慕课网JavaScript正则表达式学习笔记
慕课网JavaScript正则表达式学习笔记
1.正则表达式的对象
JavaScript通过内置对象RegExp支持正则表达式,有两种方式实例化RegExp对象
(1)字面量
var reg = /\bis\b/g
正则表达式写在两个顺斜线/之间,\b表示单词边界,这样is就只对应is这个单词,不能对应this,g是修饰符表示全文搜索,不添加的话,搜索匹配到第一个就停止
(2)构造函数
var reg = new RegExp(‘\bis\b’,’g’)
这里的反斜线用了两次,因为js中反斜线本身就是特殊字符,如果要使用的话就需要转义
2. 修饰符
g:global全文搜索,不添加的话,搜索匹配到第一个就停止
i:ignore case忽略大小写,默认大小写敏感
m:multiple lines多行搜索
3. 元字符
正则表达式由两种基本字符类型组成
(1)原义文本字符
(2)元字符:是在正则表达式中有特殊含义的非字母字符,如:* + ? $ ^ . | \ ( ) { } [ ]

4. 字符类
一般情况下正则表达式一个字符对应字符串一个字符
我们可以用元字符[]来构建一个简单的类,所谓类就是符合某些特征的对象,一个泛指,而不是特指某个字符,如:表达式[abc]把字符a或b或c归为类,表达式可以匹配这类字符,如:


5. 字符类取反
使用元字符^创建反向类/负向类(反向类的意思是不属于某类的内容),如:表达式[^abc]表示不是字符a或b或c的内容

6. 范围类
正则表达式给我们提供了范围类,所以我们可以用[a-z]来连接两个字符表示从a到z的任意字符,这是一个闭区间,也就是包含a和z本身

在[]组成的类内部是可以连写的[a-zA-Z]

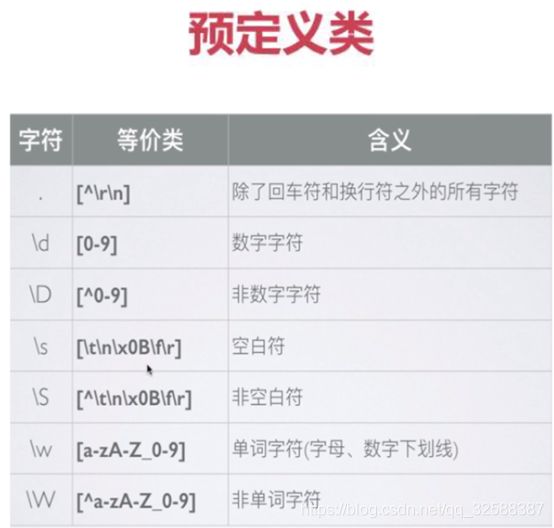
7. 预定义类
正则表达式提供预定义类来匹配常见的字符
8. 边界
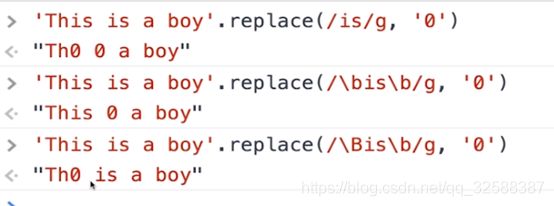
正则表达式还提供了几个常用的边界匹配字符

如:

9. 量词


10. 贪婪模式(默认)
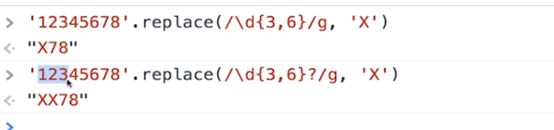
正则表达式尽可能多的匹配,如下面的例子,数字出现3到6次,就是说3,4,5,6次都可以,但是正则表达式在匹配的时候会尽可能多的去匹配

11. 非贪婪模式
让正则表达式尽可能少的匹配,也就是说一旦匹配成功就不再继续尝试,这就是非贪婪模式,如果想让贪婪模式变成非贪婪模式,在量词后面加上?号就可以了,例如:

