
2.5 训练
# 创建网络模型
Test_module = ResNet18()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(Test_module.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1))
for data in train_dataloader:
# 训练步骤开始
imgs, targets = data
outputs = Test_module(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_test_step)
# 测试步骤开始
total_test_loss = 0
# 整体的正确率
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = Test_module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存训练的模型
torch.save(Test_module, "Test_module_{}.pth".format(i))
print("模型已保存")
writer.close()
2.6 训练结果
一共训练了10轮,在测试集上进行验证,准确率达到了70%


通过测试集进行验证后,可以发现明显出现过拟合的现象
解决过拟合的方法有以下方式:
- 增加训练数据集:增加数据集的大小可以让模型更好地学习样本的分布,从而降低过拟合的风险。
- 简化模型:简化模型可以减少模型的复杂度,降低过拟合的风险。可以通过减少特征数量、减小模型的深度或宽度等方式实现。
- 正则化:正则化是对模型的参数进行惩罚,以防止过度拟合。L1正则化可以使部分特征的权重为0,L2正则化可以使特征权重尽量接近0。
- 早停法(Early Stopping):早停法是一种通过提前结束训练来防止过拟合的方法。在训练过程中,我们可以定期评估验证集的性能,一旦验证集的性能开始下降,就停止训练。这种方法可以防止模型在训练集上过度拟合,保留更多的泛化能力。
- Dropout:Dropout是一种正则化技术,通过在训练过程中随机丢弃神经元的输出来防止过拟合。Dropout可以看作是一种集成学习的方法,通过结合多个不同的神经网络模型来提高模型的泛化能力。
- 数据增强:数据增强是通过生成更多的训练数据来防止过拟合的方法。可以通过对原始数据进行旋转、平移、缩放等操作来生成新的数据,增加模型的泛化能力。
2.7 完整代码
model.py
import torch
import torch.nn as nn
# Residual block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(nn.Conv2d(in_channels,out_channels,stride=stride,kernel_size=1, bias=False), nn.BatchNorm2d(out_channels))
def forward(self, x):
idenity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += self.shortcut(idenity)
return out
class ResNet18(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=True)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 2, stride=1)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
layer = []
layer.append(ResidualBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
layer.append(ResidualBlock(out_channels, out_channels))
return nn.Sequential(*layer)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
model = ResNet18()
print(model)
main.py
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import *
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./train_data", train=True, transform=torchvision.transforms.ToTensor(), download=True)
test_data = torchvision.datasets.CIFAR10(root="./test_data", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
Test_module = ResNet18()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(Test_module.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1))
for data in train_dataloader:
# 训练步骤开始
imgs, targets = data
outputs = Test_module(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
print("训练次数:{}, loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_test_step)
# 测试步骤开始
total_test_loss = 0
# 整体的正确率
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = Test_module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
# 保存训练的模型
torch.save(Test_module, "Test_module_{}.pth".format(i))
print("模型已保存")
writer.close()
总结
这周通过该文献对 ResMLP 有了一定的了解,同时基于 CIFAR-10 数据集对 Resnet 进行了代码实现,进一步加深了对 Resnet 网络架构的理解。下周我会继续努力~