python爬虫之获取QQ关系网(超级详细)
一、背景: 继上次QQ空间登陆后获取QQ好友、群友、群信息之后,需求又扩大了,变成了获取QQ关系网,什么意思呢:就是给你一个QQ,然后从这个QQ出发,通过该QQ的说说、点赞、评论获取该QQ有过交集的人,保存他们的账号信息用来作为下次的起点。这样爬取下来就很像一张网一样,所有叫做QQ关系网。
二、前提: 在开始之前我建议先去看一下我上次的QQ空间登陆获取信息的博客:python爬虫之QQ空间登陆获取信息(超级详细),详细介绍了QQ空间的登陆步骤和一些重要参数的破解。
三、问题: 这篇文章主要是在之前的登陆之上进行扩展的,如果你成功登陆了,获取QQ关系网应该是比较简单的。但是,有这么几个问题:
问题一:如果采用单进程,步骤不会乱,但是效率太低太低了。
问题二:采用多任务,多进程要怎么创建会比较合理,或者怎么让服务器承受得了。多进程加多线程会怎么样呢?
问题三:多任务数据会不会混乱?要怎么设计程序让数据保持正确?
问题四:我这里条件有限,直接淘汰了分布式,只有一台机器性能一般。
四、分析: 基于以上,我自己采用了进程池+队列(一个),进程池最多10个进程。为什么采用进程池+队列呢?
原因:在这个场景中队列的放>拿,进程池可以有效限制工作进程的数量。所以当一个一轮获取完成之后,我只拿10个数据出来处理,其余的数据保存在队列中,达到缓存的目的,这样就解决了以上的大部分问题(不要杠,条件有限),其他的细节我后面再分享一下。
优化:
1、在获取说说的时候我是采用一条说说获取完内容、评论、转发、点赞数据之后,将说说内容保存到数据库,而对于评论、转发、点赞主要是要获取他们的QQ号码和昵称,我把它们分离后将QQ账号放入队列中,方便下次爬虫创建关系网。
2、在每次从进程池里面拿一个进程出来的时候,先对这个QQ(QQ账号是唯一的)进行判断如果已经爬取过了,我就跳过而且不放入队列中,这样就等于重复的不做爬虫处理,这样就提升了程序的性能,而且大大节省爬取时间。
3、主程序是采用死循环一直再创建进程的,我们要定义个结束的标志。(还有其他的小优化在源码中可以认真体会下)
几个接口:
说说接口:https://user.qzone.qq.com/proxy/domain/taotao.qq.com/cgi-bin/emotion_cgi_msglist_v6
所需参数:
 uin:当前要爬取的QQ账号。
uin:当前要爬取的QQ账号。
g_tk:登陆的时候获取,可以去看我的博客python爬虫之QQ空间登陆获取信息(超级详细)t_gk获取过程,后面就不再赘述了。
pos:页码,从0开始每次加20。
点赞接口: https://user.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/user/qz_opcnt2
所需参数:

_stp:当前时间。
unikey:说说对应的key,每个说说都不同,要在爬取说说的时候获取。
g_tk:不再赘述。
获取unikey: 全局搜索会发现下面两个js文件:

UGCLikeButton.js: 在这个js文件中会发现:
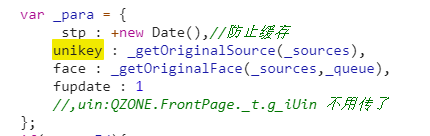
这些不就是点赞接口的参数吗,往下继续寻找会发现unikey参数的拼接过程:

ps:其实这个拼接过程不是很重要,因为参数可以不用这样拼接,经过多次试验后发现的,直接传递参数就行了。
api.js: 这个js文件才是关键,unikey参数的由来:
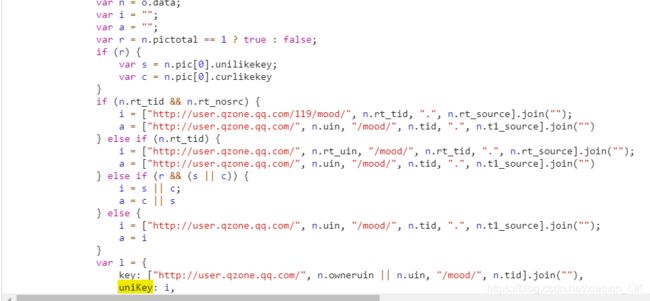
OK,查看api.js的所有代码会发现:n其实就是说说接口的返回的xhr里面的响应内容,那接下来我就用python语言实现以下这个代码的功能,拼接出unikey的参数:
def crack_unikey(msg, g_tk):
r = True if msg.get("pictotal") == 1 else False
s = None
c = None
if (r):
s = msg.get("pic")[0].get("unilikekey")
c = msg.get("pic")[0].get("curlikekey")
if msg.get("rt_tid") and msg.get("rt_nosrc"):
key1 = "http://user.qzone.qq.com/119/mood/" + str(msg.get("rt_tid")) + "." + str(msg.get("rt_source"))
key2 = "http://user.qzone.qq.com/" + str(msg.get("uin")) + "/mood/" + str(msg.get("tid")) + "." + str(
msg.get("t1_source"))
elif msg.get("rt_tid"):
key1 = "http://user.qzone.qq.com/" + str(msg.get("rt_uin")) + "/mood/" + str(msg.get("rt_tid")) + "." + str(
msg.get("rt_source"))
key2 = "http://user.qzone.qq.com/" + str(msg.get("uin")) + "/mood/" + str(msg.get("tid")) + "." + str(
msg.get("t1_source"))
elif (r and (s or c)):
key1 = s or c
key2 = c or s
else:
key1 = "http://user.qzone.qq.com/" + str(msg.get("uin")) + "/mood/" + str(msg.get("tid")) + "." + str(
msg.get("t1_source"))
key2 = "http://user.qzone.qq.com/" + str(msg.get("uin")) + "/mood/" + str(msg.get("tid")) + "." + str(
msg.get("t1_source"))
params = {
"_stp": str(time.time() * 1000),
"unikey": key1 + key2,
"face": "0<|>0<|>0<|>0<|>0<|>0<|>0<|>0<|>0<|>0",
"fupdate": "1",
"g_tk": g_tk
}
return params
OK,这样就获取到了点赞接口的参数了,然后就可以请求点赞接口的数据了。剩下的说说内容、评论内容、转发内容等等都在说说接口里面了,对返回的数据稍加处理就可以得到想要的所有数据了,这里就不具体说明了,感兴趣的可以去我的github上面查看源码。
程序的执行流程:
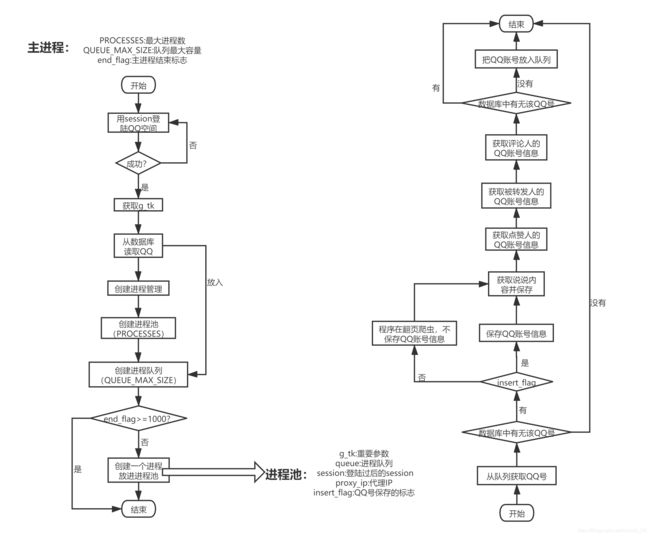
主程序开始的时候给他指定开始的点,即QQ账号保存到进程队列中,然后循环创建队列放入进程池中,由进程池完成每个子进程。而子进程的主要任务是获取说说内容、评论人的QQ信息、点赞人的QQ信息,进行判断,把需要的保存到数据库和队列中。
五、实现:
数据库创建:
create table qquser(
id int auto_increment primary key,
uin int(11) unique,
nick char(32),
break tinyint(1)
)charset=utf8;
create table qqsaysay(
id int auto_increment primary key,
uin int(11),
saysay text,
img text
)charset=utf8;
源码:
https://github.com/A-dying-ape/demo/tree/master/%E8%8E%B7%E5%8F%96QQ%E5%85%B3%E7%B3%BB%E7%BD%91
六、总结:
其实在成功登陆空间之后其他的数据都非常好获取,就是JS代码转换为python语言的时候有点费劲,这篇文章我觉得比较不好搞的就是能unikey参数了,但是我觉得在完成这个需求的时候让我最有成就感的是程序的设计上面,虽然公司的条件有限,但我还是可以比较完美设计出较优的程序。