12. 分组
使用()可以达到分组的功能,让量词作用于分组

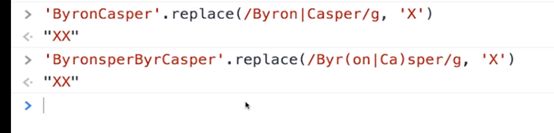
13. 或
正则表达式用|可以达到或的功能
14. 反向引用

15. 忽略分组
不希望捕获某些分组,只需要在分组内加上?:就可以,如下面虽然有两个(),但是只有OK这一个分组
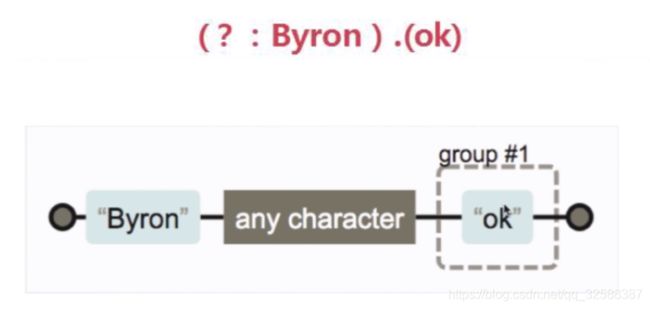
前瞻
正则表达式从文本头部向尾部开始解析,文本尾部方向称为“前”
前瞻就是在正则表达式匹配到规则的时候,向前检查是否符合断言(断言就是前瞻语法的一部分),后顾/后瞻反向相反
JavaScript不支持后顾
符合和不符合特定断言称为肯定/正向匹配和否定/负向匹配


JavaScript对象属性
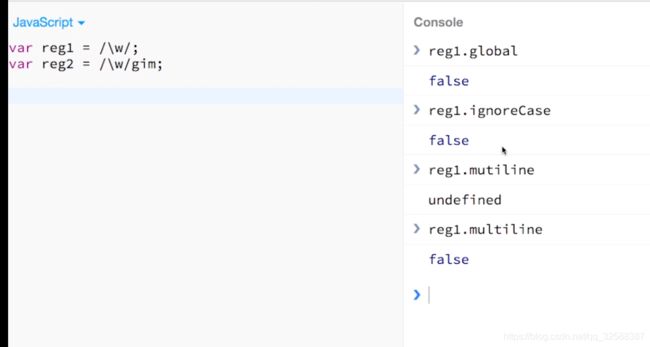
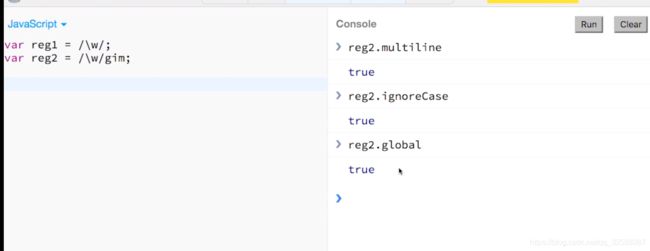
global:是否全文搜索,默认false
ignore:是否大小写敏感,默认false(也就是大小写敏感)
multiline:多行搜索,默认false
lastIndex:是正则表达式当前匹配内容的最后一个字符的下一个位置(在非全局的情况下lastIndex不生效)
source:正则表达式的文本字符串
注:lastIndex可以解释正则表达式“结果不稳定的原因”,例如
var reg = /\w/g
reg.test(‘ab’)执行两次以后就返回false了,原因是,该正则表达式当前匹配结果是a,a的下一个字符是b,所以lastIndex是1,第二次执行匹配内容是b,他的下一个字符的lastIndex是2,正则表达式每一次匹配并不是从头开始的

test(RegExp.prototype.test(str))方法
用于测试字符串参数中是否存在匹配正则表达式模式的字符串,如果存在就返回true,否则返回false
exec(RegExp.prototype.exec(str))方法
使用正则表达式模式对字符串执行搜索,并将更新全局的RegExp对象的属性(lastIndex)以反映匹配结果,如果没有匹配的文本则返回null,否则返回一个结果数组
——index生命匹配文本的第一个字符 的位置
——input存放被检索的字符串string
- 非全局调用
调用非全局的RegExp对象的exec()时,返回数组
第一个元素是与正则表达式相匹配的文本
第二个元素是与RegExpObject的第一个子表达式相匹配分组的的文本(如果有分组的话)
第三个元素是与RegExpObject的第二个子表达式相匹配分组的的文本(如果有分组的话),以此类推

字符串对象方法
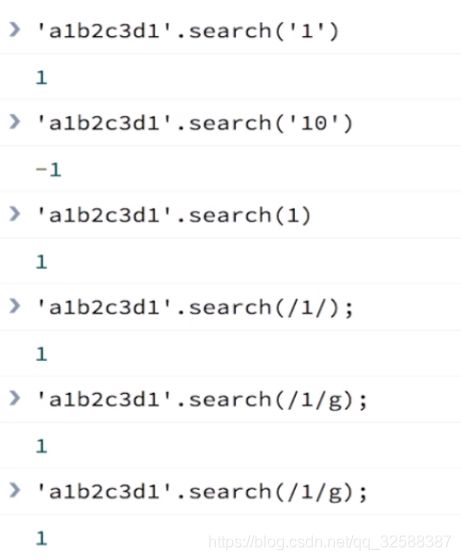
search()方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串
方法返回第一个匹配结果index,查找不到就返回-1
search()方法并不执行全局匹配,他将忽略g,并总是从字符串的开始进行检索
match()方法将检索字符串,以找到一个或多个与RegExp匹配的文本,RegExp是否有g对结果影响很大






